
本章描述了Linux内核如何维护其支持的文件系统中的文件。它描述了虚拟文件系统(VFS),并解释了如何支持Linux内核的真实文件系统。
本章描述了Linux内核如何维护其支持的文件系统中的文件。它描述了虚拟文件系统(VFS),并解释了如何支持Linux内核的真实文件系统。
Linux最重要的特性之一是它支持许多不同的文件系统。这使其非常灵活,并且能够与许多其他操作系统共存。 在撰写本文时,Linux支持15个文件系统;ext, ext2, xia, minix, umsdos, msdos, vfat, proc, smb, ncp, iso9660, sysv, hpfs, affs和ufs,毫无疑问,随着时间的推移,将会添加更多。
在Linux中,就像Unix TM一样,系统可能使用的单独文件系统不是通过设备标识符(例如驱动器号或驱动器名称)访问的,而是将它们组合成一个单一的层次结构树结构,该结构将文件系统表示为一个整体。 Linux会在挂载时将每个新文件系统添加到这个单一的文件系统树中。 所有文件系统,无论何种类型,都挂载到目录上,并且已挂载文件系统的文件会覆盖该目录的现有内容。 该目录称为挂载目录或挂载点。 卸载文件系统后,将再次显示挂载目录自己的文件。
初始化磁盘时(使用fdisk,例如),它们会施加一个分区结构,将物理磁盘划分为多个逻辑分区。 每个分区可以容纳一个文件系统,例如一个EXT2文件系统。 文件系统将文件组织成逻辑层次结构,目录、软链接等保存在物理设备上的块中。 可以包含文件系统的设备称为块设备。 IDE磁盘分区/dev/hda1,即系统中第一个IDE磁盘驱动器的第一个分区,是一个块设备。 Linux文件系统将这些块设备视为简单的块线性集合,它们不知道或不关心底层物理磁盘的几何形状。 每个块设备驱动程序的任务是将读取其设备的特定块的请求映射为对其设备有意义的术语; 硬盘的特定磁道、扇区和柱面(块存储在其中)。 无论什么设备持有文件系统,它都必须以相同的方式查看、感觉和操作。 此外,使用Linux的文件系统,这些不同的文件系统位于由不同硬件控制器控制的不同物理介质上并不重要(至少对系统用户而言)。 文件系统甚至可能不在本地系统上,它也可能是在网络链接上远程挂载的磁盘。 考虑以下示例,其中Linux系统将其根文件系统放在SCSI磁盘上
A E boot etc lib opt tmp usr C F cdrom fd proc root var sbin D bin dev home mnt lost+found
用户和程序本身都不需要知道/C实际上是一个挂载的VFAT文件系统,它位于系统中的第一个IDE磁盘上。 在示例中(实际上是我的家用Linux系统),/E是第二个IDE控制器上的主IDE磁盘。 第一个IDE控制器是PCI控制器,第二个是也控制IDE CDROM的ISA控制器也没有关系。 我可以使用调制解调器和PPP网络协议拨入我工作的网络,在这种情况下,我可以远程挂载我的Alpha AXP Linux系统的文件系统在/mnt/remote.
文件系统中的文件是数据的集合; 保存本章源文件的文件是一个名为filesystems.tex的ASCII文件。 文件系统不仅保存文件系统中包含的数据,还保存文件系统的结构。 它保存了Linux用户和进程看到的所有信息,例如文件,目录软链接,文件保护信息等。 此外,它必须安全可靠地保存该信息,操作系统的基本完整性取决于其文件系统。 没有人会使用随机丢失数据和文件的操作系统1。
Minix,Linux拥有的第一个文件系统,相当严格且性能不足。
它的文件名不能超过14个字符(仍然比8.3文件名更好),并且最大文件大小为64MBytes。 乍一看,64Mbytes可能看起来足够大,但是即使要保存适度的数据库,也需要较大的文件大小。 第一个专门为Linux设计的文件系统,扩展文件系统或EXT,于1992年4月推出,解决了许多问题,但仍然觉得缺乏性能。
因此,在1993年,添加了第二个扩展文件系统,或EXT2Ext2
。 本章稍后将详细介绍此文件系统。
当将EXT文件系统添加到Linux时,发生了一个重要的发展。 通过一个称为虚拟文件系统或VFS的接口层,将实际文件系统与操作系统和系统服务分开。
VFS允许Linux支持许多通常非常不同的文件系统,每个文件系统都向VFS提供一个通用的软件接口。 Linux文件系统的所有详细信息都由软件翻译,以便所有文件系统对Linux内核的其余部分和系统中运行的程序显示相同。 Linux的虚拟文件系统层允许您同时透明地挂载许多不同的文件系统。
Linux虚拟文件系统的实现方式是,使其文件的访问尽可能快和高效。 它还必须确保文件及其数据保持正确。 这两个要求可能会相互矛盾。 Linux VFS会在每次挂载和使用文件系统时,将信息从每个文件系统缓存在内存中。 必须小心正确地更新文件系统,因为会修改这些缓存中的数据,例如创建,写入和删除文件和目录。 如果您可以在正在运行的内核中查看文件系统的数据结构,则将能够看到文件系统正在读取和写入的数据块。 将创建和销毁描述正在访问的文件和目录的数据结构,并且设备驱动程序将一直在工作,获取和保存数据。 其中最重要的是缓冲区缓存,它已集成到各个文件系统访问其底层块设备的方式中。 访问块时,它们将放入缓冲区缓存中,并根据其状态保存在各种队列中。 缓冲区缓存不仅缓存数据缓冲区,还可以帮助管理与块设备驱动程序的异步接口。
第二个扩展文件系统(由RémyCard设计)被设计为Linux的可扩展且功能强大的文件系统。 它也是迄今为止Linux社区中最成功的文件系统,并且是当前所有Linux发行版的基础。
像许多文件系统一样,EXT2文件系统建立在以下前提之上:文件中保存的数据保存在数据块中。 这些数据块的长度都相同,并且尽管该长度在不同的EXT2文件系统之间可能会有所不同,但特定EXT2文件系统的块大小是在创建时设置的(使用mke2fs)。 每个文件的大小都向上舍入为整数个块。 如果块大小为1024字节,则1025字节的文件将占用两个1024字节的块。 不幸的是,这意味着平均每个文件浪费半个块。 通常,在计算中,您会用CPU的使用率来换取内存和磁盘空间利用率。 在这种情况下,Linux以及大多数操作系统都牺牲了相对低效的磁盘使用率,以减少CPU的工作量。 文件系统中并非所有块都保存数据,有些块必须用于包含描述文件系统结构的信息。 EXT2通过使用inode数据结构描述系统中的每个文件来定义文件系统拓扑。 inode描述了文件中的数据占用哪些块,以及文件的访问权限,文件的修改时间和文件的类型。 EXT2文件系统中的每个文件都由一个inode描述,并且每个inode都有一个唯一的编号来标识它。 文件系统的inode全部保存在inode表中。 EXT2目录只是特殊文件(本身由inode描述),其中包含指向其目录条目的inode的指针。
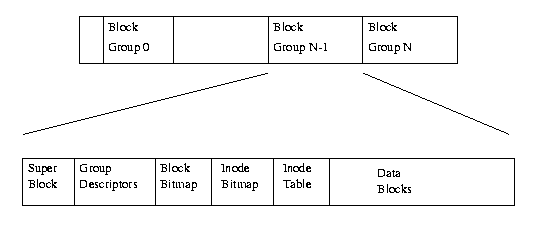
图 9.1显示了EXT2文件系统的布局,该布局占据了块结构设备中的一系列块。 就每个文件系统而言,块设备只是一系列可以读取和写入的块。 文件系统无需关心块应放置在物理介质上的位置,这是设备驱动程序的工作。 每当文件系统需要从包含它的块设备读取信息或数据时,它都会请求其支持的设备驱动程序读取整数个块。 EXT2文件系统将其占用的逻辑分区划分为块组。
每个组都会复制对文件系统完整性至关重要的信息,并在块中将真实文件和目录保存为信息和数据。 如果发生灾难并且需要恢复文件系统,则需要此复制。 以下小节更详细地描述了每个块组的内容。
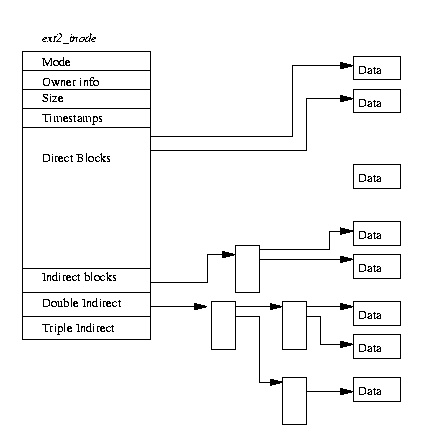
在EXT2文件系统中,inode是基本的构建块; 文件系统中的每个文件和目录都由一个且仅一个inode描述。 每个块组的EXT2 inode都保存在inode表中,并带有一个位图,该位图使系统可以跟踪已分配和未分配的inode。 图 9.2显示了EXT2 inode的格式,以及其他信息,它包含以下字段
您应该注意,EXT2 inode可以描述特殊的设备文件。 这些不是真实文件,而是程序可以用来访问设备的句柄。/dev中的所有设备文件都允许程序访问Linux的设备。 例如,mount程序将希望挂载的设备文件作为参数。
超级块包含对此文件系统的基本大小和形状的描述。 其中的信息使文件系统管理器可以使用和维护文件系统。 通常,挂载文件系统时仅读取块组0中的超级块,但是每个块组都包含一个重复的副本,以防止文件系统损坏。 除其他信息外,它还包含
每个块组都有一个描述它的数据结构。 与超级块一样,所有块组的所有组描述符都在每个块组中复制,以防文件系统损坏。
每个组描述符包含以下信息
组描述符一个接一个地放置,它们一起构成组描述符表。 每个块组都包含在其超级块副本之后的整个组描述符表。 只有第一个副本(在块组 0 中)实际被 EXT2 文件系统使用。 其他副本与超级块的副本一样,以防主副本损坏。
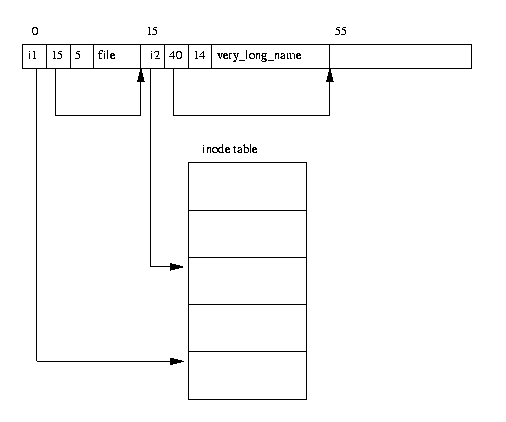
在 EXT2 文件系统中,目录是特殊文件,用于创建和保存对文件系统中文件的访问路径。图 9.3 显示了目录条目在内存中的布局。
目录文件是一个目录条目列表,每个条目包含以下信息
每个目录的前两个条目始终是标准的“.”和“..”条目,分别表示“此目录”和“父目录”。
我们需要的第一个 inode 是文件系统根目录的 inode,我们在文件系统的超级块中找到它的编号。 要读取 EXT2 inode,我们必须在相应块组的 inode 表中查找它。 例如,如果根 inode 编号为 42,那么我们需要块组 0 的 inode 表中的第 42 个 inode。根 inode 适用于 EXT2 目录,换句话说,根 inode 的模式将其描述为一个目录,它的数据块包含 EXT2 目录条目。
home只是众多目录条目之一,此目录条目为我们提供了描述/home目录的 inode 编号。 我们必须读取此目录(首先读取它的 inode,然后从其 inode 描述的数据块中读取目录条目)以找到rusling条目,该条目为我们提供了描述/home/rusling目录的 inode 编号。 最后,我们读取由描述/home/rusling目录的 inode 指向的目录条目,以找到.cshrc文件的 inode 编号,并由此我们获得包含文件中信息的数据块。
每当进程尝试将数据写入文件时,Linux 文件系统都会检查数据是否已超出文件最后一个已分配块的末尾。 如果是这样,那么它必须为此文件分配一个新的数据块。 在分配完成之前,该进程无法运行;它必须等待文件系统分配一个新的数据块并将剩余的数据写入其中,然后才能继续。 EXT2 块分配例程首先要做的是锁定此文件系统的 EXT2 超级块。 分配和取消分配会更改超级块中的字段,并且 Linux 文件系统不允许多个进程同时执行此操作。 如果另一个进程需要分配更多数据块,它将不得不等待此进程完成。 等待超级块的进程被挂起,无法运行,直到其当前用户放弃对超级块的控制。 对超级块的访问是按照先到先得的原则授予的,一旦一个进程控制了超级块,它就会保持控制直到完成。 锁定超级块后,该进程会检查此文件系统中是否有足够的空闲块。 如果没有足够的空闲块,那么此分配更多块的尝试将失败,并且该进程将放弃对此文件系统超级块的控制。
如果文件系统中有足够的空闲块,该进程会尝试分配一个。
如果 EXT2 文件系统已构建为预分配数据块,那么我们或许可以获取其中一个。 预分配的块实际上并不存在,它们只是在已分配的块位图中保留。 表示我们试图为其分配新数据块的文件的 VFS inode 有两个 EXT2 特定的字段,prealloc_block和prealloc_count,它们分别是第一个预分配数据块的块号以及它们的数量。 如果没有预分配的块或者未启用块预分配,则 EXT2 文件系统必须分配一个新块。 EXT2 文件系统首先查看文件中最后一个数据块之后的数据块是否空闲。 从逻辑上讲,这是最有效的分配块,因为它使顺序访问更快。 如果此块不空闲,则搜索范围扩大,它将在理想块的 64 个块内查找一个数据块。 尽管此块不是理想的,但至少相当接近并且与属于此文件的其他数据块位于同一块组中。
如果即使该块也不空闲,该进程将依次开始查找所有其他块组,直到找到一些空闲块。 块分配代码在其中一个块组中查找八个空闲数据块的群集。 如果找不到八个在一起的块,它会满足于更少的块。 如果需要并启用了块预分配,它将相应地更新prealloc_block和prealloc_count。
无论在哪里找到空闲块,块分配代码都会更新块组的块位图并在缓冲区缓存中分配一个数据缓冲区。 该数据缓冲区由文件系统的支持设备标识符和已分配块的块号唯一标识。 缓冲区中的数据被清零,缓冲区被标记为“脏”,以表明其内容尚未写入物理磁盘。 最后,超级块本身被标记为“脏”,以表明它已被更改并被解锁。 如果有任何进程在等待超级块,则队列中的第一个进程将被允许再次运行,并将获得对其文件操作的超级块的独占控制权。 该进程的数据被写入新的数据块,如果该数据块已满,则整个过程重复进行并分配另一个数据块。
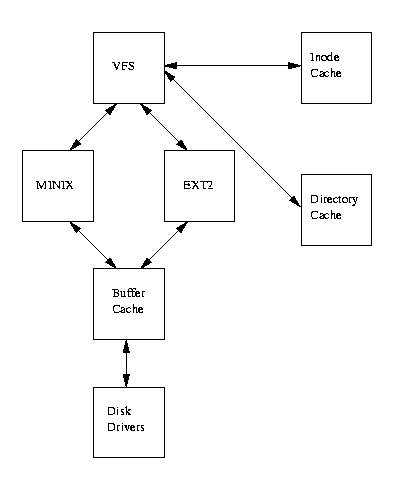
图 9.4 显示了 Linux 内核的虚拟文件系统与其真实文件系统之间的关系。 虚拟文件系统必须管理在任何给定时间挂载的所有不同文件系统。 为此,它维护描述整个(虚拟)文件系统和已挂载的真实文件系统的数据结构。
令人困惑的是,VFS 使用超级块和 inode 来描述系统的文件,这与 EXT2 文件系统使用超级块和 inode 的方式非常相似。 像 EXT2 inode 一样,VFS inode 描述系统中的文件和目录;虚拟文件系统的内容和拓扑结构。 从现在开始,为了避免混淆,我将编写关于 VFS inode 和 VFS 超级块的内容,以将它们与 EXT2 inode 和超级块区分开来。
当每个文件系统初始化时,它会在 VFS 中注册自己。 这发生在操作系统在系统启动时初始化自身时。 真实文件系统要么构建到内核本身中,要么构建为可加载模块。 文件系统模块是根据系统需要加载的,例如,如果VFAT如果文件系统是以内核模块的形式实现的,那么只有在挂载VFAT文件系统时才会加载它。当挂载基于块设备的文件系统时(包括根文件系统),VFS必须读取其超级块。每种文件系统类型的超级块读取例程都必须计算出文件系统的拓扑结构,并将该信息映射到VFS超级块数据结构上。VFS保存系统中已挂载文件系统的列表,以及它们的VFS超级块。每个VFS超级块都包含信息和指向执行特定功能的例程的指针。例如,表示已挂载的EXT2文件系统的超级块包含指向EXT2特定的inode读取例程的指针。这个EXT2 inode读取例程,像所有文件系统特定的inode读取例程一样,填充VFS inode中的字段。每个VFS超级块都包含指向文件系统上第一个VFS inode的指针。对于根文件系统,这是表示``/''目录的inode。这种信息映射对于EXT2文件系统来说非常高效,但对于其他文件系统来说效率略低。
当系统的进程访问目录和文件时,会调用遍历系统中VFS inode的系统例程。
例如,输入ls对于目录,或者cat对于文件,会导致虚拟文件系统搜索表示文件系统的VFS inode。由于系统上的每个文件和目录都由一个VFS inode表示,因此许多inode会被重复访问。这些inode保存在inode缓存中,这使得访问它们更快。如果inode不在inode缓存中,则必须调用文件系统特定的例程才能读取相应的inode。读取inode的操作会导致它被放入inode缓存中,并且进一步访问该inode会将其保留在缓存中。较少使用的VFS inode会从缓存中删除。
所有Linux文件系统都使用公共缓冲区缓存来缓存来自底层设备的数据缓冲区,以帮助加快所有文件系统访问物理设备的速度。
此缓冲区缓存独立于文件系统,并集成到Linux内核用于分配、读取和写入数据缓冲区的机制中。它具有明显的优势,即Linux文件系统独立于底层介质和支持它们的设备驱动程序。所有块结构设备都向Linux内核注册自身,并提供统一的、基于块的、通常是异步的接口。即使是相对复杂的块设备(如SCSI设备)也是如此。当实际文件系统从底层物理磁盘读取数据时,这会导致向块设备驱动程序发出请求,以从它们控制的设备读取物理块。缓冲区缓存集成到此块设备接口中。当文件系统读取块时,它们会保存在由所有文件系统和Linux内核共享的全局缓冲区缓存中。其中的缓冲区通过其块号和读取它的设备的唯一标识符来识别。因此,如果经常需要相同的数据,则会从缓冲区缓存中检索,而不是从磁盘读取,这会花费更长的时间。某些设备支持预读,其中会推测性地读取数据块,以防需要它们。
VFS还保留一个目录查找缓存,以便可以快速找到常用目录的inode。
作为一个实验,尝试列出一个你最近没有列出的目录。第一次列出它时,你可能会注意到一个短暂的停顿,但第二次列出其内容时,结果是立即的。目录缓存不存储目录本身的inode;这些应该在inode缓存中,目录缓存只是存储完整的目录名称及其inode号之间的映射。
每个已挂载的文件系统都由一个VFS超级块表示;在其他信息中,VFS超级块包含
与EXT2文件系统一样,VFS中的每个文件、目录等都由一个且只有一个VFS inode表示。
每个VFS inode中的信息由文件系统特定的例程从底层文件系统中的信息构建。VFS inode仅存在于内核的内存中,并保存在VFS inode缓存中,只要它们对系统有用。除其他信息外,VFS inode包含以下字段
构建Linux内核时,系统会询问您是否需要支持的每个文件系统。构建内核后,文件系统启动代码包含对所有内置文件系统的初始化例程的调用。
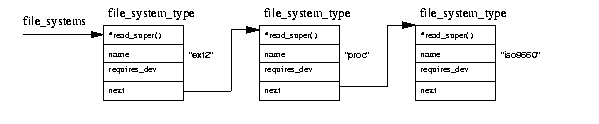
Linux文件系统也可以构建为模块,在这种情况下,它们可以根据需要按需加载,也可以使用insmod手动加载。每当加载文件系统模块时,它都会向内核注册自身,并在卸载时注销自身。每个文件系统的初始化例程都会向虚拟文件系统注册自身,并由一个file_system_type数据结构表示,该结构包含文件系统的名称和指向其VFS超级块读取例程的指针。图 9.5显示file_system_type数据结构被放入由file_systems指针指向的列表中。每个file_system_type数据结构包含以下信息
您可以通过查看/proc/filesystems来查看已注册的文件系统。例如
ext2
nodev proc
iso9660
当超级用户尝试挂载文件系统时,Linux内核必须首先验证在系统调用中传递的参数。虽然mount会进行一些基本检查,但它不知道此内核已构建为支持哪些文件系统,或者建议的挂载点是否实际存在。考虑以下mount命令
$ mount -t iso9660 -o ro /dev/cdrom /mnt/cdrom
此mount命令将向内核传递三个信息:文件系统的名称、包含文件系统的物理块设备,以及新文件系统将挂载在现有文件系统拓扑中的位置。
虚拟文件系统必须做的第一件事是找到文件系统。
为此,它通过查看指向file_system_type的列表中每个file_systems.
数据结构来搜索已知文件系统的列表。如果找到匹配的名称,它现在知道此内核支持此文件系统类型,并且它具有用于读取此文件系统的超级块的文件系统特定例程的地址。如果找不到匹配的文件系统名称,那么如果内核被构建为按需加载内核模块(请参见第 modules-chapter章),则一切都不会丢失。在这种情况下,内核将请求内核守护程序加载适当的文件系统模块,然后再像以前一样继续。
接下来,如果传递的物理设备mount尚未挂载,则必须找到要作为新文件系统的挂载点的目录的VFS inode。此VFS inode可能在inode缓存中,或者可能必须从支持挂载点文件系统的块设备中读取。一旦找到inode,就会检查以确保它是一个目录,并且没有其他文件系统已挂载在那里。同一个目录不能用作多个文件系统的挂载点。
此时,VFS挂载代码必须分配一个VFS超级块,并将挂载信息传递给此文件系统的超级块读取例程。所有系统的VFS超级块都保存在super_blocks的super_block数据结构,并且必须为此挂载分配一个。超级块读取例程必须根据它从物理设备读取的信息填写 VFS 超级块字段。对于 EXT2 文件系统,这种信息映射或转换非常简单,它只需读取 EXT2 超级块并从那里填写 VFS 超级块。对于其他文件系统,例如 MS DOS 文件系统,它并非如此简单。无论何种文件系统,填写 VFS 超级块意味着文件系统必须从支持它的块设备读取描述它的任何内容。如果无法从块设备读取或它不包含此类文件系统,则mount命令将失败。
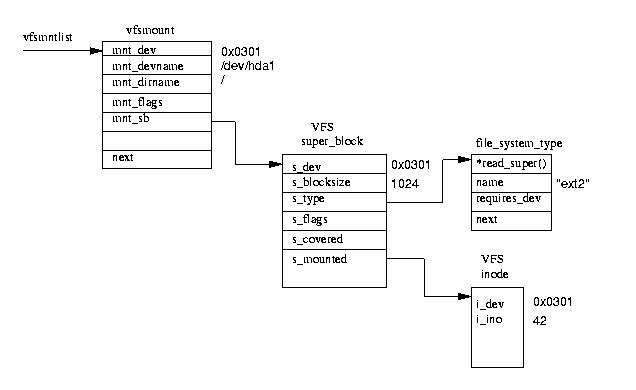
每个已挂载的文件系统都由一个vfsmount数据结构描述;参见图 9.6。这些数据结构在由vfsmntlist.
指向的列表上排队。另一个指针,vfsmnttail指向列表中的最后一个条目,并且mru_vfsmntvfsmount指针指向最近使用的文件系统。每个file_system_type结构包含保存文件系统的块设备的设备号,此文件系统的挂载目录以及指向挂载此文件系统时分配的 VFS 超级块的指针。反过来,VFS 超级块指向此类文件系统的数据结构以及此文件系统的根 inode。只要此文件系统已加载,此 inode 就会一直驻留在 VFS inode 缓存中。
要在虚拟文件系统中查找文件的 VFS inode,VFS 必须一次解析一个目录的名称,查找表示名称中每个中间目录的 VFS inode。每个目录查找都涉及调用文件系统特定的查找,该查找的地址保存在表示父目录的 VFS inode 中。这是可行的,因为我们始终拥有每个文件系统的根目录的 VFS inode,并由该系统的 VFS 超级块指向。每次真实文件系统查找 inode 时,它都会检查目录缓存中的目录。如果目录缓存中没有条目,则真实文件系统会从底层文件系统或 inode 缓存中获取 VFS inode。
我的 MG 的车间手册通常将组装描述为拆卸的反面,而卸载文件系统或多或少也是如此。
如果系统中的某些内容正在使用其文件之一,则无法卸载文件系统。因此,例如,如果进程正在使用该目录或其任何子目录,则无法卸载/mnt/cdrom。如果要卸载的文件系统正在被使用,则 VFS inode 缓存中可能存在来自该文件系统的 VFS inode,并且代码通过查找 inode 列表来检查这一点,以查找此文件系统占用的设备拥有的 inode。如果已挂载文件系统的 VFS 超级块已更改(即已被修改),则必须将其写回磁盘上的文件系统。一旦它被写入磁盘,VFS 超级块占用的内存将返回到内核的空闲内存池。最后,此挂载的vfsmount数据结构将从vfsmntlist中取消链接并释放。
当浏览已挂载的文件系统时,它们的 VFS inode 会不断被读取,在某些情况下,还会被写入。虚拟文件系统维护一个 inode 缓存,以加快对所有已挂载文件系统的访问。每次从 inode 缓存读取 VFS inode 时,系统都会节省对物理设备的访问。
VFS inode 缓存实现为一个哈希表,其条目是指向具有相同哈希值的 VFS inode 列表的指针。inode 的哈希值是根据其 inode 编号和包含文件系统的底层物理设备的设备标识符计算得出的。每当虚拟文件系统需要访问 inode 时,它首先在 VFS inode 缓存中查找。要在缓存中查找 inode,系统首先计算其哈希值,然后将其用作 inode 哈希表的索引。这为它提供了一个指向具有相同哈希值的 inode 列表的指针。然后,它依次读取每个 inode,直到找到一个 inode 编号和设备标识符与它正在搜索的 inode 相同。
如果它可以在缓存中找到 inode,则其计数会递增以表明它有另一个用户,并且文件系统访问继续。否则,必须找到一个空闲的 VFS inode,以便文件系统可以从内存中读取 inode。VFS 有很多关于如何获取空闲 inode 的选择。如果系统可以分配更多的 VFS inode,那么它会这样做;它分配内核页面并将它们分解为新的、空闲的 inode,并将它们放入 inode 列表中。系统的所有 VFS inode 都在由first_inode指向的列表以及 inode 哈希表中。如果系统已经拥有它被允许拥有的所有 inode,它必须找到一个适合重用的 inode。好的候选者是使用计数为零的 inode;这表明系统当前未使用它们。真正重要的 VFS inode,例如文件系统的根 inode,始终具有大于零的使用计数,因此永远不会成为重用的候选者。一旦找到重用的候选者,它就会被清理。VFS inode 可能是已更改的,在这种情况下,它需要写回到文件系统,或者它可能被锁定,在这种情况下,系统必须等待它被解锁才能继续。候选 VFS inode 必须在重用之前清理干净。
无论如何找到新的 VFS inode,都必须调用文件系统特定的例程,以从从底层真实文件系统读取的信息中填写它。在填写时,新的 VFS inode 的使用计数为 1 并且被锁定,因此在它包含有效信息之前,没有其他任何内容可以访问它。
要获得实际需要的 VFS inode,文件系统可能需要访问其他几个 inode。当您读取目录时会发生这种情况;只需要最终目录的 inode,但也必须读取中间目录的 inode。随着 VFS inode 缓存的使用和填充,使用较少的 inode 将被丢弃,而使用较多的 inode 将保留在缓存中。
为了加快对常用目录的访问,VFS 维护目录条目的缓存。
当真实文件系统查找目录时,它们的详细信息会被添加到目录缓存中。下次查找同一个目录时,例如列出它或打开其中的文件,它将在目录缓存中找到。只有短目录条目(最多 15 个字符长)会被缓存,但这很合理,因为较短的目录名称是最常用的名称。例如,/usr/X11R6/bin在 X 服务器运行时非常常见地被访问。
目录缓存由哈希表组成,哈希表的每个条目都指向具有相同哈希值的目录缓存条目的列表。哈希函数使用保存文件系统的设备的设备号和目录的名称来计算哈希表的偏移量或索引。它允许快速找到缓存的目录条目。当缓存中的查找花费太长时间才能找到条目时,甚至找不到它们时,拥有缓存是没有用的。
为了使缓存保持有效和最新,VFS 保留最近最少使用 (LRU) 目录缓存条目的列表。当目录条目第一次放入缓存时,也就是第一次查找时,它会被添加到第一级 LRU 列表的末尾。在完整的缓存中,这将取代 LRU 列表前面的现有条目。当再次访问目录条目时,它会被提升到第二个 LRU 缓存列表的末尾。同样,这可能会取代二级 LRU 缓存列表前面的缓存二级目录条目。在列表前面替换条目是可以接受的。条目位于列表前面的唯一原因是它们最近没有被访问。如果他们有,他们会更靠近列表的后面。二级 LRU 缓存列表中的条目比一级 LRU 缓存列表中的条目更安全。这是意图,因为这些条目不仅被查找过,而且还被重复引用过。
复习笔记 我们需要一个图表吗?
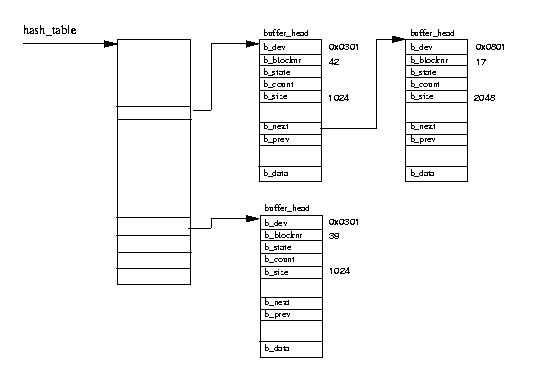
当使用已挂载的文件系统时,它们会生成大量读取和写入数据块到块设备的请求。所有块数据读取和写入请求都以buffer_head数据结构的形式通过标准内核例程调用提供给设备驱动程序。这些提供了块设备驱动程序需要的所有信息;设备标识符唯一地标识设备,块号告诉驱动程序要读取哪个块。所有块设备都被视为相同大小的块的线性集合。为了加快对物理块设备的访问,Linux 维护了一个块缓冲区缓存。系统中的所有块缓冲区都保存在此缓冲区缓存中的某个位置,甚至是新的、未使用的缓冲区。此缓存在所有物理块设备之间共享;在任何时候,缓存中都有许多块缓冲区,这些缓冲区属于系统的任何一个块设备,并且通常处于许多不同的状态。如果可以从缓冲区缓存中获得有效数据,这将为系统节省对物理设备的访问。任何已用于从块设备读取数据或向其写入数据的块缓冲区都会进入缓冲区缓存。随着时间的推移,它可能会从缓存中删除,以便为更值得的缓冲区让路,或者它可能会因为经常被访问而保留在缓存中。
缓存中的块缓冲区通过拥有设备标识符和缓冲区的块号来唯一标识。缓冲区缓存由两个功能部分组成。第一部分是空闲块缓冲区的列表。每个支持的缓冲区大小都有一个列表,系统的空闲块缓冲区在首次创建或被丢弃时会被排队到这些列表中。目前支持的缓冲区大小为 512、1024、2048、4096 和 8192 字节。第二个功能部分是缓存本身。这是一个哈希表,它是一个指向具有相同哈希索引的缓冲区链的指针向量。哈希索引由拥有设备标识符和数据块的块号生成。图 9.7 显示了哈希表以及一些条目。块缓冲区要么位于空闲列表之一中,要么位于缓冲区缓存中。当它们位于缓冲区缓存中时,它们也会被排队到最近最少使用 (LRU) 列表中。每种缓冲区类型都有一个 LRU 列表,系统使用这些列表来对某种类型的缓冲区执行操作,例如,将包含新数据的缓冲区写入磁盘。缓冲区的类型反映了其状态,Linux 目前支持以下类型:
每当文件系统需要从其底层物理设备读取缓冲区时,它会尝试从缓冲区缓存中获取一个块。如果它无法从缓冲区缓存中获取缓冲区,那么它将从相应大小的空闲列表中获取一个干净的缓冲区,并且这个新缓冲区将进入缓冲区缓存。如果它需要的缓冲区在缓冲区缓存中,那么它可能是最新的,也可能不是最新的。如果它不是最新的,或者它是一个新的块缓冲区,文件系统必须请求设备驱动程序从磁盘读取相应的数据块。
像所有缓存一样,必须维护缓冲区缓存,以便它高效运行,并在使用缓冲区缓存的块设备之间公平地分配缓存条目。Linux 使用bdflush
内核守护进程在缓存上执行许多管理任务,但有些任务会由于缓存被使用而自动发生。
“bdflush内核守护进程是一个简单的内核守护进程,它对系统具有过多脏缓冲区做出动态响应;这些缓冲区包含必须在某个时间写入磁盘的数据。它在系统启动时作为内核线程启动,并且相当令人困惑的是,它称自己为“kflushd”,如果您使用ps命令来显示系统中的进程,您会看到这个名称。通常,此守护进程会休眠,等待系统中脏缓冲区的数量变得太大。当分配和丢弃缓冲区时,会检查系统中脏缓冲区的数量。如果占系统中缓冲区总数的百分比过高,则bdflush会被唤醒。默认阈值为 60%,但是,如果系统迫切需要缓冲区,则bdflush无论如何都会被唤醒。可以使用update命令
# update -d bdflush version 1.4 0: 60 Max fraction of LRU list to examine for dirty blocks 1: 500 Max number of dirty blocks to write each time bdflush activated 2: 64 Num of clean buffers to be loaded onto free list by refill_freelist 3: 256 Dirty block threshold for activating bdflush in refill_freelist 4: 15 Percentage of cache to scan for free clusters 5: 3000 Time for data buffers to age before flushing 6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing 7: 1884 Time buffer cache load average constant 8: 2 LAV ratio (used to determine threshold for buffer fratricide).
所有的脏缓冲区都链接到BUF_DIRTYLRU 列表,每当通过将数据写入到它们而使其变脏时,bdflush会尝试将合理数量的脏缓冲区写入到其拥有的磁盘。同样,这个数字可以通过update命令来查看和控制,默认值为 500(参见上文)。
“update命令不仅仅是一个命令;它也是一个守护进程。以超级用户身份运行(在系统初始化期间)时,它会定期将所有较旧的脏缓冲区刷新到磁盘。它通过调用一个系统服务例程来做到这一点,该例程
执行与bdflush几乎相同的事情。每当完成一个脏缓冲区时,它会被标记上系统时间,该时间是它应该写入到其拥有的磁盘的时间。每次update运行时,它都会查看系统中的所有脏缓冲区,查找那些刷新时间已过期的缓冲区。每个过期的缓冲区都会被写入磁盘。
“/proc/proc 文件系统真正展示了 Linux 虚拟文件系统的强大功能。它实际上并不存在(Linux 的另一个魔术),无论是/proc目录还是其子目录及其文件实际上都不存在。那么你如何才能cat /proc/devices呢?/proc 文件系统像一个真正的文件系统一样,向虚拟文件系统注册自己。但是,当 VFS 调用它请求 inode 作为其文件和目录被打开时,/proc文件系统会根据内核中的信息创建这些文件和目录。例如,内核的/proc/devices文件是从内核描述其设备的数据结构生成的。
“/proc文件系统为用户提供了一个可读的窗口,可以了解内核的内部运作。几个 Linux 子系统,例如 chapter modules-chapter 中描述的 Linux 内核模块,会在/proc文件系统中创建条目。
像所有版本的 Unix TM 一样,Linux 将其硬件设备表示为特殊文件。因此,例如,/dev/null 是空设备。设备文件不使用文件系统中的任何数据空间,它只是设备驱动程序的访问点。EXT2 文件系统和 Linux VFS 都将设备文件实现为特殊类型的 inode。有两种类型的设备文件;字符和块特殊文件。在内核本身中,设备驱动程序实现了文件语义:您可以打开它们,关闭它们等等。字符设备允许在字符模式下进行 I/O 操作,而块设备要求所有 I/O 都通过缓冲区缓存进行。当向设备文件发出 I/O 请求时,它会被转发到系统中的相应设备驱动程序。通常这不是一个真正的设备驱动程序,而是一个用于某些子系统的伪设备驱动程序,例如 SCSI 设备驱动程序层。设备文件由主设备号(标识设备类型)和次设备号(标识该主类型的单元或实例)引用。例如,系统上第一个 IDE 控制器上的 IDE 磁盘的主设备号为 3,而 IDE 磁盘的第一个分区将具有次设备号 1。所以,ls -lof/dev/hda1gives
$ brw-rw---- 1 root disk 3, 1 Nov 24 15:09 /dev/hda1在内核中,每个设备都由一个唯一的kdev_t数据类型来描述,它长两个字节,第一个字节包含次设备号,第二个字节包含主设备号。
上面的 IDE 设备在内核中保存为 0x0301。表示块设备或字符设备的 EXT2 inode 将设备的设备号保存在其第一个直接块指针中。当 VFS 读取它时,表示它的 VFS inode 数据结构的i_rdev字段设置为正确的设备标识符。
1 嗯,不是故意,尽管我曾经被操作系统中的律师数量多于 Linux 开发人员的数量所困扰