6. 无类别队列规定 (qdiscs)
这些队列规定中的每一个都可以用作接口上的主要 qdisc,或者可以用在有类别队列规定的叶子类中。 这些是在 Linux 下使用的基本调度器。 请注意,默认调度器是 pfifo_fast。
6.1. FIFO,先进先出 (pfifo和bfifo)
 | 这不是 Linux 接口上的默认 qdisc。 请务必查看 第 6.2 节,以获取有关默认 (pfifo_fast) qdisc 的完整详细信息。 |
FIFO 算法构成了所有 Linux 网络接口上默认 qdisc (pfifo_fast) 的基础。 它不执行数据包的整形或重新排列。 它只是在接收和排队数据包后尽快传输数据包。 这也是所有新创建的类中使用的 qdisc,直到另一个 qdisc 或类替换 FIFO。
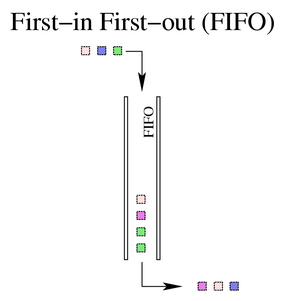
然而,真正的 FIFO qdisc 必须具有大小限制(缓冲区大小),以防止在无法像接收数据包一样快速地将数据包出队的情况下溢出。 Linux 实现了两个基本的 FIFO qdisc,一个基于字节,另一个基于数据包。 无论使用哪种类型的 FIFO,队列的大小都由参数定义limit。 对于pfifo单位被理解为数据包,对于bfifo单位被理解为字节。
示例 6. 指定一个limit用于数据包或字节 FIFO
[root@leander]# cat bfifo.tcc
/*
* make a FIFO on eth0 with 10kbyte queue size
*
*/
dev eth0 {
egress {
fifo (limit 10kB );
}
}
[root@leander]# tcc < bfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 bfifo limit 10240
[root@leander]# cat pfifo.tcc
/*
* make a FIFO on eth0 with 30 packet queue size
*
*/
dev eth0 {
egress {
fifo (limit 30p );
}
}
[root@leander]# tcc < pfifo.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 pfifo limit 30
|
6.2. pfifo_fast,默认的 Linux qdisc
所述pfifo_fastqdisc 是 Linux 下所有接口的默认 qdisc。 基于传统的 FIFO qdisc,此 qdisc 还提供了一些优先级划分。 它提供了三个不同的频带(单独的 FIFO)用于分离流量。 最高优先级流量(交互式流)被放置在频带 0 中,并且始终首先得到服务。 类似地,在频带 2 出队之前,频带 1 总是被清空待处理的数据包。
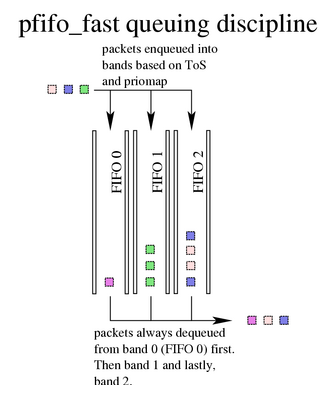
关于pfifo_fastqdisc,最终用户没有什么可配置的。 有关priomap和 ToS 位的使用的确切详细信息,请参阅 LARTC HOWTO 的 pfifo-fast 部分。
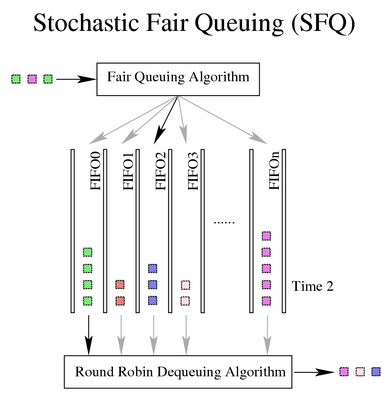
6.3. SFQ,随机公平队列
SFQ qdisc 尝试在任意数量的流之间公平地分配向网络传输数据的机会。 它通过使用哈希函数将流量分离到单独的(内部维护的)FIFO 中来实现这一点,这些 FIFO 以循环方式出队。 由于哈希函数的选择中可能存在不公平性,因此此函数会定期更改。 扰动(参数perturb)设置此周期性。
示例 7. 创建一个 SFQ
[root@leander]# cat sfq.tcc
/*
* make an SFQ on eth0 with a 10 second perturbation
*
*/
dev eth0 {
egress {
sfq( perturb 10s );
}
}
[root@leander]# tcc < sfq.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 sfq perturb 10
|
不幸的是,一些聪明的软件(例如 Kazaa 和 eMule 等)通过打开尽可能多的 TCP 会话(流)来消除这种公平队列尝试的好处。 在许多网络中,对于行为良好的用户,SFQ 可以充分地将网络资源分配给竞争流,但是当讨厌的应用程序侵入网络时,可能需要采取其他措施。
另请参阅 第 6.4 节,了解具有更多暴露参数供用户操作的 SFQ qdisc。
6.4. ESFQ,扩展随机公平队列
从概念上讲,此 qdisc 与 SFQ 没有什么不同,尽管它允许用户控制比其更简单的同类产品更多的参数。 构思此 qdisc 是为了克服上面确定的 SFQ 的缺点。 通过允许用户控制哪个哈希算法用于分配对网络带宽的访问,用户可以实现更公平的真实带宽分配。
示例 8. ESFQ 用法
Usage: ... esfq [ perturb SECS ] [ quantum BYTES ] [ depth FLOWS ]
[ divisor HASHBITS ] [ limit PKTS ] [ hash HASHTYPE]
Where:
HASHTYPE := { classic | src | dst }
|
待定; 需要在此处的实践经验和/或证明。
6.5. GRED,通用随机早期丢弃
待定; 我从未使用过这个。 需要实践经验或证明。
理论声明,RED 算法在骨干网或核心网络上很有用,但在最终用户附近不太有用。 请参阅关于流的部分,以查看关于 TCP 渴求性的一般讨论。
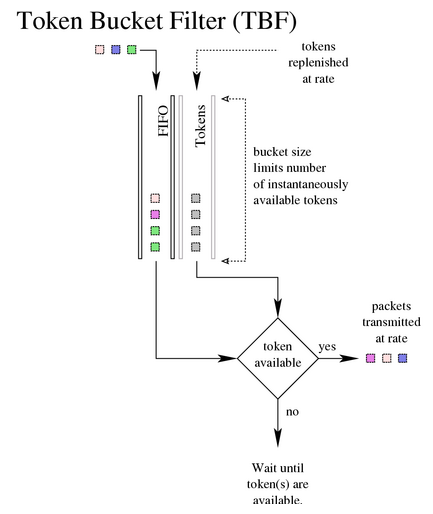
6.6. TBF,令牌桶过滤器
此 qdisc 构建于令牌和桶之上。 它只是对接口上发送的流量进行整形。 为了限制数据包从特定接口出队的速度,TBF qdisc 是完美的解决方案。 它只是将发送的流量减慢到指定速率。
只有当有足够的令牌可用时,数据包才会被传输。 否则,数据包将被延迟。 以这种方式延迟数据包将在数据包的往返时间中引入人为的延迟。
示例 9. 创建一个 256kbit/s TBF
[root@leander]# cat tbf.tcc
/*
* make a 256kbit/s TBF on eth0
*
*/
dev eth0 {
egress {
tbf( rate 256 kbps, burst 20 kB, limit 20 kB, mtu 1514 B );
}
}
[root@leander]# tcc < tbf.tcc
# ================================ Device eth0 ================================
tc qdisc add dev eth0 handle 1:0 root dsmark indices 1 default_index 0
tc qdisc add dev eth0 handle 2:0 parent 1:0 tbf burst 20480 limit 20480 mtu 1514 rate 32000bps
|