Linux 系统管理员指南
版本 0.9
Lars Wirzenius
Joanna Oja
Stephen Stafford
Alex Weeks
版权所有 1993--1998 Lars Wirzenius。
版权所有 1998--2001 Joanna Oja。
版权所有 2001--2003 Stephen Stafford。
版权所有 2003--2004 Stephen Stafford & Alex Weeks。
版权所有 2004--至今 Alex Weeks。
商标归其所有者所有。
允许根据自由软件基金会发布的 GNU 自由文档许可证 1.2 版或任何更高版本复制、分发和/或修改本文档;没有不变部分、没有封面文本和没有封底文本。许可证副本包含在题为“GNU 自由文档许可证”的部分中。
- 目录
- 关于本书
- 1. 致谢
- 2. 修订历史
- 3. 提供的源代码和预格式化版本
- 4. 排版约定
- 1. 介绍
- 1.1. Linux 还是 GNU/Linux,这是个问题。
- 1.2. 商标
- 2. Linux 系统概述
- 2.1. 操作系统的各个部分
- 2.2. 内核的重要部分
- 2.3. UNIX 系统中的主要服务
- 3. 目录树概述
- 3.1. 背景
- 3.2. 根文件系统
- 3.3. /etc 目录
- 3.4. /dev 目录
- 3.5. /usr 文件系统。
- 3.6. /var 文件系统
- 3.7. /proc 文件系统
- 4. 硬件、设备和工具
- 5. 使用磁盘和其他存储介质
- 6. 内存管理
- 7. 系统监控
- 8. 启动和关闭
- 9. init
- 9.1. init 首先运行
- 9.2. 配置 init 以启动 getty:/etc/inittab 文件
- 9.3. 运行级别
- 9.4. /etc/inittab 中的特殊配置
- 9.5. 以单用户模式启动
- 10. 登录和注销
- 11. 管理用户帐户
- 12. 备份
- 13. 任务自动化 -- 待添加
- 14. 保持时间同步
- 14.1. 本地时间的概念
- 14.2. 硬件时钟和软件时钟
- 14.3. 显示和设置时间
- 14.4. 当时间不正确时
- 14.5. NTP - 网络时间协议
- 14.6. 基本 NTP 配置
- 14.7. NTP 工具包
- 14.8. 一些已知的 NTP 服务器
- 14.9. NTP 链接
- 15. 系统日志 -- 待添加
- 16. 系统更新 -- 待添加
- 17. Linux 内核源代码
- 18. 寻找帮助
- A. GNU 自由文档许可证
- 词汇表(草案,但希望不会持续太久)
- 索引-草案
- 表格列表
- 5-1. 比较文件系统特性
- 5-2. 大小
- 5-3. 我的分区
- 9-1. 运行级别编号
- 12-1. 使用多个备份级别的有效备份方案
- 图表列表
- 2-1. Linux 内核的一些更重要的部分
- 3-1. Unix 目录树的各个部分。虚线表示分区限制。
- 5-1. 硬盘的示意图。
- 5-2. 硬盘分区的示例。
- 5-3. 三个独立的文件系统。
- 5-4. /home 和 /usr 已被挂载。
- 10-1. 通过终端登录:init、getty、login 和 shell 的交互。
- 12-1. 多级备份计划的示例。
关于本书
"只有两件事是无限的:宇宙和人类的愚蠢,而且我不确定前者。" 阿尔伯特·爱因斯坦
1. 致谢
1.1. Joanna 的致谢
许多人直接或间接地帮助了我写这本书。我要特别感谢 Matt Welsh 的灵感和 LDP 领导,Andy Oram 让我再次工作并提供了非常有价值的反馈,Olaf Kirch 向我展示了它是可以完成的,以及 Yggdrasil 的 Adam Richter 和其他人向我展示了其他人也会觉得它很有趣。
Stephen Tweedie、H. Peter Anvin、Remy Card、Theodore Ts'o 和 Stephen Tweedie 让我借用了他们的作品(从而使这本书看起来更厚更令人印象深刻):xia 和 ext2 文件系统之间的比较、设备列表和 ext2 文件系统的描述。这些不再是本书的一部分。我对此非常感激,并对早期版本有时缺乏适当的署名表示歉意。
此外,我要感谢 Mark Komarinski 在 1993 年发送的资料以及 Linux Journal 中的许多系统管理专栏。它们非常有用且具有启发性。
许多有用的评论是由大量人发送的。我那微型黑洞般的档案库无法让我找到他们所有的名字,但其中一些人按字母顺序排列:Paul Caprioli、Ales Cepek、Marie-France Declerfayt、Dave Dobson、Olaf Flebbe、Helmut Geyer、Larry Greenfield 和他的父亲、Stephen Harris、Jyrki Havia、Jim Haynes、York Lam、Timothy Andrew Lister、Jim Lynch、Michael J. Micek、Jacob Navia、Dan Poirier、Daniel Quinlan、Jouni K Seppnen、Philippe Steindl、G.B. Stotte。我对任何我忘记的人表示歉意。
1.2. Stephen 的致谢
我要感谢 Lars 和 Joanna 为本指南所做的辛勤工作。
像这样的指南很可能至少存在一些细微的不准确之处。而且几乎肯定会有一些章节会不时过时。如果您发现任何这些问题,请发送电子邮件至我:<bagpuss@debian.org.NOSPAM>我几乎可以接受任何形式的输入(差异,纯文本,HTML,任何形式),我绝不反对允许其他人帮助我维护这样一部庞大的文本内容 :)
非常感谢 Helen Topping Shaw 拿出红笔,让文本比原本的更好。同样感谢她一直都很棒。
3. 源代码和预格式化版本可用
可以通过匿名 FTP 在 Linux 文档项目主页 http://www.tldp.org/ 或本书的主页 http://www.draxeman/sag.html 上找到本书的源代码和其他机器可读格式。本书至少提供 SGML 源代码以及 HTML 和 PDF 格式。 其他格式可能也可用。
4. 排版约定
在整本书中,我尝试使用统一的排版约定。 希望它们有助于提高可读性。 如果您可以提出任何改进建议,请联系我。
文件名表示为/usr/share/doc/foo.
命令名称表示为:fsck
电子邮件地址表示为<user@domain.com>
URL 表示为:http://www.tldp.org
我会在编辑时添加此部分。 如果您发现任何应该添加的内容,请告诉我。
第 1 章. 简介
“起初,地是空虚混沌,渊面黑暗; 神的灵运行在水面上。 神说,要有光,就有了光。”
《Linux 系统管理员指南》描述了使用 Linux 的系统管理方面。 它适用于对系统管理一无所知的人(那些说“这是什么?”的人),但他们至少已经掌握了正常使用的基础知识。 本手册不告诉您如何安装 Linux; 这在安装和入门文档中进行了描述。 有关 Linux 手册的更多信息,请参见下文。
系统管理涵盖了您必须执行的所有操作,以使计算机系统保持可用状态。 它包括诸如备份文件(并在必要时还原它们)、安装新程序、为用户创建帐户(并在不再需要时删除它们)、确保文件系统未损坏等等。 如果计算机比如说是一所房子,那么系统管理就被称为维护,并且包括清洁、修理破损的窗户和其他此类事情。
本手册的结构使得许多章节应该可以独立使用,因此,例如,如果您需要有关备份的信息,您可以只阅读该章节。 但是,本手册首先是一个教程,可以按顺序或整体阅读。
本手册不打算完全独立使用。 Linux 文档的其余部分对于系统管理员也非常重要。 毕竟,系统管理员只是具有特殊权限和职责的用户。 非常有用的资源是手册页,当您不熟悉某个命令时,应始终查阅它们。 如果您不知道需要哪个命令,则可以使用 apropos 命令。 查阅其手册页以获取更多详细信息。
虽然本手册的目标是 Linux,但一个普遍原则是它也应该适用于其他基于 UNIX 的操作系统。 不幸的是,由于 UNIX 的不同版本之间以及尤其是在系统管理方面存在很大差异,因此几乎没有希望涵盖所有变体。 由于 Linux 开发的性质,即使涵盖 Linux 的所有可能性也很困难。
没有一个官方的 Linux 发行版,因此不同的人有不同的设置,并且许多人都有自己建立的设置。 本书并非针对任何一个发行版。 发行版可能会有很大差异。 在可能的情况下,已注意到差异并给出了替代方案。 有关发行版及其一些差异的列表,请参见 http://en.wikipedia.org/wiki/Comparison_of_Linux_distributions。
在尝试描述事物的工作方式,而不仅仅是列出每个任务的“五个简单步骤”时,此处有很多信息对于每个人来说都不是必需的,但是这些部分已标记为这样,如果您使用预配置的系统,则可以跳过它们。 当然,阅读所有内容将增加您对系统的理解,并且应该使使用和管理它更有效率。
理解是 Linux 成功的关键。 这本书可以只提供配方,但是当您遇到这本书没有配方的问题时,您该怎么办? 如果这本书可以提供理解,那么就不需要配方了。 答案将是不言而喻的。
像所有其他与 Linux 相关的开发一样,编写本手册的工作是以志愿为基础完成的:我这样做是因为我认为这可能会很有趣,并且因为我觉得应该这样做。 但是,与所有志愿工作一样,人们的时间、知识和经验是有限的。 这意味着该手册不一定像一位巫师被高薪聘请编写并花费数千年时间来完善它一样好。 请注意。
一个特别需要注意的是,许多在其他免费提供的手册中已经有详细记录的事情在这里并不总是被涵盖。 这尤其适用于特定于程序的文档,例如使用 mkfs 的所有详细信息。 仅描述了该程序的用途以及本手册目的所需的使用方式。 有关更多信息,请查阅这些其他手册。 通常,所有引用的文档都是完整 Linux 文档集的一部分。
1.1. Linux 还是 GNU/Linux,这是个问题。
许多人认为 Linux 实际上应该被称为 GNU/Linux。 这是因为 Linux 只是内核,而不是在其上运行的应用程序。 大多数基本的命令行实用程序都是自由软件基金会在开发其 GNU 操作系统时编写的。 在这些实用程序中,有一些最基本的命令,如 cp、mv lsof 和 dd。
简而言之,发生的事情是,FSF 在内核之前通过编写编译器、C 库和基本命令行实用程序等内容来开始开发 GNU。 Linus Torvalds 通过首先编写 Linux 内核并使用为 GNU 编写的应用程序来启动 Linux。
我认为这不是辩论人们在提及 Linux 时应该使用什么名称的合适论坛。 我在这里提到它,是因为我认为重要的是要了解 GNU 和 Linux 之间的关系,并且还要解释为什么有时将某些 Linux 称为 GNU/Linux。 本文档将简单地将其称为 Linux。
GNU 对此问题的看法在其网站上讨论
关系 - https://gnu.ac.cn/gnu/linux-and-gnu.html
为什么 Linux 应该是 GNU/Linux - https://gnu.ac.cn/gnu/why-gnu-linux.html
GNU/Linux 常见问题解答 - https://gnu.ac.cn/gnu/gnu-linux-faq.html
以下是一些替代观点
http://librenix.com/?inode=2312
第 2 章. Linux 系统概述
“神看着一切所造的都甚好。” -- 圣经詹姆斯国王版本。 创世纪 1:31
本章概述了 Linux 系统。 首先,描述了操作系统提供的主要服务。 然后,以相当缺乏细节的方式描述了实现这些服务的程序。 本章的目的是使读者了解整个系统,以便在其他地方详细描述每个部分。
2.1. 操作系统的各个部分
UNIX 和“类 UNIX”操作系统(例如 Linux)由一个内核和一些系统程序组成。 还有一些用于完成工作的应用程序。 内核是操作系统的核心。 事实上,它经常被错误地认为是操作系统本身,但事实并非如此。 操作系统提供的服务比单纯的内核多得多。
它跟踪磁盘上的文件,启动程序并并发运行它们,为各种进程分配内存和其他资源,接收来自网络的包并向网络发送包,等等。 内核本身做的事情很少,但它提供了构建所有服务的工具。 它还阻止任何人直接访问硬件,迫使每个人都使用它提供的工具。 这样,内核就可以为用户提供一些相互保护。 通过系统调用使用内核提供的工具。 有关这些的更多信息,请参见手册页第 2 节。
系统程序使用内核提供的工具来实现操作系统所需的各种服务。 系统程序和所有其他程序都在内核之上运行,这被称为用户模式。 系统程序和应用程序之间的区别在于意图:应用程序旨在完成有用的事情(或者如果是游戏,则用于玩游戏),而系统程序是使系统正常工作所必需的。 文字处理器是一个应用程序; mount 是一个系统程序。 然而,这种差异通常有些模糊,仅对有强迫症的分类者才重要。
操作系统还可以包含编译器及其相应的库(特别是 Linux 下的 GCC 和 C 库),尽管并非所有编程语言都需要成为操作系统的一部分。 文档,有时甚至是游戏,也可以成为其中的一部分。 传统上,操作系统由安装磁带或磁盘的内容定义; 对于 Linux 来说,情况并非如此清楚,因为它遍布世界各地的 FTP 站点。
2.2. 内核的重要组成部分
Linux 内核由几个重要部分组成:进程管理、内存管理、硬件设备驱动程序、文件系统驱动程序、网络管理以及各种其他零碎的东西。 图 2-1 显示了其中的一些。
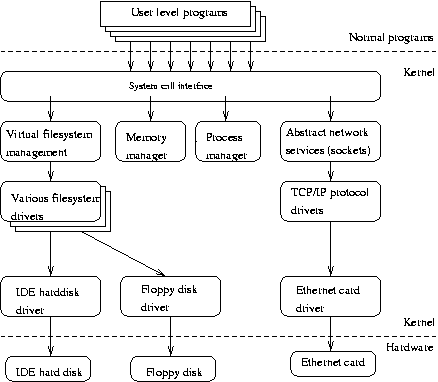
可能内核最重要的部分(没有它们,其他任何东西都无法工作)是内存管理和进程管理。 内存管理负责将内存区域和交换空间区域分配给进程、内核的一部分以及缓冲区缓存。 进程管理创建进程,并通过切换处理器上的活动进程来实现多任务处理。
在最低级别,内核包含每种它支持的硬件的硬件设备驱动程序。 由于世界上有各种各样的硬件,因此硬件设备驱动程序的数量很大。 通常有许多其他方面相似的硬件,但在软件控制方式上有所不同。 相似性使得拥有支持类似操作的通用驱动程序类成为可能; 类的每个成员都具有与内核其余部分相同的接口,但在实现它们方面需要做的事情有所不同。 例如,所有磁盘驱动程序对于内核的其余部分看起来都一样,也就是说,它们都具有诸如“初始化驱动器”、“读取扇区 N”和“写入扇区 N”之类的操作。
内核本身提供的一些软件服务具有类似的属性,因此可以抽象为类。 例如,各种网络协议已被抽象为一个编程接口,即 BSD socket 库。 另一个例子是虚拟文件系统 (VFS) 层,它将文件系统操作从它们的实现中抽象出来。 每种文件系统类型都提供每个文件系统操作的实现。 当某个实体尝试使用文件系统时,该请求通过 VFS,VFS 将请求路由到正确的文件系统驱动程序。
有关内核内部结构的更深入讨论,请访问 http://www.tldp.org/LDP/lki/index.html。 本文档是为 2.4 内核编写的。 当我找到 2.6 内核的文档时,我会在此处列出它。
2.3. UNIX 系统中的主要服务
本节介绍了一些更重要的 UNIX 服务,但没有太多细节。 它们将在后面的章节中更详细地描述。
2.3.1. init
UNIX 系统中最重要的服务是由init提供的。 init作为每个 UNIX 系统的第一个进程启动,这是内核在启动时做的最后一件事。 当init启动时,它会通过执行各种启动任务(检查和挂载文件系统,启动守护进程等)来继续启动过程。
init 执行的确切列表取决于它是哪种风格; 有几种可供选择。 init 通常提供单用户模式的概念,在这种模式下,没有人可以登录,并且 root 在控制台上使用 shell; 通常的模式称为多用户模式。 一些风格将其概括为运行级别; 单用户和多用户模式被认为是两个运行级别,并且还可以有其他运行级别,例如,在控制台上运行 X。
Linux 允许最多 10 个运行级别,0-9,但通常默认只定义其中一些。 运行级别 0 被定义为“系统停止”。 运行级别 1 被定义为“单用户模式”。 运行级别 3 被定义为“多用户”,因为它是系统在正常日常条件下启动的运行级别。 运行级别 5 通常与 3 相同,只是也会启动 GUI。 运行级别 6 被定义为“系统重启”。 其他运行级别取决于您的特定发行版如何定义它们,并且它们在发行版之间差异很大。 查看的内容/etc/inittab通常会给出一些提示,说明预定义的运行级别是什么以及它们被定义为什么。
在正常运行中,init 确保 getty 正常工作(以允许用户登录)并收养孤立进程(父进程已死的进程;在 UNIX 中所有进程必须在一棵树中,因此必须收养孤立进程)。
当系统关闭时,由 init 负责杀死所有其他进程,卸载所有文件系统并停止处理器,以及已配置要执行的任何其他操作。
2.3.2. 从终端登录
通过终端(通过串行线)和控制台(未运行 X 时)的登录由 getty 程序提供。 init 为允许登录的每个终端启动一个单独的 getty 实例。 getty 读取用户名并运行 login 程序,该程序读取密码。 如果用户名和密码正确,login 运行 shell。 当 shell 终止时,即用户注销时,或者当 login 由于用户名和密码不匹配而终止时,init 会注意到这一点并启动一个新的 getty 实例。 内核没有登录的概念,这些都由系统程序处理。
2.3.3. Syslog
内核和许多系统程序产生错误、警告和其他消息。 通常重要的是这些消息稍后可以查看,甚至更晚,因此应将它们写入文件。 执行此操作的程序是 syslog。 可以对其进行配置,以根据编写者或重要程度将消息排序到不同的文件中。 例如,内核消息通常与从其他消息分开的文件,因为内核消息通常更重要,并且需要定期读取以发现问题。
第 15 章 将提供更多相关信息。
2.3.4. 定期命令执行:cron 和 at
用户和系统管理员经常需要定期运行命令。 例如,系统管理员可能希望运行命令来清理具有临时文件的目录(/tmp和/var/tmp)中的旧文件,以防止磁盘被填满,因为并非所有程序都能正确清理自身。
cron 服务设置为执行此操作。 每个用户都可以有一个crontab文件,她在其中列出她希望执行的命令以及应该执行这些命令的时间。 cron 守护程序负责在指定时间启动命令。
at 服务类似于 cron,但它是一次性的:该命令在给定时间执行,但不会重复。
我们将在稍后对此进行更详细的介绍。 有关更深入的信息,请参见手册页 cron(1)、crontab(1)、crontab(5)、at(1) 和 atd(8)。
第 13 章 将介绍这一点。
2.3.5. 图形用户界面
UNIX 和 Linux 不会将用户界面集成到内核中; 而是让它由用户级别的程序实现。 这适用于文本模式和图形环境。
这种安排使系统更加灵活,但缺点是为每个程序实现不同的用户界面很简单,这使得系统更难学习。
Linux 主要使用的图形环境称为 X Window System(简称 X)。 X 也不实现用户界面; 它只实现一个窗口系统,即可以用来实现图形用户界面的工具。 一些流行的窗口管理器是:fvwm、icewm、blackbox 和 windowmaker。 还有两个流行的桌面管理器,KDE 和 Gnome。
2.3.6. 网络
网络是将两个或多个计算机连接起来,以便它们可以相互通信的行为。 连接和通信的实际方法有些复杂,但最终结果非常有用。
UNIX 操作系统具有许多网络功能。 大多数基本服务(文件系统、打印、备份等)都可以通过网络完成。 这可以简化系统管理,因为它允许集中管理,同时仍然可以获得微型计算和分布式计算的好处,例如更低的成本和更好的容错能力。
但是,本书仅简要介绍网络; 有关更多信息,包括网络如何运行的基本描述,请参见Linux Network Administrators' Guide http://www.tldp.org/LDP/nag2/index.html。
2.3.7. 网络登录
网络登录的工作方式与普通登录略有不同。 对于通过网络登录的每个人,都有一个单独的虚拟网络连接,并且可以根据可用带宽来设置任意数量的连接。 因此,不可能为每个可能的虚拟连接运行一个单独的 getty。 还有几种通过网络登录的不同方式,telnet 和 ssh 是 TCP/IP 网络中的主要方式。
现在,许多 Linux 系统管理员认为 telnet 和 rlogin 不安全,并且更喜欢 ssh,“安全 shell”,它加密通过网络传输的流量,从而大大降低了恶意用户“嗅探”您的连接并获取敏感数据(如用户名和密码)的可能性。 强烈建议您使用 ssh 而不是 telnet 或 rlogin。
网络登录没有一大群 getty,而是为每种登录方式都有一个守护程序(telnet 和 ssh 有单独的守护程序),它们监听所有传入的登录尝试。 当它注意到一个时,它会启动一个新的实例来处理该单个尝试; 原始实例继续监听其他尝试。 新实例的工作方式与 getty 类似。
2.3.8. 网络文件系统
网络服务最有用的功能之一就是通过网络文件系统共享文件。根据你的网络情况,这可以通过网络文件系统 (NFS) 或通用 Internet 文件系统 (CIFS) 来实现。 NFS 通常是基于“UNIX”的服务。 在 Linux 中,内核支持 NFS。 然而,CIFS 则不然。 在 Linux 中,CIFS 由 Samba 提供支持 http://www.samba.org。
使用网络文件系统,程序在一台机器上执行的任何文件操作都会通过网络发送到另一台计算机。 这会欺骗程序,使其认为另一台计算机上的所有文件实际上都位于运行该程序的计算机上。 这使得信息共享非常简单,因为它不需要修改程序。
这将在第 5.4 节中更详细地介绍。
2.3.9. 邮件
电子邮件是目前最流行的计算机通信方式。 电子信件以特殊格式存储在文件中,并使用专门的邮件程序来发送和阅读信件。
每个用户都有一个传入邮箱(一种特殊格式的文件),所有新邮件都存储在此处。 当有人发送邮件时,邮件程序会找到接收者的邮箱并将信件附加到邮箱文件中。 如果接收者的邮箱在另一台机器上,则该信件将发送到另一台机器,该机器会以其认为最合适的方式将其传递到邮箱。
邮件系统由许多程序组成。 将邮件传递到本地或远程邮箱由一个程序完成(邮件传输代理 (MTA),例如,sendmail 或 postfix),而用户使用的程序有很多种(邮件用户代理 (MUA),例如,pine 或 evolution。 邮箱通常存储在/var/spool/mail直到用户的 MUA 检索它们为止。
有关设置和运行邮件服务的更多信息,您可以阅读邮件管理员 HOWTO,网址为 http://www.tldp.org/HOWTO/Mail-Administrator-HOWTO.html,或访问 sendmail 或 postfix 的网站。 http://www.sendmail.org/,或 http://www.postfix.org/ 。
2.3.10. 打印
一次只能有一个人使用打印机,但是用户之间不共享打印机是不经济的。 因此,打印机由软件管理,该软件实现一个打印队列:所有打印作业都放入队列中,并且每当打印机完成一个作业时,下一个作业就会自动发送到打印机。 这使使用者免于组织打印队列和争夺打印机的控制权。 相反,他们在打印机处形成一个新队列,等待他们的打印输出,因为似乎没有人能够让队列软件准确地知道何时真正完成任何人的打印输出。 这极大地促进了办公室内部的社交关系。
打印队列软件还会将打印输出假脱机到磁盘上,也就是说,当作业在队列中时,文本会保存在文件中。 这允许应用程序程序将打印作业快速输出到打印队列软件; 应用程序不必等到实际打印作业才能继续。 这非常方便,因为它允许您打印出一个版本,而无需等待打印出来才能制作一个完全修改的新版本。
您可以参考位于 http://www.tldp.org/HOWTO/Printing-HOWTO/index.html 的 Printing-HOWTO,以获得有关设置打印机的更多帮助。
2.3.11. 文件系统布局
文件系统分为许多部分; 通常沿着根文件系统的思路/bin , /lib , /etc , /dev和其他一些;一个/usr带有程序和不变数据的文件系统;/var带有变化数据的文件系统(例如日志文件);以及一个/home供每个人使用的个人文件。 根据硬件配置和系统管理员的决策,划分可能有所不同; 甚至可以在一个文件系统中全部实现。
第 3 章详细介绍了一些文件系统布局; 文件系统层次标准 . 更详细地介绍了它。 这可以在网上找到: http://www.pathname.com/fhs/
第 3 章。目录树概述
"两天后,小熊维尼坐在树枝上,晃着腿,在他旁边放着四罐蜂蜜..." (A.A. Milne)
本章基于文件系统层次标准 介绍了标准 Linux 目录树的重要部分。 它概述了将目录树划分为具有不同用途的单独文件系统的通常方式,并给出了这种特定拆分的动机。 并非所有 Linux 发行版都完全遵循此标准,但它具有足够的通用性,可以为您提供概述。
3.1. 背景
本章主要基于文件系统层次标准 (FHS) 版本 2.1,该标准尝试为如何组织 Linux 系统中的目录树设置标准。 这样的标准具有以下优点:编写或移植 Linux 软件以及管理 Linux 机器将更容易,因为所有内容都应位于标准化位置。 该标准背后没有任何强制任何人遵守的权威机构,但它已获得许多 Linux 发行版的支持。 如果没有非常令人信服的理由,打破 FHS 不是一个好主意。 FHS 尝试遵循 Unix 传统和当前趋势,使 Linux 系统对具有其他 Unix 系统经验的人员来说很熟悉,反之亦然。
本章不如 FHS 详细。 系统管理员还应该阅读完整的 FHS 以获得完整的理解。
本章未详细解释所有文件。 目的不是描述每个文件,而是从文件系统的角度概述系统。 有关每个文件的更多信息可以在本手册或 Linux 手册页的其他位置找到。
完整的目录树旨在分解为更小的部分,每个部分都能够在自己的磁盘或分区上,以适应磁盘大小限制并简化备份和其他系统管理任务。 主要部分是根目录(/ ), /usr , /var,和/home文件系统(参见图 3-1)。 每个部分都有不同的用途。 目录树的设计使其可以在 Linux 机器的网络中很好地工作,这些机器可能会通过只读设备(例如,CD-ROM)或通过带有 NFS 的网络共享文件系统的一些部分。
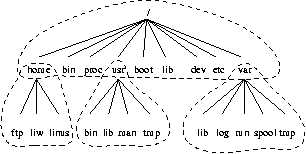
下面介绍了目录树不同部分的役割。
根文件系统对于每台机器都是特定的(它通常存储在本地磁盘上,尽管它也可以是 ramdisk 或网络驱动器),并且包含启动系统以及将其提升到可以安装其他文件系统的状态所需的文件。 因此,根文件系统的内容对于单用户状态来说就足够了。 它还将包含用于修复损坏的系统以及从备份中恢复丢失文件的工具。
的/usr文件系统包含正常运行期间所需的所有命令、库、手册页和其他不变文件。 任何文件都在/usr不应针对任何给定的机器是特定的,也不应在正常使用期间对其进行修改。 这允许文件通过网络共享,这可以节省成本,因为它节省了磁盘空间(很容易有数百兆字节,在/usr中越来越多地达到数千兆字节)。 它可以使管理更容易(在更新应用程序时只需要更改主/usr,而不是每台机器单独更改)以具有 /usr 网络挂载。 即使文件系统在本地磁盘上,也可以将其挂载为只读,以减少崩溃期间文件系统损坏的可能性。
的/var文件系统包含更改的文件,例如后台处理目录(用于邮件、新闻、打印机等)、日志文件、格式化的手册页和临时文件。 传统上,一切都在/var都在/usr下面,但这使得无法挂载/usr为只读。
的/home文件系统包含用户的home目录,即系统上的所有真实数据。 将主目录分离到它们自己的目录树或文件系统可以更轻松地进行备份; 其他部分通常不需要备份,或者至少不像它们很少更改那样频繁地备份。 一个大的/home可能不得不跨多个文件系统进行分解,这需要在/home下添加额外的命名级别,例如/home/students和/home/staff.
虽然上面已经将不同的部分称为文件系统,但没有要求它们实际上位于单独的文件系统上。 如果该系统是一个小型单用户系统并且用户希望保持简单,它们可以很容易地保存在一个文件中。 目录树也可能以不同的方式划分为文件系统,具体取决于磁盘的大小以及如何为各种用途分配空间。 然而,重要的是所有标准名称都有效; 即使比如说,/var和/usr实际上位于同一分区上,名称/usr/lib/libc.a和/var/log/messages必须有效,例如通过将文件移动到/var下 进入/usr/var,并制作/var到/usr/var.
的符号链接。Unix 文件系统结构根据用途对文件进行分组,即,所有命令都位于一个位置,所有数据文件位于另一个位置,文档位于第三个位置,依此类推。 另一种方法是根据文件所属的程序对文件进行分组,即,所有 Emacs 文件都位于一个目录中,所有 TeX 文件都位于另一个目录中,依此类推。 后一种方法的问题在于,它使共享文件变得困难(程序目录通常包含静态、可共享、可更改和不可共享的文件),有时甚至很难找到文件(例如,大量位置的手册页,并且使手册页程序找到所有这些文件是一场维护噩梦)。
3.2. 根文件系统
根文件系统通常应该很小,因为它包含非常关键的文件,并且小型的、不经常修改的文件系统更有可能不会损坏。 损坏的根文件系统通常意味着该系统将无法启动,除非采取特殊措施(例如,从软盘启动),所以您不希望冒这个风险。
根目录通常不包含任何文件,除非在较旧的系统上,该系统的标准启动映像通常称为/vmlinuz保存在那里。(大多数发行版已将这些文件移动到/boot目录。 否则,所有文件都保存在根文件系统下的子目录中
- /bin
启动期间需要的命令,普通用户可能会使用(可能在启动后)。
- /sbin
喜欢/bin,但这些命令不适用于普通用户,尽管他们可以在必要时并且在允许的情况下使用它们。/sbin通常不在普通用户的默认路径中,但会在 root 的默认路径中。
- /etc
特定于机器的配置文件。
- /root
用户 root 的主目录。 这通常对系统上的其他用户不可访问
- /lib
根文件系统上的程序所需的共享库。
- /lib/modules
可加载的内核模块,特别是那些在从灾难中恢复时启动系统所需的模块(例如,网络和文件系统驱动程序)。
- /dev
设备文件。 这些是特殊文件,可帮助用户与系统上的各种设备进行交互。
- /tmp
临时文件。顾名思义,正在运行的程序经常在此处存储临时文件。
- /boot
引导加载程序(例如,LILO 或 GRUB)使用的文件。内核镜像通常保存在这里,而不是在根目录中。 如果有很多内核镜像,该目录很容易变得非常大,最好将其放在一个单独的文件系统中。 另一个原因是确保内核镜像位于 IDE 磁盘的前 1024 个柱面内。 在大多数情况下,这个 1024 柱面限制已不再适用。 借助现代 BIOS 和更高版本的 LILO (the LInux LOader),可以使用逻辑块寻址 (LBA) 传递 1024 柱面限制。 有关更多详细信息,请参见 lilo 手册页。
- /mnt
系统管理员用于临时挂载的挂载点。程序不应该自动挂载到/mnt。/mnt可以分为子目录(例如,/mnt/dosa可能是使用 MS-DOS 文件系统的软盘驱动器,而/mnt/exta可能是使用 ext2 文件系统的相同驱动器)。
- /proc, /usr, /var, /home
其他文件系统的挂载点。 虽然/proc实际上并不位于任何磁盘上,但仍在此处提及。 请参阅本章后面有关/proc的部分。
3.3./etc目录
的/etc维护着许多文件。 其中一些文件将在下面介绍。 对于其他文件,您应该确定它们属于哪个程序,并阅读该程序的手册页。 许多网络配置文件也位于/etc中,并在网络管理员指南中进行描述。
- /etc/rc或/etc/rc.d或/etc/rc?.d
启动时或更改运行级别时要运行的脚本或脚本目录。 有关更多信息,请参见第 2.3.1 节。
- /etc/passwd
用户数据库,其中包含提供用户名、真实姓名、主目录以及有关每个用户的其他信息的字段。 格式记录在 passwd 手册页中。
- /etc/shadow
/etc/shadow是一个加密文件,其中保存着用户密码。
- /etc/fdprm
软盘参数表。 描述不同软盘格式的外观。 由 setfdprm 使用。 有关更多信息,请参见 setfdprm 手册页。
- /etc/fstab
列出启动时由 mount -a 命令(在/etc/rc或等效的启动文件中)自动挂载的文件系统。 在 Linux 下,还包含有关 swapon -a 自动使用的交换空间的信息。 有关更多信息,请参见 第 5.10.7 节和 mount 手册页。 此外,fstab通常在第 5 节中有其自己的手册页。
- /etc/group
类似于/etc/passwd,但描述的是组而不是用户。 有关更多信息,请参见第 5 节中的group手册页。
- /etc/inittab
init 的配置文件。
- /etc/issue
由 getty 在登录提示符之前输出。 通常包含对系统的简短描述或欢迎消息。 内容取决于系统管理员。
- /etc/magic
file 的配置文件。 包含各种文件格式的描述,file 根据这些描述猜测文件类型。 有关更多信息,请参见magic和 file 手册页。
- /etc/motd
每日消息,在成功登录后自动输出。 内容取决于系统管理员。 通常用于向每个用户获取信息,例如有关计划停机的警告。
- /etc/mtab
当前挂载的文件系统的列表。 最初由启动脚本设置,并由 mount 命令自动更新。 当需要挂载的文件系统列表时使用,例如,由 df 命令使用。
- /etc/login.defs
login 命令的配置文件。login.defs文件通常在第 5 节中有一个手册页。
- /etc/printcap
喜欢/etc/termcap /etc/printcap,但适用于打印机。 但是,它使用不同的语法。printcap在第 5 节中有一个手册页。
- /etc/profile, /etc/bash.rc, /etc/csh.cshrc
Bourne、BASH 或 C shell 在登录或启动时执行的文件。 这些文件允许系统管理员为所有用户设置全局默认值。 用户还可以在其主目录中创建这些文件的单个副本,以个性化他们的环境。 请参阅各个 shell 的手册页。
- /etc/securetty
标识安全终端,即允许 root 登录的终端。 通常只列出虚拟控制台,这样就可以(或至少更难)通过通过调制解调器或网络侵入系统来获得超级用户权限。 不允许通过网络进行 root 登录。 最好以非特权用户身份登录,并使用 su 或 sudo 来获得 root 权限。
- /etc/shells
列出受信任的 shell。 chsh 命令允许用户仅将其登录 shell 更改为此文件中列出的 shell。 ftpd 是为计算机提供 FTP 服务的服务器进程,将检查用户的 shell 是否在/etc/shells中列出,并且不允许用户登录,除非该 shell 在那里列出。
- /etc/termcap
终端功能数据库。 描述可以通过什么“转义序列”来控制各种终端。 程序的编写方式是,它们不是直接输出仅适用于特定品牌终端的转义序列,而是在/etc/termcap中查找执行他们想要执行的任何操作的正确序列。 因此,大多数程序都可以与大多数类型的终端一起使用。 请参阅termcap、curs_termcap 和terminfo手册页以获取更多信息。
3.4./dev目录
的/dev目录包含所有设备的特殊设备文件。 设备文件在安装期间创建,稍后使用 /dev/MAKEDEV 脚本创建。/dev/MAKEDEV.local 是系统管理员编写的脚本,用于创建仅限本地的设备文件或链接(即,那些不是标准 MAKEDEV 的一部分,例如某些非标准设备驱动程序的设备文件)。
以下列表绝不是详尽无遗的,也没有尽可能详细。 其中许多设备文件将需要编译到您的内核中以支持硬件。 阅读内核文档以查找任何特定设备的详细信息。
如果您认为应该包含在此处但没有包含的其他设备,请告诉我。 我会尝试在下一个版本中包含它们。
- /dev/dsp
数字信号处理器。 基本上,它构成了产生声音的软件与您的声卡之间的接口。 它是主节点 14 和次节点 3 上的字符设备。
- /dev/fd0
第一个软盘驱动器。 如果您足够幸运拥有多个驱动器,那么它们将按顺序编号。 它是主节点 2 和次节点 0 上的字符设备。
- /dev/fb0
第一个帧缓冲区设备。 帧缓冲区是软件和图形硬件之间的抽象层。 这意味着应用程序不需要知道您拥有哪种硬件,而只需知道如何与定义明确且标准化的帧缓冲区驱动程序的 API(应用程序编程接口)进行通信。 帧缓冲区是字符设备,位于主节点 29 和次节点 0 上。
- /dev/hda
/dev/hda是主 IDE 控制器上的主 IDE 驱动器。/dev/hdb是主控制器上的从属驱动器。/dev/hdc,和/dev/hdd分别是辅助控制器上的主设备和从设备。 每个磁盘都分为分区。 分区 1-4 是主分区,分区 5 及以上是扩展分区内的逻辑分区。 因此,引用每个分区的设备文件由多个部分组成。 例如/dev/hdc9引用辅助 IDE 控制器上主 IDE 驱动器上的分区 9(扩展分区类型中的逻辑分区)。 主节点和次节点编号有些复杂。 对于第一个 IDE 控制器,所有分区都是主节点 3 上的块设备。主驱动器hda位于次节点 0,从属驱动器hdb位于次节点 64。 对于驱动器内的每个分区,将分区号添加到驱动器的次节点编号中。 例如/dev/hdb5是主节点 3,次节点 69 (64 + 5 = 69)。 辅助接口上的驱动器的处理方式相同,但主节点为 22。
- /dev/ht0
第一个 IDE 磁带驱动器。 后续驱动器编号为ht1等等。 它们是主节点 37 上的字符设备,并且对于ht0从次节点 0 开始,对于ht1等等,从 1 开始。
- /dev/js0
第一个模拟摇杆。 后续摇杆编号为js1, js2等等。 数字摇杆称为djs0, djs1等等。 它们是主节点 15 上的字符设备。模拟摇杆从次节点 0 开始,最多可达 127(即使对于最狂热的游戏玩家来说也绰绰有余)。 数字摇杆从次节点 128 开始。
- /dev/lp0
第一个并行打印机设备。 后续打印机编号为lp1, lp2等等。 它们是主模式 6 上的字符设备,次节点从 0 开始并按顺序编号。
- /dev/loop0
第一个环回设备。 环回设备用于挂载未位于其他块设备(如磁盘)上的文件系统。 例如,如果您希望挂载 iso9660 CD ROM 映像而不将其刻录到 CD,则需要使用环回设备来执行此操作。 这通常对用户是透明的,并且由 mount 命令处理。 请参阅 mount 和 losetup 的手册页。 环回设备是主节点 7 上的块设备,次节点从 0 开始并按顺序编号。
- /dev/md0
第一个元磁盘组。 元磁盘与 RAID(独立磁盘冗余阵列)设备相关。 有关更多详细信息,请参阅 LDP 上最新的 RAID HOWTO。 可以在 http://www.tldp.org/HOWTO/Software-RAID-HOWTO.html 上找到。 元磁盘设备是主节点 9 上的块设备,次节点从 0 开始并按顺序编号。
- /dev/mixer
这是 OSS(开放声音系统)驱动程序的一部分。 有关更多详细信息,请参阅 http://www.opensound.com 上的 OSS 文档。 它是主节点 14,次节点 0 上的字符设备。
- /dev/null
位桶。 一个黑洞,您可以将数据发送到其中,使其永远不会再被看到。 发送到/dev/null的任何内容都将消失。 例如,如果您希望运行命令但不希望任何反馈出现在终端上,这将非常有用。 它是主节点 1 和次节点 3 上的字符设备。
- /dev/psaux
PS/2 鼠标端口。 它是主节点 10,次节点 1 上的字符设备。
- /dev/pda
并行端口 IDE 磁盘。 它们的命名方式与内部 IDE 控制器上的磁盘类似 (/dev/hd*)。 它们是主节点 45 上的块设备。此处需要对次节点进行更多说明。 第一个设备是/dev/pda,它位于次节点 0 上。通过将分区号添加到设备的次节点编号来找到此设备上的分区。 每个设备最多只能有 15 个分区,而不是 63 个(内部 IDE 磁盘的限制)。/dev/pdb次节点从 16 开始,/dev/pdc从 32 开始,/dev/pdd从 48 开始。 因此,例如/dev/pdc6的次节点编号为 38 (32 + 6 = 38)。 此方案将您限制为 4 个并行磁盘,每个磁盘有 15 个分区。
- /dev/pcd0
并行端口 CD ROM 驱动器。 这些从 0 开始编号。 所有都是主节点 46 上的块设备。/dev/pcd0位于次节点 0 上,后续驱动器位于次节点 1、2、3 等上。
- /dev/pt0
并行端口磁带设备。磁带没有分区,所以它们只是按顺序编号。它们是主节点 96 上的字符设备。次节点编号从 0 开始,对应于/dev/pt0,1 对应于/dev/pt1,依此类推。
- /dev/parport0
原始并行端口。大多数连接到并行端口的设备都有自己的驱动程序。这是一个直接访问端口的设备。它是主节点 99,次节点 0 的字符设备。第一个设备之后的后续设备按顺序递增次节点编号。
- /dev/random或/dev/urandom
这些是内核随机数生成器。/dev/random是一个非确定性生成器,这意味着无法从前面的数字猜测下一个数字的值。它使用系统硬件的熵来生成数字。当它没有更多的熵可用时,它必须等待,直到它收集到更多熵才能允许从中读取更多数字。/dev/urandom的工作方式类似。最初它也使用系统硬件的熵,但是当没有更多的熵可用时,它将继续使用伪随机数生成公式返回数字。对于诸如密码密钥对生成之类的关键目的,这被认为不太安全。如果安全性是您最关心的问题,请使用/dev/random,如果速度更重要,则/dev/urandom可以正常工作。它们是主节点 1 上的字符设备,次节点 8 对应于/dev/random,9 对应于/dev/urandom.
- /dev/sda
第一个 SCSI 总线上的第一个 SCSI 驱动器。以下驱动器的命名方式与 IDE 驱动器类似。/dev/sdb是第二个 SCSI 驱动器,/dev/sdc是第三个 SCSI 驱动器,依此类推。
- /dev/ttyS0
第一个串行端口。很多时候,这是用于将外部调制解调器连接到系统的端口。
- /dev/zero
这是一种获取许多 0 的简单方法。每次您从此设备读取时,它都会返回 0。这有时可能很有用,例如,当您想要一个固定长度的文件,但并不真正在意它包含什么时。它是主节点 1 和次节点 5 的字符设备。
3.5. The/usr文件系统。
的/usr文件系统通常很大,因为所有程序都安装在那里。中的所有文件/usr通常来自 Linux 发行版;本地安装的程序和其他东西位于/usr/local之下。这样就可以从新版本的发行版甚至全新的发行版更新系统,而无需再次安装所有程序。的部分子目录/usr列在下面(一些不太重要的目录已被删除;有关更多信息,请参见 FSSTND)。
- /usr/X11R6.
X Window 系统,所有文件。为了简化 X 的开发和安装,X 文件尚未集成到系统的其余部分。下面有一个目录树/usr/X11R6类似于下面的目录树/usr本身。
- /usr/bin.
几乎所有用户命令。一些命令在/bin或在/usr/local/bin.
- /usr/sbin
根文件系统上不需要的系统管理命令,例如,大多数服务器程序。
- /usr/share/man, /usr/share/info, /usr/share/doc
分别是手册页、GNU Info 文档和其他各种文档文件。
- /usr/include
C 编程语言的头文件。实际上这应该在/usr/lib之下以保持一致性,但是传统上对此名称的支持非常强烈。
- /usr/lib
程序和子系统的不变数据文件,包括一些站点范围的配置文件。名称lib来自 library;最初编程子例程库存储在/usr/lib.
- /usr/local
本地安装的软件和其他文件的位置。发行版可能不会在此处安装任何东西。它仅供本地管理员使用。这样,他就可以完全确定他对发行版的所有更新或升级都不会覆盖他本地安装的任何额外软件。
3.6. The/var文件系统
的/var包含系统正常运行时更改的数据。它是每个系统特有的,即不通过网络与其他计算机共享。
- /var/cache/man
按需格式化的手册页的缓存。手册页的源文件通常存储在/usr/share/man/man?/(其中 ? 是手册章节。请参阅第 7 节中的 man 手册页);一些手册页可能带有预格式化的版本,该版本可能存储在/usr/share/man/cat*中。其他手册页需要在首次查看时进行格式化;然后将格式化后的版本存储在/var/cache/man中,以便下一个查看同一页面的人不必等待格式化。
- /var/games
中属于游戏的所有可变数据/usr应放在此处。这是为了防止 /usr 以只读方式挂载。
- /var/lib
系统正常运行时会更改的文件。
- /var/local
中安装的程序的可变数据/usr/local(即,由系统管理员安装的程序)。请注意,即使是本地安装的程序,如果适用,也应使用其他/var目录,例如,/var/lock.
- /var/lock
锁定文件。许多程序遵循一种约定,即在/var/lock中创建一个锁定文件,以指示它们正在使用特定的设备或文件。其他程序会注意到该锁定文件,并且不会尝试使用该设备或文件。
- /var/log
来自各种程序的日志文件,尤其是 login(/var/log/wtmp,它记录所有登录和注销系统的行为) 和 syslog(/var/log/messages,其中通常存储所有内核和系统程序消息)。中的文件/var/log通常会无限增长,并且可能需要定期清理。
- /var/mail
这是 FHS 批准的用户邮箱文件的位置。根据您的发行版对 FHS 的遵守程度,这些文件可能仍保留在/var/spool/mail.
- /var/run
包含有关系统的有效信息的文件,直到系统下次启动。例如,/var/run/utmp包含有关当前登录人员的信息。
- /var/spool
用于新闻、打印机队列和其他排队工作的目录。每个不同的假脱机都有其在/var/spool下的子目录,例如,新闻假脱机在/var/spool/news中。请注意,某些不完全符合最新版本 FHS 的安装可能在/var/spool/mail.
- /var/tmp
下具有用户邮箱/tmp临时文件,这些文件很大或需要存在的时间比允许的/var/tmp长。(尽管系统管理员可能不允许
3.7. The/proc文件系统
的/proc文件系统包含一个虚构的文件系统。它不存在于磁盘上。相反,内核在内存中创建它。它用于提供有关系统的信息(最初是关于进程的,因此得名)。下面解释了一些更重要的文件和目录。该/proc文件系统在proc手册页中进行了更详细的描述。
- /proc/1
包含有关进程号 1 的信息的目录。每个进程在/proc下都有一个目录,名称为其进程标识号。
- /proc/cpuinfo
有关处理器的信息,例如其类型、制造商、型号和性能。
- /proc/devices
配置到当前运行内核中的设备驱动程序列表。
- /proc/dma
显示当前正在使用的 DMA 通道。
- /proc/filesystems
配置到内核中的文件系统。
- /proc/interrupts
显示哪些中断正在使用中,以及每种中断的数量。
- /proc/ioports
当前正在使用的 I/O 端口。
- /proc/kcore
系统物理内存的映像。这与您的物理内存大小完全相同,但实际上并不占用那么多内存;它是程序访问它时动态生成的。(请记住:除非您将其复制到其他位置,否则/proc下的任何内容都不会占用任何磁盘空间。)
- /proc/kmsg
内核输出的消息。这些消息也路由到 syslog。
- /proc/ksyms
内核的符号表。
- /proc/loadavg
系统的“平均负载”;三个无意义的指标,表明系统目前必须执行多少工作。
- /proc/meminfo
有关内存使用情况的信息,包括物理内存和交换内存。
- /proc/modules
当前加载的内核模块。
- /proc/net
有关网络协议的状态信息。
- /proc/self
指向正在查看/proc的程序的进程目录的符号链接。当两个进程查看/proc时,它们会获得不同的链接。这主要是为了方便程序访问其进程目录。
- /proc/stat
有关系统的各种统计信息,例如自系统启动以来的缺页次数。
- /proc/uptime
系统已运行的时间。
- /proc/version
内核版本。
请注意,虽然上述文件往往是易于阅读的文本文件,但它们的格式有时不易理解。有许多命令除了读取上述文件并对其进行格式化以使其更易于理解之外,几乎没有其他作用。例如,free 程序读取/proc/meminfo将以字节为单位给出的数量转换为千字节(并添加一些更多信息)。
第 4 章。硬件、设备和工具
“知识会说话,但智慧会倾听。” Jimi Hendrix
本章概述了设备文件是什么以及如何创建设备文件。设备文件的规范列表是/usr/src/linux/Documentation/devices.txt如果您的系统上安装了 Linux 内核源代码。此处列出的设备截至内核版本 2.6.8 是正确的。
4.1. 硬件实用程序
4.1.1. MAKEDEV 脚本
大多数设备文件将被预先创建,并且在您安装 Linux 系统后即可使用。如果碰巧您需要创建一个未提供的设备文件,那么您应该首先尝试使用 MAKEDEV 脚本。此脚本通常位于/dev/MAKEDEV,但也可能在/sbin/MAKEDEV中有一个副本(或符号链接)。如果它不在您的路径中,那么您需要显式指定其路径。
通常,该命令的用法如下:
# /dev/MAKEDEV -v ttyS0 create ttyS0 c 4 64 root:dialout 0660 |
ttyS0是一个串行端口。主设备号和次设备号是内核能够理解的数字。内核使用数字来指代硬件设备,但这对我们来说很难记忆,所以我们使用文件名。访问权限 0660 意味着所有者(本例中为 root)具有读写权限,组成员(本例中为 dialout)也具有读写权限,而其他人则没有任何访问权限。
4.1.2. mknod 命令
优先使用 MAKEDEV 创建不存在的设备文件。然而,有时 MAKEDEV 脚本可能不知道您希望创建的设备文件。这时就需要用到 mknod 命令。为了使用 mknod,您需要知道您希望创建的设备的主设备号和次设备号。devices.txt内核源代码文档中的文件是此信息的权威来源。
举个例子,假设我们的 MAKEDEV 脚本版本不知道如何创建/dev/ttyS0设备文件。我们需要使用 mknod 来创建它。我们从查看devices.txt得知它应该是一个字符设备,主设备号为 4,次设备号为 64。因此,我们现在知道了创建该文件所需的一切。
# mknod /dev/ttyS0 c 4 64 # chown root.dialout /dev/ttyS0 # chmod 0644 /dev/ttyS0 # ls -l /dev/ttyS0 crw-rw---- 1 root dialout 4, 64 Oct 23 18:23 /dev/ttyS0 |
第五章. 使用磁盘和其他存储介质
“在空白磁盘上,你可以永远寻找。“
当您安装或升级系统时,您需要在磁盘上做大量的工作。您必须在磁盘上创建文件系统,以便文件可以存储在磁盘上,并为系统的不同部分保留空间。
本章解释了所有这些初始活动。通常,一旦您设置好系统,除了使用软盘外,您无需再次完成这些工作。如果您添加新磁盘或想要微调磁盘使用情况,则需要回到本章。
管理磁盘的基本任务是
格式化您的磁盘。 这会做各种各样的事情来准备使用它,例如检查坏扇区。 (如今,大多数硬盘驱动器都不需要格式化。)
如果您想将其用于几种不应相互干扰的活动,请对硬盘进行分区。 分区的一个原因是将不同的操作系统存储在同一磁盘上。 另一个原因是将用户文件与系统文件分开,这简化了备份并有助于保护系统文件免受损坏。
在每个磁盘或分区上创建一个(合适类型的)文件系统。 在创建文件系统之前,磁盘对 Linux 毫无意义; 然后才能在其上创建和访问文件。
挂载不同的文件系统以形成单个树结构,可以是自动挂载,也可以根据需要手动挂载。 (手动挂载的文件系统通常也需要手动卸载。)
第 6 章 包含有关虚拟内存和磁盘缓存的信息,在使用磁盘时您也需要了解这些信息。
5.1. 两种设备
UNIX(因此也包括 Linux)识别两种不同的设备:随机访问块设备(例如磁盘)和字符设备(例如磁带和串行线路),其中一些可能是串行的,另一些可能是随机访问的。 每个受支持的设备在文件系统中都表示为设备文件。 当您读取或写入设备文件时,数据来自或流向它所代表的设备。 这样,就不需要特殊的程序(也没有特殊的应用程序编程方法,例如捕获中断或轮询串行端口)来访问设备; 例如,要将文件发送到打印机,可以只说
$ cat filename > /dev/lp1 $ |
由于设备在文件系统中显示为文件(在/dev目录中),使用 ls 或其他合适的命令很容易查看存在哪些设备文件。 在 ls -l 的输出中,第一列包含文件的类型及其权限。 例如,检查串行设备可能会给出
$ ls -l /dev/ttyS0 crw-rw-r-- 1 root dialout 4, 64 Aug 19 18:56 /dev/ttyS0 $ |
请注意,即使设备本身可能未安装,通常所有设备文件都存在。 因此,仅仅因为您有一个文件/dev/sda, 这并不意味着您确实拥有一个 SCSI 硬盘。 拥有所有设备文件使安装程序更简单,并且使添加新硬件更容易(无需找出正确的参数并为新设备创建设备文件)。
5.2. 硬盘
本小节介绍与硬盘相关的术语。 如果您已经了解这些术语和概念,则可以跳过本小节。
有关硬盘重要部件的示意图,请参见图 5-1。 硬盘由一个或多个圆形铝制 盘片组成,其中一个或两个表面涂有用于记录数据的磁性物质。 对于每个表面,都有一个读写头,用于检查或更改记录的数据。 盘片在公共轴上旋转; 典型的旋转速度为每分钟 5400 或 7200 转,但高性能硬盘的转速更高,而旧硬盘的转速可能更低。 磁头沿着盘片的半径移动; 这种运动与盘片的旋转相结合,使磁头可以访问表面的所有部分。
处理器 (CPU) 和实际磁盘通过 磁盘控制器 进行通信。 这使计算机的其他部分无需知道如何使用驱动器,因为可以使不同类型磁盘的控制器使用相同的接口来面对计算机的其余部分。 因此,计算机可以只说“嘿磁盘,给我我想要的东西”,而不是发送一长串复杂的电信号,将磁头移动到正确的位置并等待正确的位置来到磁头下方并执行所有其他令人不快的事情。 (实际上,与控制器的接口仍然很复杂,但比原本要简单得多。)控制器还可以执行其他操作,例如缓存或自动坏扇区更换。
以上通常是了解硬件所需的一切。 还有其他的东西,例如旋转盘片和移动磁头的电机,以及控制机械部件运行的电子设备,但它们大多与理解硬盘的工作原理无关。
表面通常分为同心环,称为磁道,而这些磁道又分为扇区。 此划分用于指定硬盘上的位置并将磁盘空间分配给文件。 要查找硬盘上的给定位置,可以说“表面 3,磁道 5,扇区 7”。 通常,所有磁道的扇区数都相同,但某些硬盘驱动器在外磁道中放置更多扇区(所有扇区都具有相同的物理尺寸,因此更多的扇区可以容纳在较长的外磁道中)。 通常,一个扇区将保存 512 字节的数据。 磁盘本身无法处理小于一个扇区的数据量。
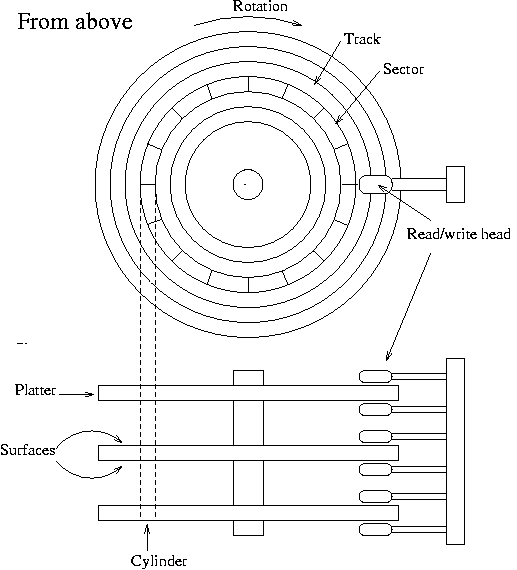
每个表面都以相同的方式划分为磁道(和扇区)。这意味着当一个表面的磁头位于某个磁道上时,其他表面的磁头也位于相应的磁道上。所有对应的磁道加在一起称为一个柱面。将磁头从一个磁道(柱面)移动到另一个磁道需要时间,因此,将经常一起访问的数据(例如,一个文件)放在一个柱面内,就不需要移动磁头来读取所有数据。这可以提高性能。并非总是能够这样放置文件;存储在磁盘上多个位置的文件称为碎片化。
表面(或磁头,它们是同一回事)、柱面和扇区的数量变化很大;每个数量的规格被称为硬盘的几何结构。几何结构通常存储在一个特殊的、电池供电的存储位置,称为CMOS RAM,操作系统可以在启动或驱动程序初始化期间从中获取它。
不幸的是,BIOS 有一个设计限制,导致在 CMOS RAM 中无法指定大于 1024 的磁道号,对于大型硬盘来说,这太少了。为了克服这个问题,硬盘控制器谎报几何结构,并转换地址,将计算机给出的地址转换为符合实际情况的东西。例如,一个硬盘可能拥有 8 个磁头、2048 个磁道和每个磁道 35 个扇区。它的控制器可能会欺骗计算机,声称它拥有 16 个磁头、1024 个磁道和每个磁道 35 个扇区,从而不超出磁道限制,并通过将磁头号减半,并将磁道号加倍来转换计算机给它的地址。实际上,数学运算可能更复杂,因为数字不像这里那样好(但同样,细节与理解原理无关)。这种转换扭曲了操作系统对磁盘如何组织的看法,因此使得使用 all-data-on-one-cylinder(所有数据都在一个柱面)的技巧来提高性能变得不切实际。
转换仅仅是 IDE 磁盘的问题。SCSI 磁盘使用顺序扇区号(即,控制器将顺序扇区号转换为磁头、柱面和扇区的三元组),并且使用完全不同的方法让 CPU 与控制器通信,因此它们与该问题隔离开来。但是请注意,计算机可能也不知道 SCSI 磁盘的真实几何结构。
由于 Linux 通常不会知道磁盘的真实几何结构,因此其文件系统甚至不会尝试将文件保存在单个柱面内。相反,它会尝试将顺序编号的扇区分配给文件,这几乎总是能提供相似的性能。控制器上的缓存以及控制器执行的自动预取使问题更加复杂。
每个硬盘由一个单独的设备文件表示。通常(通常)只能有两个或四个 IDE 硬盘。它们被称为/dev/hda, /dev/hdb, /dev/hdc,和/dev/hdd, 分别。SCSI 硬盘被称为/dev/sda, /dev/sdb, 等等。其他硬盘类型也存在类似的命名约定;有关更多信息,请参见第 4 章。请注意,硬盘的设备文件提供对整个磁盘的访问,而无需考虑分区(将在下面讨论),如果您不小心,很容易弄乱分区或其中的数据。磁盘的设备文件通常仅用于访问主引导记录(也将在下面讨论)。
5.3. 存储区域网络 - 草案
SAN 是一个专用存储网络,提供对 LUN 的块级访问。LUN 或逻辑单元号,是由 SAN 提供的虚拟磁盘。系统管理员对 LUN 拥有相同的访问权限和权利,就好像它是直接连接到它的磁盘一样。管理员可以用任何他或她选择的方式对磁盘进行分区和格式化。
SAN 中常用的两种网络协议是光纤通道和iSCSI。光纤通道网络速度非常快,并且不受公司 LAN 中其他网络流量的负担。但是,它非常昂贵。光纤通道卡每张大约花费 1000.00 美元。它们还需要特殊的光纤通道交换机。
iSCSI 是一种较新的技术,它通过 TCP/IP 网络发送 SCSI 命令。虽然这种方法可能不如光纤通道网络那么快,但它可以通过使用成本较低的网络硬件来省钱。
更多内容待添加
5.4. 网络附加存储 - 草案
NAS 使用您公司的现有以太网网络来允许访问共享磁盘。 这是文件系统级别的访问。系统管理员无法对磁盘进行分区或格式化,因为它们可能由多台计算机共享。 该技术通常用于为多个工作站提供对相同数据的访问。
与 SAN 类似,NAS 需要使用协议来允许访问其磁盘。 对于 NAS,这要么是 CIFS/Samba,要么是 NFS。
传统上,CIFS 与 Microsoft Windows 网络一起使用,而 NFS 与 UNIX 和 Linux 网络一起使用。 但是,通过 Samba,Linux 机器也可以使用 CIFS 共享。
这是否意味着您的 Windows 2003 服务器或您的 Linux 盒子是 NAS 服务器,因为它们通过您的网络提供对共享驱动器的访问? 是的,它们是。您也可以从许多制造商处购买 NAS 设备。 这些设备专门设计用于提供对数据的高速访问。
更多内容待添加
5.5. 软盘
软盘由柔性薄膜组成,该薄膜在一面或两面上都覆盖有与硬盘类似的磁性物质。 软盘本身没有读写头,该读写头包含在驱动器中。 软盘对应于硬盘中的一个盘片,但它是可移动的,并且一个驱动器可用于访问不同的软盘,并且同一软盘可由多个驱动器读取,而硬盘是一个不可分割的单元。
像硬盘一样,软盘被分成磁道和扇区(并且软盘两侧的两个相应磁道形成一个柱面),但是它们的数量比硬盘少得多。
软盘驱动器通常可以使用几种不同类型的磁盘; 例如,3.5 英寸驱动器可以使用 720 KB 和 1.44 MB 的磁盘。 由于驱动器必须以稍微不同的方式运行,并且操作系统必须知道磁盘有多大,因此软盘驱动器有许多设备文件,每个设备文件对应于驱动器和磁盘类型的组合。 因此,/dev/fd0H1440是第一个软盘驱动器(fd0),它必须是 3.5 英寸驱动器,使用 3.5 英寸、高密度磁盘(H),大小为 1440 KB(1440),即普通的 3.5 英寸 HD 软盘。
但是,软盘驱动器的名称很复杂,因此 Linux 有一种特殊的软盘设备类型,可以自动检测驱动器中磁盘的类型。 它的工作方式是尝试使用不同的软盘类型读取新插入的软盘的第一个扇区,直到找到正确的类型。 这自然要求首先格式化软盘。 自动设备称为/dev/fd0, /dev/fd1,依此类推。
也可以使用程序setfdprm设置自动设备用于访问磁盘的参数。 如果您需要使用不遵循任何常用软盘尺寸的磁盘,例如,如果它们具有不寻常的扇区数,或者如果自动检测由于某种原因失败并且缺少适当的设备文件,则这可能很有用。
除了所有标准格式外,Linux 还可以处理许多非标准软盘格式。 其中一些需要使用特殊的格式化程序。 我们暂时跳过这些磁盘类型,但与此同时,您可以检查/etc/fdprm文件。 它指定了setfdprm识别的设置。
操作系统必须知道何时更改了软盘驱动器中的磁盘,例如,为了避免使用来自先前磁盘的缓存数据。 不幸的是,用于此目的的信号线有时会断开,更糟糕的是,从 MS-DOS 中使用驱动器时,这并不总是显而易见的。 如果您在使用软盘时遇到奇怪的问题,这可能是原因。 纠正它的唯一方法是修复软盘驱动器。
5.6. CD-ROM
CD-ROM 驱动器使用光学读取的塑料涂层光盘。 信息记录在光盘表面上的小“孔”中,这些“孔”沿着从中心到边缘的螺旋线排列。 驱动器将激光束沿着螺旋线引导以读取光盘。 当激光束击中一个孔时,激光束以一种方式反射; 当它击中光滑的表面时,它以另一种方式反射。 这使得对位进行编码,从而对信息进行编码变得容易。 其余的很简单,只是机械原理。
与硬盘相比,CD-ROM 驱动器速度较慢。 虽然典型的硬盘驱动器的平均寻道时间小于 15 毫秒,但快速 CD-ROM 驱动器可以使用十分之几秒进行寻道。 实际数据传输速率相当高,达到每秒数百千字节。 这种缓慢意味着 CD-ROM 驱动器不如硬盘那么容易使用(某些 Linux 发行版在 CD-ROM 上提供“实时”文件系统,从而无需将文件复制到硬盘,从而使安装更容易并节省大量硬盘空间),尽管它仍然是可能的。 对于安装新软件,CD-ROM 非常好,因为在安装过程中最大速度不是必需的。
有几种方法可以在 CD-ROM 上安排数据。 最流行的一种由国际标准 ISO 9660 指定。 该标准指定了一个非常小的文件系统,甚至比 MS-DOS 使用的文件系统还要粗糙。 另一方面,它非常小,以至于每个操作系统都应该能够将其映射到其本机系统。
对于正常的 UNIX 使用,ISO 9660 文件系统不可用,因此开发了该标准的扩展,称为 Rock Ridge 扩展。 Rock Ridge 允许更长的文件名、符号链接和许多其他优点,使 CD-ROM 看起来或多或少像任何现代 UNIX 文件系统。 更好的是,Rock Ridge 文件系统仍然是有效的 ISO 9660 文件系统,使其也可以被非 UNIX 系统使用。 Linux 支持 ISO 9660 和 Rock Ridge 扩展; 这些扩展会被自动识别和使用。
然而,文件系统只是成功的一半。大多数 CD-ROM 包含需要特定程序才能访问的数据,而这些程序大多不能在 Linux 下运行(除非可能在 dosemu(Linux 的 MS-DOS 模拟器)或 wine(Windows 模拟器)下运行)。
具有讽刺意味的是,wine 实际上是 ``Wine Is Not an Emulator''(Wine 不是模拟器)的缩写。 更严格地说,Wine 是一种 API(应用程序编程接口)替换。 请访问 http://www.winehq.com 获取更多信息。
还有 VMWare,这是一种商业产品,它可以在软件中模拟整个 x86 机器。 请访问 VMWare 网站 http://www.vmware.com 获取更多信息。
CD-ROM 驱动器通过相应的设备文件访问。 有几种方法可以将 CD-ROM 驱动器连接到计算机:通过 SCSI、声卡或 EIDE。 完成此操作所需的硬件破解不在本书的范围之内,但连接类型决定了设备文件。
5.7. 磁带
磁带驱动器使用磁带,类似于用于音乐的卡带。 磁带本质上是串行的,这意味着要访问任何给定部分,您首先必须通过其间的所有部分。 可以随机访问磁盘,即您可以直接跳转到磁盘上的任何位置。 磁带的串行访问使其速度较慢。
另一方面,磁带的制造成本相对较低,因为它们不需要很快的速度。 它们也很容易做得非常长,因此可以包含大量数据。 这使得磁带非常适合存档和备份之类的事情,这些事情不需要很高的速度,但可以从低成本和大存储容量中受益。
5.8. 格式化
格式化是在磁介质上写入标记以标记磁道和扇区的过程。 在磁盘被格式化之前,其磁表面是磁信号的完全混乱状态。 格式化后,通过基本上绘制磁道所在的位置以及它们被划分为扇区的位置,将一些顺序引入到混乱中。 实际细节并非完全如此,但这无关紧要。 重要的是,除非磁盘已被格式化,否则无法使用。
这里的术语有点令人困惑:在 MS-DOS 和 MS Windows 中,格式化一词也用于涵盖创建文件系统的过程(这将在下面讨论)。 在那里,这两个过程通常结合在一起,尤其是对于软盘而言。 当需要区分时,真正的格式化称为 低级格式化,而创建文件系统称为 高级格式化。 在 UNIX 圈子中,这两个过程被称为格式化和创建文件系统,因此本书也使用这些术语。
对于 IDE 和某些 SCSI 磁盘,格式化实际上是在工厂完成的,不需要重复;因此,大多数人很少需要担心它。 实际上,格式化硬盘可能会导致其工作效果变差,例如,因为磁盘可能需要以某种非常特殊的方式格式化,以允许自动坏扇区替换工作。
需要或可以格式化的磁盘通常也需要一个特殊的程序,因为驱动器内部格式化逻辑的接口因驱动器而异。 格式化程序通常位于控制器 BIOS 上,或作为 MS-DOS 程序提供; 这两种方式都不能轻易地在 Linux 中使用。
在格式化期间,可能会遇到磁盘上的坏点,称为 坏块 或 坏扇区。 这些有时由驱动器本身处理,但即使这样,如果出现更多坏点,也需要采取一些措施来避免使用磁盘的这些部分。 用于执行此操作的逻辑内置于文件系统中; 如何将信息添加到文件系统在下面描述。 或者,可以创建一个小分区,仅覆盖磁盘的坏部分; 如果坏点非常大,则此方法可能是一个好主意,因为文件系统有时可能难以处理非常大的坏区域。
软盘使用 fdformat 格式化。 要使用的软盘设备文件作为参数给出。 例如,以下命令将格式化第一个软盘驱动器中的高密度 3.5 英寸软盘
$ fdformat /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 kB. Formatting ... done Verifying ... done $ |
$ setfdprm /dev/fd0 1440/1440 $ fdformat /dev/fd0 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done Verifying ... done $ |
fdformat 还会验证软盘,即检查它是否存在坏块。 它会多次尝试坏块(您通常可以听到这个,驱动器的噪音会发生显着变化)。 如果软盘仅是轻微损坏(由于读/写头上沾有污垢,某些错误是错误的信号),fdformat 不会抱怨,但真正的错误会中止验证过程。 内核将为它找到的每个 I/O 错误打印日志消息; 这些消息将发送到控制台,或者如果使用 syslog,则发送到文件/var/log/messages。 fdformat 本身不会告诉您错误在哪里(通常人们不在乎,软盘足够便宜,坏的软盘会自动扔掉)。
$ fdformat /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done Verifying ... read: Unknown error $ |
$ badblocks /dev/fd0H1440 1440 718 719 $ |
许多现代磁盘会自动注意到坏块,并尝试通过使用特殊的、保留的好块来修复它们。 这对操作系统是不可见的。 如果您好奇它是否正在发生,此功能应记录在磁盘的手册中。 即使是这样的磁盘也可能会出现故障,如果坏块的数量变得太大,尽管到那时磁盘很可能已经变得如此糟糕以至于无法使用。
5.9. 分区
硬盘可以划分为多个分区。每个分区的功能就像它是一个单独的硬盘。想法是,如果您有一个硬盘,并且想在其中安装两个操作系统,则可以将磁盘划分为两个分区。每个操作系统根据自己的意愿使用其分区,并且不触摸其他分区。这样,两个操作系统就可以在同一硬盘上和平共存。如果没有分区,则必须为每个操作系统购买一个硬盘。
软盘通常不分区。 这在技术上没有反对的理由,但由于它们太小,因此分区很少有用。 CD-ROM 通常也不分区,因为将它们用作一个大磁盘更容易,并且很少需要在同一个 CD-ROM 上安装多个操作系统。
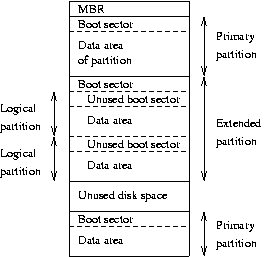
5.9.1. MBR、引导扇区和分区表
有关硬盘如何分区的的信息存储在其第一个扇区中(即,第一个磁盘表面上第一条磁道的第一个扇区)。 第一个扇区是磁盘的主引导记录 (MBR); 这是 BIOS 在机器首次启动时读取并启动的扇区。 主引导记录包含一个小程序,该程序读取分区表,检查哪个分区处于活动状态(即,标记为可引导),并读取该分区的第一个扇区,即分区的引导扇区(MBR 也是一个引导扇区,但它具有特殊的状态,因此具有特殊的名称)。 此引导扇区包含另一个小程序,该程序读取存储在该分区上的操作系统的第一部分(假设它是可引导的),然后启动它。
分区方案未内置到硬件,甚至未内置到 BIOS 中。 它只是许多操作系统遵循的约定。 并非所有操作系统都遵循它,但它们是例外。 一些操作系统支持分区,但它们占用硬盘上的一个分区,并在该分区内使用其内部分区方法。 后者可以与其他操作系统(包括 Linux)和平共存,并且不需要任何特殊措施,但是不支持分区的操作系统无法与任何其他操作系统在同一磁盘上共存。
作为安全预防措施,最好将分区表写在一张纸上,这样如果分区表损坏,您就不必丢失所有文件。(可以使用 fdisk修复损坏的分区表)。 相关信息由 fdisk -l 命令给出
$ fdisk -l /dev/hda Disk /dev/hda: 15 heads, 57 sectors, 790 cylinders Units = cylinders of 855 * 512 bytes Device Boot Begin Start End Blocks Id System /dev/hda1 1 1 24 10231+ 82 Linux swap /dev/hda2 25 25 48 10260 83 Linux native /dev/hda3 49 49 408 153900 83 Linux native /dev/hda4 409 409 790 163305 5 Extended /dev/hda5 409 409 744 143611+ 83 Linux native /dev/hda6 745 745 790 19636+ 83 Linux native $ |
5.9.2. 扩展分区和逻辑分区
PC 硬盘的原始分区方案仅允许四个分区。 事实证明,这在现实生活中很快就太少了,部分原因是有些人想要超过四个操作系统(Linux、MS-DOS、OS/2、Minix、FreeBSD、NetBSD 或 Windows/NT,仅举几例),但主要是因为有时为一个操作系统设置多个分区是一个好主意。 例如,出于速度原因(请参见下文),交换空间通常最好放在 Linux 自己的分区中,而不是放在主 Linux 分区中。
为了克服这个设计问题,发明了扩展分区。 此技巧允许将主分区划分为子分区。 因此,细分的主分区是扩展分区; 子分区是逻辑分区。 它们的行为类似于主分区,但是创建方式不同。 它们之间没有速度差异。 通过使用扩展分区,您现在每个磁盘最多可以有 15 个分区。
硬盘的分区结构可能看起来像 图 5-2 中所示。 磁盘被划分为三个主分区,其中第二个主分区被划分为两个逻辑分区。 部分磁盘根本没有分区。 整个磁盘和每个主分区都有一个引导扇区。
5.9.3. 分区类型
分区表(MBR 中的分区表和扩展分区的分区表)为每个分区包含一个字节,用于标识该分区的类型。 这尝试识别使用该分区的操作系统,或者它用于什么。 目的是使避免两个操作系统意外使用同一分区成为可能。 但是,实际上,操作系统并不真正关心分区类型字节; 例如,Linux 根本不关心它是什么。 更糟糕的是,它们中的一些使用不正确; 例如,至少某些版本的 DR-DOS 忽略该字节的最高有效位,而另一些则不忽略。
没有标准化机构来指定每个字节值的含义,但就 Linux 而言,这是 fdisk 程序的分区类型列表。
0 Empty 1c Hidden Win95 FA 70 DiskSecure Mult bb Boot Wizard hid 1 FAT12 1e Hidden Win95 FA 75 PC/IX be Solaris boot 2 XENIX root 24 NEC DOS 80 Old Minix c1 DRDOS/sec (FAT- 3 XENIX usr 39 Plan 9 81 Minix / old Lin c4 DRDOS/sec (FAT- 4 FAT16 <32M 3c PartitionMagic 82 Linux swap c6 DRDOS/sec (FAT- 5 Extended 40 Venix 80286 83 Linux c7 Syrinx 6 FAT16 41 PPC PReP Boot 84 OS/2 hidden C: da Non-FS data 7 HPFS/NTFS 42 SFS 85 Linux extended db CP/M / CTOS / . 8 AIX 4d QNX4.x 86 NTFS volume set de Dell Utility 9 AIX bootable 4e QNX4.x 2nd part 87 NTFS volume set df BootIt a OS/2 Boot Manag 4f QNX4.x 3rd part 8e Linux LVM e1 DOS access b Win95 FAT32 50 OnTrack DM 93 Amoeba e3 DOS R/O c Win95 FAT32 (LB 51 OnTrack DM6 Aux 94 Amoeba BBT e4 SpeedStor e Win95 FAT16 (LB 52 CP/M 9f BSD/OS eb BeOS fs f Win95 Ext'd (LB 53 OnTrack DM6 Aux a0 IBM Thinkpad hi ee EFI GPT 10 OPUS 54 OnTrackDM6 a5 FreeBSD ef EFI (FAT-12/16/ 11 Hidden FAT12 55 EZ-Drive a6 OpenBSD f0 Linux/PA-RISC b 12 Compaq diagnost 56 Golden Bow a7 NeXTSTEP f1 SpeedStor 14 Hidden FAT16 <3 5c Priam Edisk a8 Darwin UFS f4 SpeedStor 16 Hidden FAT16 61 SpeedStor a9 NetBSD f2 DOS secondary 17 Hidden HPFS/NTF 63 GNU HURD or Sys ab Darwin boot fd Linux raid auto 18 AST SmartSleep 64 Novell Netware b7 BSDI fs fe LANstep 1b Hidden Win95 FA 65 Novell Netware b8 BSDI swap ff BBT |
5.9.4. 硬盘分区
有许多程序可以创建和删除分区。 大多数操作系统都有自己的程序,最好使用每个操作系统自己的程序,以防万一它执行其他程序无法执行的任何异常操作。 许多程序都称为 fdisk,包括 Linux 的 fdisk,或其变体。 有关使用 Linux fdisk 的详细信息,请参阅其手册页。 cfdisk 命令类似于 fdisk,但具有更好的(全屏)用户界面。
在使用 IDE 硬盘时,启动分区(包含可启动内核镜像文件的分区)必须完全位于前 1024 个柱面内。这是因为在启动期间(系统进入保护模式之前),硬盘是通过 BIOS 使用的,而 BIOS 无法处理超过 1024 个柱面的情况。有时可以使用部分位于前 1024 个柱面内的启动分区。只要所有通过 BIOS 读取的文件都在前 1024 个柱面内,就可以正常工作。但是,由于这很难安排,因此非常不建议这样做;你永远不知道内核更新或磁盘碎片整理何时会导致系统无法启动。因此,请确保你的启动分区完全位于前 1024 个柱面内。
但是,对于支持 LBA(逻辑块寻址)的新版本 LILO 来说,情况可能不再如此。请查阅你的发行版的文档,以了解它是否具有支持 LBA 的 LILO 版本。
实际上,一些较新版本的 BIOS 和 IDE 硬盘可以处理超过 1024 个柱面的硬盘。如果你有这样的系统,你可以忘记这个问题;如果你不太确定,最好将它放在前 1024 个柱面内。
每个分区都应该有偶数个扇区,因为 Linux 文件系统使用 1 KB 的块大小,即两个扇区。奇数个扇区会导致最后一个扇区未使用。这不会导致任何问题,但不太美观,并且某些版本的 fdisk 会发出警告。
更改分区大小通常需要先备份你想从该分区保存的所有内容(最好是整个磁盘,以防万一),删除该分区,创建新分区,然后将所有内容恢复到新分区。如果分区正在增大,你可能还需要调整相邻分区的大小(并备份和恢复)。
由于更改分区大小很麻烦,因此最好一开始就正确地配置分区,或者拥有一个有效且易于使用的备份系统。如果你是从不需要太多人工干预的介质(例如 CD-ROM,而不是软盘)安装,通常很容易在一开始就尝试不同的配置。由于你还没有需要备份的数据,因此多次修改分区大小并不那么痛苦。
有一个用于 MS-DOS 的程序,称为 fips,它可以调整 MS-DOS 分区的大小,而无需备份和恢复,但对于其他文件系统,仍然需要这样做。
fips 程序包含在大多数 Linux 发行版中。商业分区管理器“Partition Magic”也具有类似的功能,但界面更好。请记住,分区是危险的。在尝试“动态”更改分区大小之前,务必对所有重要数据进行最近的备份。parted 程序也可以调整 MS-DOS 以及其他类型的分区大小,但有时方式有限。在使用 parted 之前,请查阅其文档,以防万一。
5.10. 文件系统
5.10.1. 什么是文件系统?
文件系统是操作系统用于跟踪磁盘或分区上的文件的方法和数据结构;也就是说,文件在磁盘上的组织方式。该词也用于指代用于存储文件的分区或磁盘,或文件系统的类型。因此,有人可能会说“我有两个文件系统”,意思是他们有两个用于存储文件的分区,或者他们正在使用“扩展文件系统”,意思是文件系统的类型。
磁盘或分区与其包含的文件系统之间的区别很重要。一些程序(包括,合理地,创建文件系统的程序)直接在磁盘或分区的原始扇区上运行;如果那里存在现有的文件系统,它将被销毁或严重损坏。大多数程序都在文件系统上运行,因此无法在不包含文件系统(或包含错误类型的文件系统)的分区上运行。
在分区或磁盘可以用作文件系统之前,需要对其进行初始化,并将记账数据结构写入磁盘。此过程称为创建文件系统。
大多数 UNIX 文件系统类型都有类似的总体结构,尽管确切的细节差异很大。中心概念是超级块、inode、数据块、目录块和间接块。超级块包含有关整个文件系统的信息,例如其大小(这里的确切信息取决于文件系统)。inode 包含有关文件的所有信息,除了它的名称。该名称存储在目录中,以及 inode 的编号。目录条目由文件名和表示该文件的 inode 编号组成。inode 包含几个数据块的编号,这些数据块用于存储文件中的数据。但是,inode 中只有几个数据块编号的空间,如果需要更多,则会动态分配更多用于指向数据块的指针的空间。这些动态分配的块是间接块;名称表示为了找到数据块,必须首先在间接块中找到其编号。
UNIX 文件系统通常允许在文件中创建空洞(这是通过lseek()系统调用完成的;查看手册页),这意味着文件系统只是假装在文件的特定位置只有零字节,但没有为文件中的该位置保留实际的磁盘扇区(这意味着该文件将使用更少的磁盘空间)。这在小型二进制文件、Linux 共享库、一些数据库以及其他一些特殊情况下经常发生。(空洞是通过在间接块或 inode 中存储一个特殊值作为数据块的地址来实现的。这个特殊的地址意味着没有为文件的该部分分配数据块,因此,文件中存在一个空洞。)
5.10.2. 文件系统大全
Linux 支持多种类型的文件系统。在撰写本文时,最重要的文件系统是
- minix
最古老的,被认为是可靠性最高的,但功能非常有限(缺少一些时间戳,最多 30 个字符的文件名)并且功能受到限制(每个文件系统最多 64 MB)。
- xia
minix 文件系统的修改版本,取消了文件名和文件系统大小的限制,但没有引入其他新功能。它不是很受欢迎,但据报道工作得很好。
- ext3
ext3 文件系统具有 ext2 文件系统的所有功能。不同之处在于,添加了日志功能。这提高了系统崩溃时的性能和恢复时间。这已经比 ext2 更受欢迎。
- ext2
本机 Linux 文件系统中功能最丰富的。它被设计成易于向上兼容,因此新版本的文件系统代码不需要重新制作现有的文件系统。
- ext
ext2 的旧版本,不向上兼容。它几乎不再用于新的安装中,并且大多数人已经转换为 ext2。
- reiserfs
更健壮的文件系统。使用日志功能,这使得数据丢失的可能性降低。日志功能是一种机制,通过该机制来记录要执行或已执行的事务。这允许文件系统在受到例如不正确的关机造成的损坏后,能够相当容易地重建自身。
- jfs
JFS 是 IBM 设计的日志文件系统,用于在高性能环境中使用。
- xfs
XFS 最初由 Silicon Graphics 设计,用作 64 位日志文件系统。XFS 还旨在保持大型文件和文件系统的高性能。
此外,还存在对几种外部文件系统的支持,以便更容易与其他操作系统交换文件。这些外部文件系统的工作方式与本机文件系统相同,只是它们可能缺少一些常用的 UNIX 功能,或者具有奇怪的限制或其他怪癖。
- msdos
与 MS-DOS(以及 OS/2 和 Windows NT)FAT 文件系统的兼容性。
- umsdos
扩展了 Linux 下的 msdos 文件系统驱动程序,以获得长文件名、所有者、权限、链接和设备文件。这允许将正常的 msdos 文件系统用作 Linux 文件系统,从而消除了为 Linux 单独分区的需要。
- vfat
这是 FAT 文件系统的一个扩展,称为 FAT32。它支持比 FAT 更大的磁盘大小。大多数 MS Windows 磁盘都是 vfat。
- iso9660
标准的 CD-ROM 文件系统;自动支持流行的 Rock Ridge CD-ROM 标准扩展,该扩展允许更长的文件名。
- nfs
一种网络文件系统,允许在多台计算机之间共享文件系统,以便从所有计算机轻松访问这些文件。
- smbfs
一种网络文件系统,允许与 MS Windows 计算机共享文件系统。它与 Windows 文件共享协议兼容。
- hpfs
OS/2 文件系统。
- sysv
SystemV/386、Coherent 和 Xenix 文件系统。
- NTFS
最先进的 Microsoft 日志文件系统,与以前的 Microsoft 文件系统相比,提供更快的文件访问和稳定性。
要使用的文件系统的选择取决于具体情况。如果出于兼容性或其他原因需要使用非本机文件系统之一,则必须使用该文件系统。如果可以自由选择,那么使用 ext3 可能是最明智的,因为它具有 ext2 的所有功能,并且是日志文件系统。有关文件系统的更多信息,请参见第 5.10.6 节。你还可以阅读位于 http://www.tldp.org/HOWTO/Filesystems-HOWTO.html 的文件系统 HOWTO。
还有 proc 文件系统,通常可以作为/proc目录(directory)实际上根本不是一个文件系统,即使它看起来很像。proc 文件系统使得访问特定的内核数据结构变得容易,例如进程列表(因此得名)。它将这些数据结构看起来像一个文件系统,并且可以使用所有常用的文件工具来操作该文件系统。 例如,要获取所有进程的列表,可以使用以下命令
$ ls -l /proc total 0 dr-xr-xr-x 4 root root 0 Jan 31 20:37 1 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 63 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 94 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 95 dr-xr-xr-x 4 root users 0 Jan 31 20:37 98 dr-xr-xr-x 4 liw users 0 Jan 31 20:37 99 -r--r--r-- 1 root root 0 Jan 31 20:37 devices -r--r--r-- 1 root root 0 Jan 31 20:37 dma -r--r--r-- 1 root root 0 Jan 31 20:37 filesystems -r--r--r-- 1 root root 0 Jan 31 20:37 interrupts -r-------- 1 root root 8654848 Jan 31 20:37 kcore -r--r--r-- 1 root root 0 Jan 31 11:50 kmsg -r--r--r-- 1 root root 0 Jan 31 20:37 ksyms -r--r--r-- 1 root root 0 Jan 31 11:51 loadavg -r--r--r-- 1 root root 0 Jan 31 20:37 meminfo -r--r--r-- 1 root root 0 Jan 31 20:37 modules dr-xr-xr-x 2 root root 0 Jan 31 20:37 net dr-xr-xr-x 4 root root 0 Jan 31 20:37 self -r--r--r-- 1 root root 0 Jan 31 20:37 stat -r--r--r-- 1 root root 0 Jan 31 20:37 uptime -r--r--r-- 1 root root 0 Jan 31 20:37 version $ |
请注意,即使它被称为文件系统,proc 文件系统的任何部分都不会触及任何磁盘。它只存在于内核的想象中。 无论何时有人试图查看 proc 文件系统的任何部分,内核都会使其看起来好像该部分存在于某个地方,即使它不存在。 因此,即使有一个多兆字节的/proc/kcore文件,它也不会占用任何磁盘空间。
5.10.3. 应该使用哪个文件系统?
通常,使用许多不同的文件系统没有意义。目前,ext3 是最流行的文件系统,因为它是一个日志文件系统(journaled filesystem)。 目前,它可能是最明智的选择。 Reiserfs 是另一个流行的选择,因为它也是日志文件系统。 根据记账结构的开销、速度、(感知的)可靠性、兼容性以及各种其他原因,建议使用另一个文件系统。 这需要根据具体情况决定。
使用日志记录的文件系统也称为日志文件系统。 日志文件系统维护一个日志,或称“日志(journal)”,记录文件系统中发生的事情。 如果系统崩溃,或者你两岁的儿子像我的孩子一样喜欢按电源按钮,日志文件系统旨在利用文件系统的日志来重新创建未保存和丢失的数据。 这使得数据丢失的可能性大大降低,并且可能会成为 Linux 文件系统中的标准功能。 但是,不要因此产生虚假的安全感。 像其他所有事物一样,也可能出现错误。 始终确保备份你的数据,以防发生紧急情况。
有关不同文件系统类型的功能的更多详细信息,请参见第 5.10.6 节。
5.10.4. 创建文件系统
文件系统是使用 mkfs 命令创建的,即初始化的。 实际上,每种文件系统类型都有一个单独的程序。 mkfs 只是一个前端,它根据所需的文件系统类型运行相应的程序。 该类型使用-t fstype选项来选择。
mkfs 调用的程序具有略有不同的命令行界面。 下面总结了常用的和最重要的选项; 更多信息请参见手册页。
- -t fstype
选择文件系统的类型。
- -c
搜索坏块并相应地初始化坏块列表。
- -l filename
从名称文件读取初始坏块列表。
还有许多程序被编写出来,用于在创建特定文件系统时添加特定的选项。 例如,mkfs.ext3 添加一个 -b 选项,允许管理员指定应该使用哪个块大小。 请务必查明是否有可用于你要使用的文件系统类型的特定程序。 有关确定使用哪个块大小的更多信息,请参见第 5.10.5 节。
要在软盘上创建一个 ext2 文件系统,可以给出以下命令
$ fdformat -n /dev/fd0H1440 Double-sided, 80 tracks, 18 sec/track. Total capacity 1440 KB. Formatting ... done $ badblocks /dev/fd0H1440 1440 $>$ bad-blocks $ mkfs.ext2 -l bad-blocks /dev/fd0H1440 mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 360 inodes, 1440 blocks 72 blocks (5.00%) reserved for the super user First data block=1 Block size=1024 (log=0) Fragment size=1024 (log=0) 1 block group 8192 blocks per group, 8192 fragments per group 360 inodes per group Writing inode tables: done Writing superblocks and filesystem accounting information: done $ |
的-c选项可以与 mkfs 一起使用,而不是 badblocks 和一个单独的文件。 下面的例子就是这样做的。
$ mkfs.ext2 -c /dev/fd0H1440 mke2fs 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 360 inodes, 1440 blocks 72 blocks (5.00%) reserved for the super user First data block=1 Block size=1024 (log=0) Fragment size=1024 (log=0) 1 block group 8192 blocks per group, 8192 fragments per group 360 inodes per group Checking for bad blocks (read-only test): done Writing inode tables: done Writing superblocks and filesystem accounting information: done $ |
在硬盘或分区上准备文件系统的过程与软盘相同,只是不需要格式化。
5.10.5. 文件系统块大小
块大小指定文件系统将用于读取和写入数据的大小。 当使用大型文件(例如数据库)时,较大的块大小将有助于提高磁盘 I/O 性能。 这是因为磁盘可以在不得不搜索下一个块之前读取或写入数据更长的时间。
不利的一面是,如果你要在该文件系统上存放大量较小的文件,例如/etc,那么可能会浪费大量磁盘空间。
例如,如果你将块大小设置为 4096,即 4K,并且你创建一个大小为 256 字节的文件,它仍将占用硬盘上的 4K 空间。 对于一个文件来说,这似乎微不足道,但是当你的文件系统包含数百或数千个文件时,这可能会累积起来。
块大小还会影响某些文件系统上支持的最大文件大小。 这是因为许多现代文件系统不是受块大小或文件大小限制,而是受块数量限制。 因此,你将使用“块大小 * 最大块数 = 最大块大小”公式。
5.10.6. 文件系统比较
表 5-1. 文件系统功能比较
| 文件系统名称 | 引入年份 | 原始操作系统 | 最大文件大小 | 最大文件系统大小 | 日志记录 |
|---|---|---|---|---|---|
| FAT16 | 1983 | MSDOS V2 | 4GB | 16MB 到 8GB | 否 |
| FAT32 | 1997 | Windows 95 | 4GB | 8GB 到 2TB | 否 |
| HPFS | 1988 | OS/2 | 4GB | 2TB | 否 |
| NTFS | 1993 | Windows NT | 16EB | 16EB | 是 |
| HFS+ | 1998 | Mac OS | 8EB | ? | 否 |
| UFS2 | 2002 | FreeBSD | 512GB 到 32PB | 1YB | 否 |
| ext2 | 1993 | Linux | 16GB 到 2TB4 | 2TB 到 32TB | 否 |
| ext3 | 1999 | Linux | 16GB 到 2TB4 | 2TB 到 32TB | 是 |
| ReiserFS3 | 2001 | Linux | 8TB8 | 16TB | 是 |
| ReiserFS4 | 2005 | Linux | ? | ? | 是 |
| XFS | 1994 | IRIX | 9EB | 9EB | 是 |
| JFS | ? | AIX | 8EB | 512TB 到 4PB | 是 |
| VxFS | 1991 | SVR4.0 | 16EB | ? | 是 |
| ZFS | 2004 | Solaris 10 | 1YB | 16EB | 否 |
图例
表 5-2. 大小
| 千字节 - KB | 1024 字节 |
| 兆字节 - MB | 1024 KB |
| 千兆字节 - GB | 1024 MB |
| 太字节 - TB | 1024 GB |
| 拍字节 - PB | 1024 TB |
| 艾字节 - EB | 1024 PB |
| 泽字节 - ZB | 1024 EB |
| 尧字节 - YB | 1024 ZB |
应该注意的是,艾字节、泽字节和尧字节很少遇到,甚至从未遇到过。 目前估计,世界上印刷材料的总量相当于 5 艾字节。 因此,许多人认为这些文件系统限制是理论上的。 但是,文件系统软件已经编写了具有这些功能。
有关更多详细信息,您可以访问http://en.wikipedia.org/wiki/Comparison_of_file_systems。
5.10.7. 挂载和卸载
在使用文件系统之前,必须先挂载它。 然后,操作系统会执行各种记账操作,以确保一切正常工作。 由于 UNIX 中的所有文件都在单个目录树中,因此挂载操作会使新文件系统的内容看起来像是某些已挂载文件系统中现有子目录的内容。
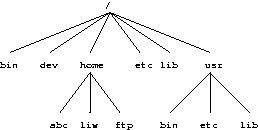
例如,图 5-3 显示了三个单独的文件系统,每个文件系统都有自己的根目录。 当最后两个文件系统分别挂载在/home和/usr下时,我们可以在第一个文件系统上获得单个目录树,如图 5-4 中所示。
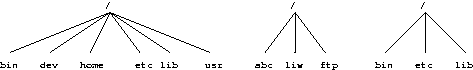
挂载可以按照以下示例完成
$ mount /dev/hda2 /home $ mount /dev/hda3 /usr $ |
Linux 支持多种文件系统类型。 mount 尝试猜测文件系统的类型。 你也可以使用-t fstype选项直接指定类型; 有时这是必要的,因为 mount 使用的启发式方法并不总是有效。 例如,要挂载 MS-DOS 软盘,你可以使用以下命令
$ mount -t msdos /dev/fd0 /floppy $ |
挂载的目录不需要为空,尽管它必须存在。 但是,当文件系统挂载时,其中的任何文件都将无法按名称访问。 (已经打开的任何文件仍然可以访问。从其他目录有硬链接的文件可以使用这些名称访问。) 这没有任何危害,甚至可能很有用。 例如,有些人喜欢使/tmp和/var/tmp同义,并使/tmp成为指向/var/tmp的符号链接。 当系统启动时,在/var文件系统挂载之前,将使用根文件系统上的/var/tmp目录。 当/var挂载时,它将使根文件系统上的/var/tmp目录无法访问。 如果/var/tmp在根文件系统上不存在,则在挂载/var.
如果你不打算向文件系统写入任何内容,请使用 mount 的-r开关执行只读挂载。 这将使内核停止任何写入文件系统的尝试,并且还将阻止内核更新 inode 中的文件访问时间。 只读挂载对于不可写介质(例如,CD-ROM)是必需的。
细心的读者已经注意到一个细微的后勤问题。 第一个文件系统(称为根文件系统,因为它包含根目录)是如何挂载的,因为它显然不能挂载在另一个文件系统上? 好吧,答案是它通过魔法完成的。 根文件系统在启动时被神奇地挂载,并且可以依赖它始终被挂载。 如果无法挂载根文件系统,则系统无法启动。 作为根目录神奇挂载的文件系统的名称要么编译到内核中,要么使用 LILO 或 rdev 设置。
有关更多信息,请参见内核源代码或 Kernel Hackers' Guide。
根文件系统通常首先以只读方式挂载。 然后启动脚本将运行 fsck 以验证其有效性,如果没有问题,它们将重新挂载它,以便也允许写入。 fsck 不得在挂载的文件系统上运行,因为在 fsck 运行时对文件系统进行的任何更改都将引起麻烦。 由于根文件系统在被检查时以只读方式挂载,因此 fsck 可以放心地修复任何问题,因为重新挂载操作将刷新文件系统保存在内存中的任何元数据。
在许多系统上,还有其他文件系统也应在启动时自动挂载。 这些在/etc/fstab文件中指定; 有关格式的详细信息,请参见 fstab 手册页。 额外文件系统何时挂载的确切细节取决于许多因素,并且可以由每个管理员根据需要进行配置; 请参见第 8 章。
当文件系统不再需要挂载时,可以使用 umount 命令来卸载它。umount 命令接受一个参数:设备文件或挂载点。例如,要卸载前面例子中的目录,可以使用以下命令:
$ umount /dev/hda2 $ umount /usr $ |
请参阅 man 手册以获取有关如何使用该命令的更多说明。 务必始终卸载已挂载的软盘。 不要直接弹出软盘! 由于磁盘缓存,数据不一定会在卸载之前写入软盘,因此过早地从驱动器中取出软盘可能会导致内容损坏。 如果您只是从软盘读取数据,则不太可能发生这种情况,但如果您写入数据,即使是意外写入,也可能导致灾难性后果。
挂载和卸载需要超级用户权限,即只有 root 用户才能执行。原因是,如果任何用户都可以将软盘挂载到任何目录上,那么很容易创建一个软盘,其中包含伪装成/bin/sh或任何其他常用程序的特洛伊木马。 但是,通常需要允许用户使用软盘,并且有几种方法可以做到这一点
将 root 密码提供给用户。 显然,这很糟糕的安全性,但这是最简单的解决方案。 如果无论如何都不需要安全性,那么它工作得很好,这在许多非联网的个人系统中都是如此。
使用诸如 sudo 之类的程序来允许用户使用 mount。 这仍然是很糟糕的安全性,但不会直接向所有人授予超级用户权限。 它需要用户进行几秒钟的认真思考。 此外,sudo 可以配置为仅允许用户执行某些命令。 请参阅 sudo(8)、sudoers(5) 和 visudo(8) 手册页。
让用户使用 mtools,这是一个用于操作 MS-DOS 文件系统而无需挂载它们的软件包。 如果只需要 MS-DOS 软盘,这很好用,否则会很麻烦。
列出软盘设备及其允许的挂载点以及/etc/fstab.
/dev/fd0 /floppy msdos user,noauto 0 0 |
的noauto选项阻止在系统启动时自动执行此挂载(即,它阻止 mount -a 挂载它)。user选项允许任何用户挂载文件系统,并且出于安全原因,禁止从已挂载的文件系统中执行程序(普通程序或 setuid 程序)和解释设备文件。 之后,任何用户都可以使用以下命令挂载带有 msdos 文件系统的软盘:
$ mount /floppy $ |
如果要提供对多种类型的软盘的访问权限,则需要提供多个挂载点。 每个挂载点的设置可以不同。 例如,为了提供对 MS-DOS 和 ext2 软盘的访问权限,您可以拥有以下行:/etc/fstab:
/dev/fd0 /mnt/dosfloppy msdos user,noauto 0 0 /dev/fd0 /mnt/ext2floppy ext2 user,noauto 0 0 |
/dev/fd0 /mnt/floppy auto user,noauto 0 0
|
对于 MS-DOS 文件系统(不仅仅是软盘),您可能希望使用uid, gid,和umask文件系统选项来限制对其的访问,这些选项在 mount 手册页上有详细描述。 如果不小心,挂载 MS-DOS 文件系统会使每个人至少可以读取其中的文件,这不是一个好主意。
5.10.9. 使用 fsck 检查文件系统完整性
文件系统是复杂的生物,因此,它们往往容易出错。 可以使用 fsck 命令检查文件系统的正确性和有效性。 可以指示它修复它发现的任何小问题,并在出现任何无法修复的问题时提醒用户。 幸运的是,实现文件系统的代码经过了非常有效的调试,因此很少出现任何问题,并且它们通常是由电源故障、硬件故障或操作员错误引起的; 例如,未正确关闭系统。
大多数系统都设置为在启动时自动运行 fsck,以便在系统使用之前检测到(并希望得到纠正)任何错误。 使用损坏的文件系统往往会使情况变得更糟:如果数据结构搞砸了,使用文件系统可能会使它们更加混乱,从而导致更多的数据丢失。 但是,fsck 在大型文件系统上可能需要一段时间才能运行,并且由于如果系统已正确关闭,几乎永远不会发生错误,因此会使用一些技巧来避免在这些情况下进行检查。 首先是,如果文件/etc/fastboot存在,则不进行检查。 第二个是,ext2 文件系统在其超级块中有一个特殊的标记,该标记指示文件系统在上一次挂载后是否已正确卸载。 这允许 e2fsck(fsck 的 ext2 文件系统版本)避免检查文件系统,如果该标志指示已完成卸载(假设正确的卸载表示没有问题)。/etc/fastboot技巧是否在您的系统上有效取决于您的启动脚本,但是每次使用 e2fsck 时,ext2 技巧都有效。 必须使用 e2fsck 的选项显式绕过它才能避免。(有关详细信息,请参阅 e2fsck 手册页。)
自动检查仅适用于在启动时自动挂载的文件系统。 手动使用 fsck 检查其他文件系统,例如,软盘。
如果 fsck 发现无法修复的问题,您需要深入了解文件系统的工作原理,尤其是损坏的文件系统的类型,或者需要良好的备份。 后者很容易(尽管有时很繁琐)安排,前者有时可以通过朋友、Linux 新闻组和邮件列表或其他支持来源来安排,如果您自己没有专业知识。 我想告诉您更多有关它的信息,但我在这一方面的教育和经验不足妨碍了我。 Theodore Ts'o 的 debugfs 程序应该很有用。
fsck 只能在未挂载的文件系统上运行,永远不能在已挂载的文件系统上运行(除了启动期间的只读根文件系统)。 这是因为它访问原始磁盘,因此可以在操作系统未意识到的情况下修改文件系统。 如果操作系统感到困惑,将会出现问题。
5.10.10. 使用 badblocks 检查磁盘错误
定期检查坏块可能是一个好主意。 这是使用 badblocks 命令完成的。 它输出它可以找到的所有坏块的编号列表。 此列表可以提供给 fsck,以记录在文件系统数据结构中,以便操作系统不会尝试使用坏块来存储数据。 以下示例将说明如何执行此操作。
$ badblocks /dev/fd0H1440 1440 > bad-blocks $ fsck -t ext2 -l bad-blocks /dev/fd0H1440 Parallelizing fsck version 0.5a (5-Apr-94) e2fsck 0.5a, 5-Apr-94 for EXT2 FS 0.5, 94/03/10 Pass 1: Checking inodes, blocks, and sizes Pass 2: Checking directory structure Pass 3: Checking directory connectivity Pass 4: Check reference counts. Pass 5: Checking group summary information. /dev/fd0H1440: ***** FILE SYSTEM WAS MODIFIED ***** /dev/fd0H1440: 11/360 files, 63/1440 blocks $ |
5.10.11. 对抗碎片?
当文件写入磁盘时,它不能总是写入连续的块。 未存储在连续块中的文件是碎片化的。 读取碎片化的文件需要更长的时间,因为磁盘的读写头将需要移动更多。 避免碎片化是可取的,尽管在具有良好缓冲缓存和预读的系统中,它不是一个大问题。
现代 Linux 文件系统通过将文件中的所有块保持在一起,即使它们无法存储在连续的扇区中,也可以将碎片保持在最低限度。 某些文件系统(如 ext3)有效地分配最靠近文件中其他块的空闲块。 因此,无需担心 Linux 系统中的碎片化。
在 ext2 文件系统的早期,人们担心文件碎片化,从而导致开发了一个名为 defrag 的碎片整理程序。 仍然可以在 http://www.go.dlr.de/linux/src/defrag-0.73.tar.gz 下载它的副本。 但是,强烈建议您不要使用它。 它是为较旧版本的 ext2 设计的,并且自 1998 年以来一直没有更新! 我在这里提到它仅用于参考目的。
有许多 MS-DOS 碎片整理程序可以在文件系统中移动块以消除碎片。 对于其他文件系统,必须通过备份文件系统、重新创建它并从备份还原文件来完成碎片整理。 在进行碎片整理之前备份文件系统对于所有文件系统都是一个好主意,因为在碎片整理过程中可能会出现很多问题。
5.10.12. 所有文件系统的其他工具
一些其他工具对于管理文件系统也很有用。df 显示一个或多个文件系统上的可用磁盘空间; du 显示一个目录及其所有文件包含多少磁盘空间。 这些可用于查找磁盘空间浪费者。 两者都有详细说明可用的(许多)选项的手册页。
sync 强制将缓冲区缓存中的所有未写入的块(请参阅第 6.6 节)写入磁盘。 很少需要手动执行此操作; 守护程序进程 update 会自动执行此操作。 它在灾难中很有用,例如,如果 update 或其辅助进程 bdflush 死亡,或者您必须立即关闭电源,并且无法等待 update 运行。 同样,有手册页。 在 Linux 中,man 是您最好的朋友。 当您不知道要查找的命令的名称时,它的表弟 apropos 也非常有用。
5.10.13. ext2/ext3 文件系统的其他工具
除了可以通过文件系统类型独立的接口直接访问的文件系统创建器 (mke2fs) 和检查器 (e2fsck) 之外,ext2 文件系统还有一些其他可能有用的工具。
tune2fs 调整文件系统参数。 一些更有趣的参数是
最大挂载计数。 e2fsck 即使设置了 clean 标志,也会在文件系统挂载次数过多时强制检查。 对于用于开发或测试系统的系统,最好降低此限制。
两次检查之间的最大时间。 e2fsck 还可以强制执行两次检查之间的最大时间,即使设置了 clean 标志并且文件系统挂载的次数不多。 但是,可以禁用此功能。
为 root 保留的块数。 Ext2 为 root 保留了一些块,以便如果文件系统已满,仍然可以进行系统管理,而无需删除任何内容。 默认情况下,保留的量为 5%,这在大多数磁盘上都不足以浪费。 但是,对于软盘,保留任何块都没有意义。
dumpe2fs 显示有关 ext2 或 ext3 文件系统的信息,主要是来自超级块的信息。 以下是示例输出。 输出中的一些信息是技术性的,需要了解文件系统的工作方式,但即使对于非专业管理员来说,其中大部分也很容易理解。
# dumpe2fs dumpe2fs 1.32 (09-Nov-2002) Filesystem volume name: / Last mounted on: not available Filesystem UUID: 51603f82-68f3-4ae7-a755-b777ff9dc739 Filesystem magic number: 0xEF53 Filesystem revision #: 1 (dynamic) Filesystem features: has_journal filetype needs_recovery sparse_super Default mount options: (none) Filesystem state: clean Errors behavior: Continue Filesystem OS type: Linux Inode count: 3482976 Block count: 6960153 Reserved block count: 348007 Free blocks: 3873525 Free inodes: 3136573 First block: 0 Block size: 4096 Fragment size: 4096 Blocks per group: 32768 Fragments per group: 32768 Inodes per group: 16352 Inode blocks per group: 511 Filesystem created: Tue Aug 26 08:11:55 2003 Last mount time: Mon Dec 22 08:23:12 2003 Last write time: Mon Dec 22 08:23:12 2003 Mount count: 3 Maximum mount count: -1 Last checked: Mon Nov 3 11:27:38 2003 Check interval: 0 (none) Reserved blocks uid: 0 (user root) Reserved blocks gid: 0 (group root) First inode: 11 Inode size: 128 Journal UUID: none Journal inode: 8 Journal device: 0x0000 First orphan inode: 655612 Group 0: (Blocks 0-32767) Primary superblock at 0, Group descriptors at 1-2 Block bitmap at 3 (+3), Inode bitmap at 4 (+4) Block bitmap at 3 (+3), Inode bitmap at 4 (+4) Inode table at 5-515 (+5) 3734 free blocks, 16338 free inodes, 2 directories |
debugfs 是一个文件系统调试器。它允许直接访问存储在磁盘上的文件系统数据结构,因此可以用来修复那些 fsck 无法自动修复的损坏磁盘。它也常被用于恢复已删除的文件。然而,使用 debugfs 需要你非常清楚自己在做什么;如果理解不够,可能会破坏所有数据。
dump 和 restore 可用于备份 ext2 文件系统。它们是传统 UNIX 备份工具的 ext2 特定版本。有关备份的更多信息,请参阅 第 12.1 节。
5.11. 没有文件系统的磁盘
并非所有磁盘或分区都用作文件系统。例如,交换分区上不会有文件系统。许多软盘以磁带驱动器模拟的方式使用,因此 tar(磁带归档)或其他文件直接写入原始磁盘,而没有文件系统。Linux 启动软盘不包含文件系统,只有原始内核。
避免使用文件系统的好处是可以使更多磁盘可用,因为文件系统总会产生一些记账开销。这也使得磁盘更容易与其他系统兼容:例如,tar 文件格式在所有系统上都是相同的,而文件系统在大多数系统上都是不同的。如果你需要它们,你很快就会习惯没有文件系统的磁盘。可引导的 Linux 软盘也不一定有文件系统,尽管它们可能有。
使用原始磁盘的一个原因是制作它们的镜像副本。例如,如果磁盘包含部分损坏的文件系统,最好在尝试修复之前制作一个精确的副本,这样如果你的修复导致情况变得更糟,你可以重新开始。一种方法是使用 dd
$ dd if=/dev/fd0H1440 of=floppy-image 2880+0 records in 2880+0 records out $ dd if=floppy-image of=/dev/fd0H1440 2880+0 records in 2880+0 records out $ |
5.12. 分配磁盘空间
5.12.1. 分区方案
在分区你的机器时,没有普遍正确的方法。根据机器的用途,必须考虑许多因素。
对于磁盘空间有限的简单工作站(例如笔记本电脑),你可能只有 3 个分区。一个分区用于/, /boot,以及交换分区。但是,对于大多数用户来说,这不是一个推荐的解决方案。
传统的方式是拥有一个(相对)较小的根文件系统,以及用于文件系统的单独分区,例如/usr和/home>。如果根文件系统很小并且不经常使用,则创建一个单独的根文件系统,当系统崩溃时,它不太可能被破坏,因此更容易恢复崩溃的系统。原因是防止根文件系统被填满并导致系统崩溃。
在创建分区方案时,你需要记住一些事情。你不能为以下目录创建单独的分区/bin, /etc, /dev, /initrd, /lib,和/sbin。这些目录的内容在启动时是必需的,并且必须始终是/分区的一部分。
还建议你为以下目录创建单独的分区/var和/tmp。这是因为这两个目录通常具有不断变化的数据。不为这些文件系统创建单独的分区会使你面临日志文件填满或/分区的一部分。
服务器分区的一个示例是
Filesystem Size Used Avail Use% Mounted on /dev/hda2 9.7G 1.3G 8.0G 14% / /dev/hda1 128M 44M 82M 34% /boot /dev/hda3 4.9G 4.0G 670M 86% /usr /dev/hda5 4.9G 2.1G 2.5G 46% /var /dev/hda7 31G 24G 5.6G 81% /home /dev/hda8 4.9G 2.0G 670M 43% /opt |
拥有许多分区的问题在于,它将总的可用磁盘空间分成许多小块。避免此问题的一种方法是使用 来创建逻辑卷。
5.12.2. 逻辑卷管理器 (LVM)
使用 LVM 允许管理员灵活地创建逻辑磁盘,这些逻辑磁盘可以在需要更多磁盘空间时动态扩展。
首先,通过创建分区类型为 0x8e Linux LVM 的分区来完成此操作。然后将物理分区添加到卷组中,并将其分成块或物理范围 卷组。然后可以将这些范围分组到逻辑卷中。然后可以像格式化物理分区一样格式化这些逻辑卷。最大的区别在于,它们可以通过向其中添加更多范围来扩展。
目前,对 LVM 的全面讨论超出了本指南的范围。但是,可以在 http://www.tldp.org/HOWTO/LVM-HOWTO.html 找到一个关于学习 LVM 的优秀资源。
5.12.3. 空间需求
你安装的 Linux 发行版将提供一些关于各种配置需要多少磁盘空间的指示。单独安装的程序也可能会这样做。这将有助于你规划磁盘空间的使用,但你应该为未来做好准备,并为以后注意到你需要的东西保留一些额外的空间。
用户文件所需的数量取决于你的用户希望做什么。大多数人似乎需要尽可能多的空间来存放他们的文件,但他们乐于接受的数量差异很大。有些人只进行轻量级的文本处理,并且可以用几兆字节很好地生存,而另一些人进行大量的图像处理,并且需要千兆字节。
顺便说一句,当比较以千字节或兆字节给出的文件大小和以兆字节给出的磁盘空间时,重要的是要知道这两个单位可能不同。一些磁盘制造商喜欢假装 1 千字节是 1000 字节,1 兆字节是 1000 千字节,而计算世界的其他部分都使用 1024 作为这两个因子。因此,345 MB 的硬盘实际上是 330 MB 的硬盘。
交换空间分配在第 6.5 节中讨论。
5.12.4. 硬盘分配示例
我以前有一个 10 GB 的硬盘。现在我使用 30 GB 的硬盘。我将解释我如何以及为什么对这些磁盘进行分区。
首先,我创建了一个/boot分区,大小为 128 MG。这比我需要的要大,而且足够大,如果我需要,我可以有空间。我创建了一个单独的/boot分区,以确保此文件系统永远不会被填满,因此可以启动。然后我创建了一个 5 GB 的/var分区。由于/var文件系统是存储日志文件和电子邮件的地方,我想将它与我的根分区隔离。(过去我曾遇到过日志文件在一夜之间增长并填满我的根文件系统的情况。)接下来,我创建了一个 15 GB 的/home分区。这在系统崩溃的情况下非常有用。如果我不得不从头开始重新安装 Linux,我可以告诉安装程序不要格式化此分区,而是重新挂载它而不会丢失数据。最后,由于我拥有 512 MG 的 RAM,因此我创建了一个 1024 MG(或 1 GB)的交换分区。这给我留下了大约 9 GB 的根文件系统。在使用我旧的 10 GB 硬盘时,我创建了一个 8 GB 的/usr分区,并留下了 2 GB 未使用。这是以防将来我需要更多空间。
最后,我的分区表看起来像这样
5.12.5. 为 Linux 添加更多磁盘空间
为 Linux 添加更多磁盘空间很容易,至少在硬件已正确安装后(硬件安装不在本书的范围内)。如果需要,您可以格式化它,然后如上所述创建分区和文件系统,并将适当的行添加到/etc/fstab以便自动挂载它。
5.12.6. 节省磁盘空间的技巧
节省磁盘空间的最佳技巧是避免安装不必要的程序。大多数 Linux 发行版都有一个选项,可以只安装它们包含的部分软件包,通过分析你的需求,你可能会注意到你不需要其中的大部分。这将有助于节省大量磁盘空间,因为许多程序都很大。即使你需要特定的软件包或程序,你可能也不需要它的全部。例如,一些在线文档可能是不必要的,GNU Emacs 的一些 Elisp 文件,X11 的一些字体或一些用于编程的库也是如此。
如果你无法卸载软件包,你可以考虑压缩。压缩程序(例如 gzip 或 zip)将压缩(和解压缩)单个文件或文件组。gzexe 系统将对用户不可见地压缩和解压缩程序(未使用的程序会被压缩,然后在被使用时解压缩)。实验性的 DouBle 系统将对文件系统中所有文件进行压缩,对使用它们的程序不可见。(如果你熟悉 MS-DOS 的 Stacker 或 Windows 的 DriveSpace 等产品,原理是相同的。)
另一种节省空间的方法是在格式化分区时特别小心。大多数现代文件系统都允许你指定块大小。块大小是文件系统将用于读取和写入数据的小块大小。当使用大型文件(例如数据库)时,较大的块大小将有助于提高磁盘 I/O 性能。这是因为磁盘可以在必须搜索下一个块之前读取或写入数据更长的时间。
第 6 章。内存管理
"Minnet, jag har tappat mitt minne, är jag svensk eller finne, kommer inte ihåg..." (Bosse Österberg)
瑞典饮酒歌,(粗略)翻译:“记忆,我失去了我的记忆。我是瑞典人还是芬兰人?我不记得了”
本节描述了 Linux 内存管理功能,即虚拟内存和磁盘缓冲区缓存。描述了其目的和工作原理,以及系统管理员需要考虑的事项。
6.1. 什么是虚拟内存?
Linux 支持虚拟内存,即将磁盘用作 RAM 的扩展,从而使可用内存的有效大小相应增长。内核会将当前未使用的内存块的内容写入硬盘,以便该内存可以用于其他目的。当再次需要原始内容时,它们将被读回内存。这一切对用户来说都是完全透明的;在 Linux 下运行的程序只看到更大的可用内存量,而不会注意到它们的部分内容不时地驻留在磁盘上。当然,读取和写入硬盘比使用真实内存慢(大约慢一千倍),因此程序运行速度没有那么快。硬盘上用作虚拟内存的部分称为交换空间。
Linux 可以使用文件系统中的普通文件或单独的分区作为交换空间。交换分区速度更快,但更容易更改交换文件的大小(无需重新分区整个硬盘,并可能从头开始安装所有内容)。当你确切知道需要多少交换空间时,你应该选择交换分区,但如果你不确定,你可以先使用交换文件,使用系统一段时间,这样你就可以了解你需要多少交换空间,然后在你确定其大小后创建一个交换分区。
你还应该知道,Linux 允许同时使用多个交换分区和/或交换文件。这意味着,如果你只是偶尔需要大量的交换空间,你可以设置一个额外的交换文件在这些时间,而不是一直分配全部的数量。
关于操作系统的术语说明:计算机科学通常区分交换 (swapping,将整个进程写入交换空间) 和分页 (paging,一次只写入固定大小的部分,通常为几千字节)。 分页通常更有效,这也是 Linux 所做的事情,但传统的 Linux 术语仍然谈论交换。
6.2. 创建交换空间
交换文件是一个普通文件;内核并不特殊对待它。 内核唯一关心的是它没有空洞,并且已准备好使用 mkswap 命令。 但是,它必须驻留在本地磁盘上;由于实现原因,它不能驻留在通过 NFS 挂载的文件系统中。
关于空洞的部分很重要。 交换文件会保留磁盘空间,以便内核可以快速换出页面,而无需执行为文件分配磁盘扇区时所需的所有操作。 内核仅使用已分配给文件的任何扇区。 因为文件中的空洞意味着没有分配磁盘扇区(对于文件中的该位置),所以内核尝试使用它们是不好的。
创建没有空洞的交换文件的一个好方法是通过以下命令
$ dd if=/dev/zero of=/extra-swap bs=1024 count=1024 1024+0 records in 1024+0 records out $ |
交换分区在任何方面也不是特殊的。 您可以像创建任何其他分区一样创建它;唯一的区别是它用作原始分区,也就是说,它根本不包含任何文件系统。 将交换分区标记为类型 82 (Linux 交换) 是一个好主意;即使对内核来说并非绝对必要,这也会使分区列表更清晰。
创建交换文件或交换分区后,您需要在其开头写入签名;其中包含一些管理信息,并由内核使用。 执行此操作的命令是 mkswap,使用方式如下
$ mkswap /extra-swap 1024 Setting up swapspace, size = 1044480 bytes $ |
使用 mkswap 时应非常小心,因为它不会检查该文件或分区是否用于其他用途。您可以使用 mkswap 轻松覆盖重要的文件和分区!幸运的是,您应该只需要在安装系统时使用 mkswap。
Linux 内存管理器将每个交换空间的大小限制为 2 GB。 但是,您可以同时使用最多 8 个交换空间,总共 16GB。
6.3. 使用交换空间
使用 swapon 启用初始化的交换空间。 此命令告诉内核可以使用交换空间。 交换空间的路径作为参数给出,因此要开始在临时交换文件上进行交换,可以使用以下命令。
$ swapon /extra-swap $ |
/dev/hda8 none swap sw 0 0 /swapfile none swap sw 0 0 |
您可以使用 free 监控交换空间的使用情况。 它会告诉你使用的交换空间总量。
$ free
total used free shared
buffers
Mem: 15152 14896 256 12404 2528
-/+ buffers: 12368 2784
Swap: 32452 6684 25768
$ |
最后一行 (Swap) 显示交换空间的类似信息。 如果此行全部为零,则您的交换空间未激活。
相同的信息可以通过 top 获取,或者使用 proc 文件系统中文件/proc/meminfo。 目前很难获取有关特定交换空间使用情况的信息。
可以使用 swapoff 从使用中删除交换空间。 通常不需要这样做,除非是临时交换空间。 交换空间中使用的任何页面都会首先交换到内存中;如果没有足够的物理内存来容纳它们,它们将被交换出去(到其他交换空间)。 如果没有足够的虚拟内存来容纳所有页面,Linux 将开始抖动;过一段时间后它应该会恢复,但与此同时系统不可用。 在从使用中删除交换空间之前,您应该检查(例如,使用 free)是否有足够的可用内存。
可以使用 swapoff -a 从使用中删除所有自动使用 swapon -a 的交换空间;它查看文件/etc/fstab以查找要删除的内容。 任何手动使用的交换空间将保持使用状态。
有时即使有很多可用物理内存,也会使用大量的交换空间。 例如,如果某一点需要交换,但后来占用大量物理内存的大型进程终止并释放了内存,则会发生这种情况。 换出的数据不会自动换入,直到需要它为止,因此物理内存可能会长时间保持空闲状态。 没有必要担心这一点,但知道发生了什么可能会令人感到安慰。
6.4. 与其他操作系统共享交换空间
虚拟内存内置于许多操作系统中。 由于它们仅在运行时才需要它,即永远不同时需要,因此除了当前正在运行的操作系统之外的所有操作系统的交换空间都被浪费了。 它们共享单个交换空间会更有效率。 这是可能的,但可能需要一些破解。 Tips-HOWTO,网址为 http://www.tldp.org/HOWTO/Tips-HOWTO.html,其中包含一些关于如何实现此操作的建议。
6.5. 分配交换空间
有些人会告诉你应该分配两倍于物理内存的交换空间,但这是一个虚假的规则。 以下是如何正确地做这件事
估计您的总内存需求。 这是您一次可能需要的最大内存量,即您想要同时运行的所有程序的内存要求的总和。 这可以通过同时运行您将来可能同时运行的所有程序来完成。
例如,如果你想运行 X,你应该为它分配大约 8 MB,gcc 需要几兆字节(有些文件需要异常大的量,高达几十兆字节,但通常大约四个就足够了),等等。 内核将自行使用大约一兆字节,通常的 shell 和其他小型实用程序可能几百千字节(比如一起一兆字节)。 没有必要试图精确,粗略的估计是可以的,但你可能想悲观一点。
请记住,如果有多个人同时使用该系统,他们都会消耗内存。 但是,如果两个人同时运行同一个程序,则总内存消耗通常不会翻倍,因为代码页和共享库只存在一次。
free 和 ps 命令对于估计内存需求很有用。
在步骤 1 中为估计添加一些安全性。这是因为对程序大小的估计可能是不正确的,因为您可能会忘记一些您想要运行的程序,并且为了确保您有一些额外的空间以防万一。 几兆字节应该没问题。(分配太多的交换空间比太少的交换空间要好,但没有必要过度分配并分配整个磁盘,因为未使用的交换空间是被浪费的空间;稍后会讨论添加更多交换空间。) 此外,由于处理偶数更好,您可以将该值向上舍入到下一个完整兆字节。
根据上述计算,您知道您总共需要多少内存。 因此,为了分配交换空间,您只需要从所需的总内存中减去物理内存的大小,您就知道您需要多少交换空间。(在某些版本的 UNIX 上,您还需要为物理内存的映像分配空间,因此步骤 2 中计算出的量是您需要的,你不应该做减法。)
如果计算出的交换空间比物理内存大很多(大于两倍以上),您可能应该投资更多的物理内存,否则性能会太低。
即使您的计算表明您不需要任何交换空间,也最好至少有一些交换空间。 Linux 会积极地使用交换空间,以便尽可能多地保持物理内存的空闲状态。 Linux 会换出未使用的内存页,即使该内存尚不需要用于任何其他用途。 这避免了在需要时等待交换:交换可以更早地完成,当磁盘处于空闲状态时。
交换空间可以分布在多个磁盘上。 这有时可以提高性能,具体取决于磁盘的相对速度和磁盘的访问模式。 您可能想尝试一些方案,但请注意,正确地进行实验非常困难。 您不应相信任何一种方案优于任何其他方案的说法,因为它并不总是正确的。
6.6. 缓冲缓存
与访问(实际)内存相比,从磁盘读取数据非常慢。此外,在相对较短的时间内多次读取磁盘的同一部分是很常见的。例如,人们可能首先读取一封电子邮件,然后在回复时将信件读入编辑器,然后在复制到文件夹时使邮件程序再次读取它。或者,考虑一下命令 ls 在具有许多用户的系统上运行的频率。通过仅从磁盘读取一次信息,然后将其保存在内存中直到不再需要,可以加快除第一次读取之外的所有读取。这被称为 磁盘缓冲,用于此目的的内存称为 缓冲区缓存。
不幸的是,由于内存是有限的,甚至是稀缺的资源,因此缓冲区缓存通常不够大(它无法容纳所有想要使用的数据)。当缓存填满时,未使用时间最长的数据将被丢弃,从而释放的内存用于新数据。
磁盘缓冲也适用于写入。一方面,写入的数据通常很快会被再次读取(例如,将源代码文件保存到文件,然后由编译器读取),因此将写入的数据放入缓存中是一个好主意。另一方面,仅将数据放入缓存中,而不是立即将其写入磁盘,写入程序的运行速度会更快。然后可以在后台完成写入,而不会降低其他程序的速度。
大多数操作系统都有缓冲区缓存(尽管它们可能被称为其他名称),但并非所有操作系统都按照上述原则工作。有些是 直写式:数据会立即写入磁盘(当然,它也保留在缓存中)。如果写入在稍后的时间完成,则缓存称为 回写式。回写式比直写式更有效,但更容易出错:如果机器崩溃,或者电源在糟糕的时刻被切断,或者在缓存中等待写入的数据被写入之前从磁盘驱动器中取出软盘,则缓存中的更改通常会丢失。这甚至可能意味着文件系统(如果存在)未完全正常工作,可能是因为未写入的数据包含对簿记信息的重要更改。
因此,在不使用正确的关机程序的情况下,切勿关闭电源,或者在软盘已卸载(如果已安装)或任何使用它的程序已发出完成信号并且软盘驱动器指示灯不再亮起之前,切勿从磁盘驱动器中取出软盘。 sync 命令 刷新缓冲区,即强制将所有未写入的数据写入磁盘,并且可以在想要确保一切都安全写入时使用。在传统的 UNIX 系统中,有一个名为 update 的程序在后台运行,它每 30 秒执行一次 sync,因此通常不需要使用 sync。 Linux 还有一个额外的守护进程 bdflush,它更频繁地执行不太完美的同步,以避免 sync 有时导致的因大量磁盘 I/O 引起的突然冻结。
在 Linux 下,bdflush 由 update 启动。通常没有理由担心它,但是如果 bdflush 由于某种原因而死掉,内核会发出警告,你应该手动启动它 (/sbin/update)。
缓存实际上不缓冲文件,而是缓冲块,块是磁盘 I/O 的最小单位(在 Linux 下,它们通常为 1 KB)。这样,目录、超级块、其他文件系统簿记数据和非文件系统磁盘也会被缓存。
缓存的有效性主要由其大小决定。一个小的缓存几乎没用:它将保存很少的数据,以至于所有缓存的数据在重新使用之前都从缓存中刷新。临界大小取决于读取和写入的数据量,以及访问相同数据的频率。唯一的方法是进行实验。
如果缓存的大小是固定的,那么太大也不是很好,因为这可能会使可用内存太小并导致交换(这也很慢)。为了最有效地利用实际内存,Linux 会自动将所有空闲 RAM 用于缓冲区缓存,但也会在程序需要更多内存时自动缩小缓存。
在 Linux 下,你无需执行任何操作即可使用缓存,它会完全自动进行。除了遵循正确的关机和删除软盘的程序外,你无需担心它。
第 7 章。系统监控
“那是管事佬对你的称呼!”海绵宝宝
系统管理员最重要的职责之一是监控他们的系统。作为系统管理员,你需要在任何给定时间找出系统上发生的事情。无论是当前使用的系统资源百分比、正在运行的命令还是谁已登录。本章将介绍如何监控你的系统,并在某些情况下,如何解决可能出现的问题。
当出现性能问题时,需要考虑 4 个主要领域:CPU、内存、磁盘 I/O 和网络。确定瓶颈所在的能力可以节省你大量时间。
7.1. 系统资源
能够监控系统的性能至关重要。如果系统资源变得太低,可能会导致很多问题。系统资源可能被单个用户占用,或者被你的系统可能托管的服务(例如电子邮件或网页)占用。了解正在发生的事情的能力可以帮助确定是否需要系统升级,或者是否需要将某些服务移动到另一台计算机。
7.1.1. top 命令。
这些命令中最常见的是 top。top 将显示一个持续更新的系统资源使用情况报告。
# top
12:10:49 up 1 day, 3:47, 7 users, load average: 0.23, 0.19, 0.10
125 processes: 105 sleeping, 2 running, 18 zombie, 0 stopped
CPU states: 5.1% user 1.1% system 0.0% nice 0.0% iowait 93.6% idle
Mem: 512716k av, 506176k used, 6540k free, 0k shrd, 21888k buff
Swap: 1044216k av, 161672k used, 882544k free 199388k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
2330 root 15 0 161M 70M 2132 S 4.9 14.0 1000m 0 X
2605 weeksa 15 0 8240 6340 3804 S 0.3 1.2 1:12 0 kdeinit
3413 weeksa 15 0 6668 5324 3216 R 0.3 1.0 0:20 0 kdeinit
18734 root 15 0 1192 1192 868 R 0.3 0.2 0:00 0 top
1619 root 15 0 776 608 504 S 0.1 0.1 0:53 0 dhclient
1 root 15 0 480 448 424 S 0.0 0.0 0:03 0 init
2 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 keventd
3 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kapmd
4 root 35 19 0 0 0 SWN 0.0 0.0 0:00 0 ksoftirqd_CPU0
9 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 bdflush
5 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kswapd
10 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kupdated
11 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 mdrecoveryd
15 root 15 0 0 0 0 SW 0.0 0.0 0:01 0 kjournald
81 root 25 0 0 0 0 SW 0.0 0.0 0:00 0 khubd
1188 root 15 0 0 0 0 SW 0.0 0.0 0:00 0 kjournald
1675 root 15 0 604 572 520 S 0.0 0.1 0:00 0 syslogd
1679 root 15 0 428 376 372 S 0.0 0.0 0:00 0 klogd
1707 rpc 15 0 516 440 436 S 0.0 0.0 0:00 0 portmap
1776 root 25 0 476 428 424 S 0.0 0.0 0:00 0 apmd
1813 root 25 0 752 528 524 S 0.0 0.1 0:00 0 sshd
1828 root 25 0 704 548 544 S 0.0 0.1 0:00 0 xinetd
1847 ntp 15 0 2396 2396 2160 S 0.0 0.4 0:00 0 ntpd
1930 root 24 0 76 4 0 S 0.0 0.0 0:00 0 rpc.rquotad |
报告的顶部列出了系统时间、启动时间、CPU 使用率、物理内存和交换内存使用率以及进程数等信息。下面是由 CPU 利用率排序的进程列表。
你可以在 top 运行时修改其输出。如果你按i,top 将不再显示空闲进程。再次按i来再次查看它们。按M将按内存使用情况排序,S将按进程运行的时间长短排序,P将再次按 CPU 使用率排序。
除了查看选项外,你还可以从 top 命令中修改进程。你可以使用u查看特定用户拥有的进程,k终止进程,以及r重新调整它们的优先级。
有关进程的更深入信息,你可以在/proc文件系统中查看。在/proc文件系统中,你将找到一系列具有数字名称的子目录。这些目录与当前运行的进程的进程 ID 相关联。在每个目录中,你将找到一系列包含有关进程信息的文件。
你必须格外小心,不要修改这些文件,这样做可能会导致系统问题!
7.1.2. iostat 命令。
iostat 将显示当前的 CPU 负载平均值和磁盘 I/O 信息。这是一个监控磁盘 I/O 使用情况的好命令。
# iostat
Linux 2.4.20-24.9 (myhost) 12/23/2003
avg-cpu: %user %nice %sys %idle
62.09 0.32 2.97 34.62
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
dev3-0 2.22 15.20 47.16 1546846 4799520 |
# iostat -x
Linux 2.4.20-24.9 (myhost) 12/23/2003
avg-cpu: %user %nice %sys %idle
62.01 0.32 2.97 34.71
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/hdc 0.00 0.00 .00 0.00 0.00 0.00 0.00 0.00 0.00 2.35 0.00 0.00 14.71
/dev/hda 1.13 4.50 .81 1.39 15.18 47.14 7.59 23.57 28.24 1.99 63.76 70.48 15.56
/dev/hda1 1.08 3.98 .73 1.27 14.49 42.05 7.25 21.02 28.22 0.44 21.82 4.97 1.00
/dev/hda2 0.00 0.51 .07 0.12 0.55 5.07 0.27 2.54 30.35 0.97 52.67 61.73 2.99
/dev/hda3 0.05 0.01 .02 0.00 0.14 0.02 0.07 0.01 8.51 0.00 12.55 2.95 0.01 |
iostat 的 man 页面包含对每列含义的详细解释。
7.1.3. ps 命令
ps 将为你提供当前正在运行的进程的列表。此命令提供了多种多样的选项。
一个常见的用法是列出当前正在运行的所有进程。为此,你将使用 ps -ef 命令。(此命令的屏幕输出太大,无法包含,以下仅为部分输出。)
UID PID PPID C STIME TTY TIME CMD root 1 0 0 Dec22 ? 00:00:03 init root 2 1 0 Dec22 ? 00:00:00 [keventd] root 3 1 0 Dec22 ? 00:00:00 [kapmd] root 4 1 0 Dec22 ? 00:00:00 [ksoftirqd_CPU0] root 9 1 0 Dec22 ? 00:00:00 [bdflush] root 5 1 0 Dec22 ? 00:00:00 [kswapd] root 6 1 0 Dec22 ? 00:00:00 [kscand/DMA] root 7 1 0 Dec22 ? 00:01:28 [kscand/Normal] root 8 1 0 Dec22 ? 00:00:00 [kscand/HighMem] root 10 1 0 Dec22 ? 00:00:00 [kupdated] root 11 1 0 Dec22 ? 00:00:00 [mdrecoveryd] root 15 1 0 Dec22 ? 00:00:01 [kjournald] root 81 1 0 Dec22 ? 00:00:00 [khubd] root 1188 1 0 Dec22 ? 00:00:00 [kjournald] root 1675 1 0 Dec22 ? 00:00:00 syslogd -m 0 root 1679 1 0 Dec22 ? 00:00:00 klogd -x rpc 1707 1 0 Dec22 ? 00:00:00 portmap root 1813 1 0 Dec22 ? 00:00:00 /usr/sbin/sshd ntp 1847 1 0 Dec22 ? 00:00:00 ntpd -U ntp root 1930 1 0 Dec22 ? 00:00:00 rpc.rquotad root 1934 1 0 Dec22 ? 00:00:00 [nfsd] root 1942 1 0 Dec22 ? 00:00:00 [lockd] root 1943 1 0 Dec22 ? 00:00:00 [rpciod] root 1949 1 0 Dec22 ? 00:00:00 rpc.mountd root 1961 1 0 Dec22 ? 00:00:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf root 2057 1 0 Dec22 ? 00:00:00 /usr/bin/spamd -d -c -a root 2066 1 0 Dec22 ? 00:00:00 gpm -t ps/2 -m /dev/psaux bin 2076 1 0 Dec22 ? 00:00:00 /usr/sbin/cannaserver -syslog -u bin root 2087 1 0 Dec22 ? 00:00:00 crond daemon 2195 1 0 Dec22 ? 00:00:00 /usr/sbin/atd root 2215 1 0 Dec22 ? 00:00:11 /usr/sbin/rcd weeksa 3414 3413 0 Dec22 pts/1 00:00:00 /bin/bash weeksa 4342 3413 0 Dec22 pts/2 00:00:00 /bin/bash weeksa 19121 18668 0 12:58 pts/2 00:00:00 ps -ef |
第一列显示谁拥有该进程。第二列是进程 ID。第三列是父进程 ID。这是生成或启动进程的进程。第四列是 CPU 使用率(百分比)。第五列是启动时间,如果进程已运行足够长的时间,则为日期。第六列是与进程关联的 tty(如果适用)。第七列是累积 CPU 使用率(运行期间使用的 CPU 时间总量)。第八列是命令本身。
有了这些信息,你可以准确地看到系统上正在运行的内容,并终止失控的进程或导致问题的进程。
7.1.4. vmstat 命令
vmstat 命令将提供一份报告,显示系统进程、内存、交换、I/O 和 CPU 的统计信息。这些统计信息是使用上次运行该命令到当前的数据生成的。如果从未运行该命令,则数据将从上次重启到当前。
# vmstat procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 0 0 0 181604 17000 26296 201120 0 2 8 24 149 9 61 3 36 |
以下摘自 vmstat man 页面。
字段描述
进程
r: 等待运行时间的进程数。
b: 处于不可中断睡眠状态的进程数。
w: 已交换出但仍可运行的进程数。这个
字段是计算出来的,但 Linux 从不绝望地交换。
内存
swpd: 使用的虚拟内存量 (kB)。
free: 空闲内存量 (kB)。
buff: 用作缓冲区的内存量 (kB)。
Swap
si: 从磁盘交换到内存的内存量 (kB/s)。
so: 交换到磁盘的内存量 (kB/s)。
IO
bi: 发送到块设备的块 (blocks/s)。
bo: 从块设备接收的块 (blocks/s)。
系统
in: 每秒中断数,包括时钟。
cs: 每秒上下文切换数。
CPU
这些是 CPU 总时间的百分比。
us: 用户时间
sy: 系统时间
id: 空闲时间
7.1.5. lsof 命令
lsof 命令将打印出正在使用的每个文件的列表。由于 Linux 将所有内容都视为文件,因此该列表可能很长。但是,此命令可用于诊断问题。一个例子是,如果你想卸载一个文件系统,但你被告知它正在使用中。你可以使用这个命令和 grep 来查找文件系统的名称,看看谁在使用它。
或者假设你想查看特定进程正在使用的所有文件。为此,你将使用 lsof -p -进程ID-。
7.1.6. 查找更多实用程序
要了解有关可用命令行工具的更多信息,Chris Karakas 编写了一份参考指南,名为 GNU/Linux 命令行工具摘要。它是学习有哪些工具以及如何完成许多任务的好资源。
7.2. 文件系统使用情况
许多报告目前都在谈论存储变得多么便宜,但如果你像我们大多数人一样,它还不够便宜。我们大多数人的空间有限,需要能够监控和控制它的使用方式。
7.2.1. df 命令
df 是可用于查看磁盘使用情况的最简单的工具。只需输入 df,你就会看到所有已挂载文件系统的磁盘使用情况,以 1K 块为单位
user@server:~> df Filesystem 1K-blocks Used Available Use% Mounted on /dev/hda3 5242904 759692 4483212 15% / tmpfs 127876 8 127868 1% /dev/shm /dev/hda1 127351 33047 87729 28% /boot /dev/hda9 10485816 33508 10452308 1% /home /dev/hda8 5242904 932468 4310436 18% /srv /dev/hda7 3145816 32964 3112852 2% /tmp /dev/hda5 5160416 474336 4423928 10% /usr /dev/hda6 3145816 412132 2733684 14% /var |
你也可以使用 -h 参数以“人类可读”的格式查看输出。这将根据文件系统的大小显示为 K、Megs 或 Gigs。或者,你也可以使用 -B 参数来指定块大小。
除了空间使用情况,你还可以使用 -i 选项来查看已用和可用 inode 的数量。
user@server:~> df -i Filesystem Inodes IUsed IFree IUse% Mounted on /dev/hda3 0 0 0 - / tmpfs 31969 5 31964 1% /dev/shm /dev/hda1 32912 47 32865 1% /boot /dev/hda9 0 0 0 - /home /dev/hda8 0 0 0 - /srv /dev/hda7 0 0 0 - /tmp /dev/hda5 656640 26651 629989 5% /usr /dev/hda6 0 0 0 - /var |
7.2.2. du 命令
现在你已经知道文件系统上使用了多少空间,如何找出数据在哪里呢?要查看目录或文件的使用情况,可以使用 du 命令。除非你指定文件名,否则 du 将递归执行。例如:
user@server:~> du file.txt 1300 file.txt |
user@server:~> du -h file.txt 1.3M file.txt |
除非你指定文件名,否则 du 将递归执行。
user@server:~> du -h /usr/local 4.0K /usr/local/games 16K /usr/local/include/nessus/net 180K /usr/local/include/nessus 208K /usr/local/include 62M /usr/local/lib/nessus/plugins/.desc 97M /usr/local/lib/nessus/plugins 164K /usr/local/lib/nessus/plugins_factory 97M /usr/local/lib/nessus 12K /usr/local/lib/pkgconfig 2.7M /usr/local/lib/ladspa 104M /usr/local/lib 112K /usr/local/man/man1 4.0K /usr/local/man/man2 4.0K /usr/local/man/man3 4.0K /usr/local/man/man4 16K /usr/local/man/man5 4.0K /usr/local/man/man |
如果你只想获得该目录的摘要,可以使用 -s 选项。
user@server:~> du -hs /usr/local 210M /usr/local |
7.3. 监视用户
仅仅因为你很偏执,并不意味着他们没有想对你不利... 来源未知
有时你会想确切地知道人们在你的系统上做什么。也许你注意到使用了大量的 RAM,或者大量的 CPU 活动。你将会想要查看谁在系统上,他们在运行什么,以及他们正在使用什么样的资源。
7.3.1. who 命令
查看谁在系统上最简单的方法是执行 who 或 w 命令。 who 是一个简单的工具,它列出了谁登录到系统以及他们登录的端口或终端。
user@server:~> who bjones pts/0 May 23 09:33 wally pts/3 May 20 11:35 aweeks pts/1 May 22 11:03 aweeks pts/2 May 23 15:04 |
7.3.2. ps 命令 - 再次!
在前一节中,我们可以看到用户 aweeks 同时登录到pts/1和pts/2,但是如果我们想知道他们在做什么呢?我们可以执行 ps -u aweeks 并获得以下输出:
user@server:~> ps -u aweeks 20876 pts/1 00:00:00 bash 20904 pts/2 00:00:00 bash 20951 pts/2 00:00:00 ssh 21012 pts/1 00:00:00 ps |
这是比之前讨论的 ps 命令更集中的用法。
7.3.3. w 命令
甚至比使用 who 和 ps -u 命令更简单的是使用 w 命令。 w 不仅会打印出谁在系统上,还会打印出他们正在运行的命令。
user@server:~> w aweeks :0 09:32 ?xdm? 30:09 0.02s -:0 aweeks pts/0 09:33 5:49m 0.00s 0.82s kdeinit: kded aweeks pts/2 09:35 8.00s 0.55s 0.36s vi sag-0.9.sgml aweeks pts/1 15:03 59.00s 0.03s 0.03s /bin/bash |
从这里我们可以看到我正在运行一个 kde 会话,我正在处理这个文档 :-),并且有另一个终端打开,在 bash 提示符下空闲。
第 8 章. 启动和关机
启动我
啊...你必须...你必须
永不,永不,永不停
启动它
啊...启动它,永不,永不,永不
你让一个成年男人哭泣,
你让一个成年男人哭泣
(滚石乐队)
本节介绍 Linux 系统启动和关闭时发生的事情,以及如何正确执行。如果不遵循正确的程序,文件可能会损坏或丢失。
8.1. 启动和关闭概述
打开计算机系统并导致其加载操作系统的行为称为 启动。 这个名字来自计算机从它的自举带中把自己拉起来的形象,但这个行为本身稍微现实一些。
在引导过程中,计算机首先加载一小段代码,称为 引导加载程序,它又加载并启动操作系统。引导加载程序通常存储在硬盘或软盘上的固定位置。这个两步过程的原因是操作系统很大且复杂,但计算机加载的第一段代码必须非常小(几百个字节),以避免使固件不必要地复杂化。
不同的计算机以不同的方式进行引导。对于 PC,计算机 (其 BIOS) 读取软盘或硬盘的第一个扇区(称为 引导扇区)。引导加载程序包含在这个扇区中。它从磁盘上的其他位置(或从其他地方)加载操作系统。
Linux 加载后,它会初始化硬件和设备驱动程序,然后运行 init。 init 启动其他进程以允许用户登录并执行操作。这部分的详细信息将在下面讨论。
为了关闭 Linux 系统,首先通知所有进程终止(这使它们关闭所有文件并执行其他必要的操作以保持整洁),然后卸载文件系统和交换区,最后向控制台打印一条消息,提示可以关闭电源。如果不遵循正确的程序,可能会发生可怕的事情;最重要的是,文件系统缓冲区缓存可能不会被刷新,这意味着其中的所有数据都将丢失,并且磁盘上的文件系统不一致,因此可能无法使用。
8.2. 更仔细地观察启动过程
当 PC 启动时,BIOS 将执行各种测试以检查一切是否正常,然后开始实际的引导。此过程称为 开机自检,或简称为 POST。 它将选择一个磁盘驱动器(通常是第一个软盘驱动器,如果插入了软盘;否则是第一个硬盘,如果安装在计算机中;但是顺序可能是可配置的),然后读取它的第一个扇区。 这称为 引导扇区;对于硬盘,它也称为 主引导记录,因为硬盘可以包含多个分区,每个分区都有自己的引导扇区。
引导扇区包含一个小型程序(足够小以容纳到一个扇区中),其职责是从磁盘读取实际的操作系统并启动它。 从软盘启动 Linux 时,引导扇区包含的代码只是将前几百个块(当然,具体取决于实际的内核大小)读取到内存中的预定位置。 在 Linux 引导软盘上,没有文件系统,内核只是存储在连续的扇区中,因为这简化了引导过程。 但是,可以通过使用 LILO(LInux LOader)或 GRUB(GRand Unifying Bootloader)从带有文件系统的软盘启动。
从硬盘启动时,主引导记录中的代码将检查分区表(也在主引导记录中),识别活动分区(标记为可启动的分区),从该分区读取引导扇区,然后启动该引导扇区中的代码。 分区的引导扇区中的代码执行软盘的引导扇区所做的事情:它将从分区中读取内核并启动它。 但是,细节有所不同,因为通常将单独的分区仅用于内核映像是没有用的,因此分区引导扇区中的代码不能只是按顺序读取磁盘,它必须找到文件系统将它们放置的扇区。 有几种方法可以解决此问题,但是最常见的方法是使用引导加载程序,例如 LILO 或 GRUB。 (有关如何执行此操作的详细信息与此讨论无关;有关更多信息,请参见 LILO 或 GRUB 文档;这是最透彻的。)
启动时,引导加载程序通常会直接读取并启动默认内核。 也可以配置引导加载程序以能够启动多个内核之一,甚至可以启动 Linux 以外的其他操作系统,并且用户可以在启动时选择要启动哪个内核或操作系统。 例如,可以配置 LILO,以便如果在启动时(加载 LILO 时)按住 alt,shift 或 ctrl 键,LILO 会询问要启动什么,而不是立即启动默认设置。 另外,可以配置引导加载程序,以便它总是询问,并具有一个可选的超时时间,该超时时间将导致启动默认内核。
也可以在内核或操作系统的名称之后提供 内核命令行参数。 有关可能的选项列表,你可以阅读 http://www.tldp.org/HOWTO/BootPrompt-HOWTO.html。
从软盘和从硬盘启动都有其优点,但是通常从硬盘启动更好,因为它避免了摆弄软盘的麻烦。 它也更快。 大多数 Linux 发行版会在安装过程中为你设置引导加载程序。
无论以何种方式将 Linux 内核读取到内存中,并真正启动后,大致会发生以下情况
Linux 内核以压缩形式安装,因此它将首先解压缩自身。 内核映像的开头包含一个执行此操作的小程序。
如果你有一个 Linux 识别的超级 VGA 卡,并且具有一些特殊的文本模式(例如 100 列乘 40 行),Linux 会询问你要使用哪种模式。 在内核编译期间,可以预设一种视频模式,以便永远不会问到这个问题。 也可以使用 LILO,GRUB 或 rdev 来完成。
此后,内核会检查还有哪些其他硬件(硬盘,软盘,网络适配器等),并相应地配置其某些设备驱动程序; 在执行此操作时,它会输出有关其发现的消息。 例如,当我启动时,它看起来像这样
不同的系统上的确切文本不同,具体取决于硬件,使用的 Linux 版本以及其配置方式。LILO boot: Loading linux. Console: colour EGA+ 80x25, 8 virtual consoles Serial driver version 3.94 with no serial options enabled tty00 at 0x03f8 (irq = 4) is a 16450 tty01 at 0x02f8 (irq = 3) is a 16450 lp_init: lp1 exists (0), using polling driver Memory: 7332k/8192k available (300k kernel code, 384k reserved, 176k data) Floppy drive(s): fd0 is 1.44M, fd1 is 1.2M Loopback device init Warning WD8013 board not found at i/o = 280. Math coprocessor using irq13 error reporting. Partition check: hda: hda1 hda2 hda3 VFS: Mounted root (ext filesystem). Linux version 0.99.pl9-1 (root@haven) 05/01/93 14:12:20
然后,内核会尝试挂载根文件系统。挂载点可以在编译时配置,也可以随时使用 rdev 命令或引导加载程序进行配置。文件系统类型会被自动检测。如果根文件系统挂载失败,例如因为您忘记在内核中包含相应的文件系统驱动程序,内核会panic并停止系统(无论如何也做不了太多事情)。
根文件系统通常以只读方式挂载(这可以以与挂载点相同的方式进行设置)。这使得在挂载时检查文件系统成为可能;检查以读写方式挂载的文件系统不是一个好主意。
之后,内核会在后台启动程序 init (位于/sbin/init) (它总是会成为进程号 1)。init 会执行各种启动任务。它具体执行哪些任务取决于它的配置;请参阅 第 2.3.1 节 以获取更多信息(尚未编写)。它至少会启动一些必要的后台守护进程。
init 接着会切换到多用户模式,并为虚拟控制台和串行线路启动 getty。getty 是允许人们通过虚拟控制台和串行终端登录的程序。init 也可能会启动一些其他程序,具体取决于它的配置。
在此之后,引导完成,系统正常启动并运行。
8.2.1. 关于引导加载程序
待添加
本节将概述 GRUB 和 LILO 之间的区别。
有关 LILO 的更多信息,您可以阅读 http://www.tldp.org/HOWTO/LILO.html
有关 GRUB 的更多信息,您可以访问 https://gnu.ac.cn/software/grub/grub.html
8.3. 关于关机的更多信息
在关闭 Linux 系统时,遵循正确的程序非常重要。如果您不这样做,您的文件系统很可能会被损坏,并且文件很可能会被打乱。这是因为 Linux 有一个磁盘缓存,它不会立即将内容写入磁盘,而是会定期写入。这大大提高了性能,但也意味着如果您随意关闭电源,缓存可能会保存大量数据,并且磁盘上的内容可能不是一个完全正常工作的文件系统(因为只有一些内容被写入磁盘)。
反对直接关闭电源的另一个原因是,在多任务系统中,可能有很多事情在后台进行,并且关闭电源可能会非常灾难性。通过使用正确的关机顺序,您可以确保所有后台进程都可以保存它们的数据。
正确关闭 Linux 系统的命令是 shutdown。它通常以两种方式之一使用。
如果您运行的系统只有您一个用户,使用 shutdown 的常用方法是退出所有正在运行的程序,在所有虚拟控制台上注销,以 root 用户身份登录其中一个(或者如果您已经是 root 用户,则保持登录状态,但您应该切换到 root 的主目录或根目录,以避免卸载时出现问题),然后给出命令 shutdown -h now(替换now加上一个加号和一个分钟数,如果您想要延迟,尽管在单用户系统上通常不需要)。
或者,如果您的系统有多个用户,请使用命令 shutdown -h +time message,其中time是以分钟为单位,直到系统停止的时间,以及message是对系统关闭原因的简短解释。
# shutdown -h +10 'We will install a new disk. System should > be back on-line in three hours.' # |
Broadcast message from root (ttyp0) Wed Aug 2 01:03:25 1995... We will install a new disk. System should be back on-line in three hours. The system is going DOWN for system halt in 10 minutes !! |
在任何延迟之后,真正的关闭开始时,所有文件系统(除了根文件系统)都会被卸载,用户进程(如果仍然有人登录)会被杀死,守护进程会被关闭,所有文件系统都会被卸载,并且通常一切都会安定下来。完成之后,init 会打印一条消息,提示您可以关闭机器电源。然后,并且只有在那时,您才应该将手指移向电源开关。
有时,尽管在任何好的系统上都很少发生,但不可能正确关闭。例如,如果内核panic并崩溃,并通常表现异常,则可能完全无法给出任何新命令,因此正确关闭有些困难,并且您可以做的几乎所有事情就是希望没有受到太严重的损坏并关闭电源。如果问题稍微轻微一些(例如,有人用斧头敲击了您的键盘),并且内核和 update 程序仍然正常运行,那么最好等待几分钟,让 update 有机会刷新缓冲区缓存,然后在之后关闭电源。
过去,有些人喜欢使用命令 sync 三次来关闭,等待磁盘 I/O 停止,然后关闭电源。如果没有正在运行的程序,这相当于使用 shutdown。但是,它不会卸载任何文件系统,这可能会导致 ext2fs “干净文件系统”标志出现问题。 *不建议*使用三重 sync 方法。
(如果您想知道:三次同步的原因是在 UNIX 的早期,当命令被单独键入时,这通常会为大多数磁盘 I/O 提供足够的时间来完成。)
8.4. 重启
重启意味着再次启动系统。这可以通过首先完全关闭系统,关闭电源,然后重新打开电源来实现。一个更简单的方法是要求 shutdown 重启系统,而不是仅仅停止它。这可以通过使用-r选项到 shutdown,例如,通过给出命令 shutdown -r now。
大多数 Linux 系统在键盘上按下 ctrl-alt-del 时运行 shutdown -r now。这将重启系统。但是,ctrl-alt-del 的操作是可配置的,并且在多用户机器上最好在重启之前允许一些延迟。物理上任何人都可以访问的系统甚至可以配置为在按下 ctrl-alt-del 时不执行任何操作。
8.6. 紧急启动软盘
并非总是可以从硬盘启动计算机。例如,如果您在配置 LILO 时出错,可能会使您的系统无法启动。对于这些情况,您需要一种始终有效的替代启动方式(只要硬件工作)。对于典型的 PC,这意味着从软盘驱动器启动。
大多数 Linux 发行版允许在安装过程中创建一个紧急启动软盘。这是一个好主意。但是,一些这样的启动盘只包含内核,并假设您将使用发行版的安装盘上的程序来修复您遇到的任何问题。有时这些程序不足以解决问题;例如,您可能必须从使用不在安装盘上的软件制作的备份中恢复一些文件。
因此,可能还需要创建一个自定义的根软盘。Graham Chapman 的 Bootdisk HOWTO 包含了有关如何执行此操作的说明。您可以在 http://www.tldp.org/HOWTO/Bootdisk-HOWTO/index.html 找到这个 HOWTO。当然,您必须记住保持您的紧急启动软盘和根软盘的更新。
您不能将您用于挂载根软盘的软盘驱动器用于其他任何用途。如果您只有一个软盘驱动器,这可能会很不方便。但是,如果您有足够的内存,您可以配置您的启动软盘将根磁盘加载到 ramdisk(启动软盘的内核需要为此进行特殊配置)。一旦根软盘被加载到 ramdisk 中,软盘驱动器就可以自由地挂载其他磁盘了。
第 9 章. init
"Uuno 是第一名" (一系列芬兰电影的口号。)
本章介绍了 init 进程,它是内核启动的第一个用户级进程。init 有许多重要的职责,例如启动 getty (以便用户可以登录)、实现运行级别以及处理孤儿进程。本章解释了如何配置 init 以及如何利用不同的运行级别。
9.1. init 首先运行
init 是 Linux 系统运行绝对必要的程序之一,但您仍然可以忽略它。一个好的 Linux 发行版会为 init 提供适用于大多数系统的配置,并且在这些系统上,您无需对 init 做任何事情。通常,只有在您连接串行终端、拨入(而不是拨出)调制解调器,或者想要更改默认运行级别时,才需要担心 init。
当内核启动自身(已加载到内存中、已开始运行,并且已初始化所有设备驱动程序和数据结构等)时,它会通过启动用户级程序 init 来完成其自身的引导过程。因此,init 始终是第一个进程(它的进程号始终为 1)。
内核会在一些历史上曾使用过的位置寻找 init,但它在 Linux 系统上的正确位置是/sbin/init。如果内核找不到 init,它会尝试运行/bin/sh,如果也失败了,系统启动就会失败。
当 init 启动时,它会完成启动过程,执行许多管理任务,例如检查文件系统,清理/tmp、启动各种服务,并为每个终端和虚拟控制台启动一个 getty,以便用户能够登录(参见第 10 章)。
在系统正常启动后,init 会在用户注销后为每个终端重新启动 getty(以便下一个用户可以登录)。init 还会收养孤儿进程:当一个进程启动一个子进程并在其子进程之前死亡时,该子进程会立即成为 init 的子进程。这对于各种技术原因很重要,但了解这一点是有好处的,因为它可以更容易地理解进程列表和进程树图。有几个 init 的变体可用。大多数 Linux 发行版使用 sysvinit(由 Miquel van Smoorenburg 编写),它基于 System V init 设计。BSD 版本的 Unix 有不同的 init。主要的区别是运行级别:System V 有运行级别,BSD 没有(至少传统上是这样)。这种差异并不是本质的。我们将只关注 sysvinit。
9.2. 配置 init 以启动 getty:/etc/inittab文件
当它启动时,init 读取/etc/inittab配置文件。当系统运行时,如果发送 HUP 信号(kill -HUP 1),它将重新读取它;此功能使得不必重新启动系统即可使 init 配置生效。
的/etc/inittab文件有点复杂。我们将从配置 getty 行的简单情况开始。
/etc/inittab由四个冒号分隔的字段组成
id:runlevels:action:process |
- id
这标识了文件中的行。对于 getty 行,它指定了它运行的终端(之后的字符/dev/tty在设备文件名中)。对于其他行,这无关紧要(除了长度限制),但应该是唯一的。
- runlevels
该行应考虑的运行级别。运行级别以单个数字给出,没有分隔符。(运行级别将在下一节中介绍。)
- action
该行应采取什么行动,例如,respawn在下一个字段中的命令退出时再次运行它,或者once仅运行一次。
- process
要运行的命令。
1:2345:respawn:/sbin/getty 9600 tty1 |
getty 的不同版本运行方式不同。请查阅您的手册页,并确保它是正确的手册页。
如果想向系统添加终端或拨号调制解调器线路,您可以向/etc/inittab添加更多行,每条终端或拨号线路对应一行。有关更多详细信息,请参阅手册页 init、inittab和 getty。
如果一个命令在启动时失败,并且 init 被配置为restart它,它将使用大量的系统资源:init 启动它,它失败,init 启动它,它失败,init 启动它,它失败,依此类推,永无止境。为了防止这种情况,init 将跟踪它重新启动命令的频率,如果频率过高,它将在重新启动之前延迟五分钟。
9.3. 运行级别
运行级别是 init 和整个系统的一种状态,它定义了哪些系统服务正在运行。运行级别由数字标识。一些系统管理员使用运行级别来定义哪些子系统正在工作,例如,X 是否正在运行,网络是否可操作,等等。其他人则始终运行所有子系统,或者单独启动和停止它们,而不更改运行级别,因为运行级别对于控制他们的系统来说太粗糙了。您需要自己决定,但遵循您的 Linux 发行版的方式可能是最容易的。
下表定义了大多数 Linux 发行版如何定义不同的运行级别。但是,运行级别 2 到 5 可以修改以适合您自己的口味。
表 9-1. 运行级别编号
| 0 | 停止系统。 |
| 1 | 单用户模式(用于特殊管理)。 |
| 2 | 具有网络但不具有网络服务(如 NFS)的本地多用户模式 |
| 3 | 具有网络的完整多用户模式 |
| 4 | 未使用 |
| 5 | 具有网络和 X Windows(GUI)的完整多用户模式 |
| 6 | 重新启动。 |
在特定运行时启动的服务由各种rcN.d目录的内容确定。大多数发行版将这些目录位于/etc/init.d/rcN.d或/etc/rcN.d。(将 N 替换为运行级别编号)。
在每个运行级别中,您会发现一系列 if 链接,指向位于/etc/init.d中的启动脚本。这些链接的名称都以 K 或 S 开头,后跟一个数字。如果链接的名称以 S 开头,则表示当您进入该运行级别时,将启动该服务。如果链接的名称以 K 开头,则将终止该服务(如果正在运行)。
K 或 S 后的数字表示脚本的运行顺序。以下是/etc/init.d/rc3.d的一个示例。
# ls -l /etc/init.d/rc3.d lrwxrwxrwx 1 root root 10 2004-11-29 22:09 K12nfsboot -> ../nfsboot lrwxrwxrwx 1 root root 6 2005-03-29 13:42 K15xdm -> ../xdm lrwxrwxrwx 1 root root 9 2004-11-29 22:08 S01pcmcia -> ../pcmcia lrwxrwxrwx 1 root root 9 2004-11-29 22:06 S01random -> ../random lrwxrwxrwx 1 root root 11 2005-03-01 11:56 S02firewall -> ../firewall lrwxrwxrwx 1 root root 10 2004-11-29 22:34 S05network -> ../network lrwxrwxrwx 1 root root 9 2004-11-29 22:07 S06syslog -> ../syslog lrwxrwxrwx 1 root root 10 2004-11-29 22:09 S08portmap -> ../portmap lrwxrwxrwx 1 root root 9 2004-11-29 22:07 S08resmgr -> ../resmgr lrwxrwxrwx 1 root root 6 2004-11-29 22:09 S10nfs -> ../nfs lrwxrwxrwx 1 root root 12 2004-11-29 22:40 S12alsasound -> ../alsasound lrwxrwxrwx 1 root root 8 2004-11-29 22:09 S12fbset -> ../fbset lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S12sshd -> ../sshd lrwxrwxrwx 1 root root 8 2005-02-01 09:24 S12xntpd -> ../xntpd lrwxrwxrwx 1 root root 7 2004-12-02 20:34 S13cups -> ../cups lrwxrwxrwx 1 root root 6 2004-11-29 22:09 S13kbd -> ../kbd lrwxrwxrwx 1 root root 13 2004-11-29 22:10 S13powersaved -> ../powersaved lrwxrwxrwx 1 root root 9 2004-11-29 22:09 S14hwscan -> ../hwscan lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S14nscd -> ../nscd lrwxrwxrwx 1 root root 10 2004-11-29 22:10 S14postfix -> ../postfix lrwxrwxrwx 1 root root 6 2005-02-04 13:27 S14smb -> ../smb lrwxrwxrwx 1 root root 7 2004-11-29 22:10 S15cron -> ../cron lrwxrwxrwx 1 root root 8 2004-12-22 20:35 S15smbfs -> ../smbfs |
运行级别的启动方式在/etc/inittab中配置,如下面的行所示
l2:2:wait:/etc/init.d/rc 2 |
第四个字段中的命令完成了设置运行级别的所有繁重工作。它启动尚未运行的服务,并停止不应再在新运行级别中运行的服务。命令的确切内容以及如何配置运行级别取决于 Linux 发行版。
当 init 启动时,它会在/etc/inittab中查找指定默认运行级别的行
id:2:initdefault: |
single或或emergency
当系统运行时,telinit 命令可以更改运行级别。当运行级别更改时,init 从/etc/inittab.
9.4. 中的特殊配置/etc/inittab
的/etc/inittab有一些特殊功能,允许 init 对特殊情况做出反应。这些特殊功能在第三个字段中用特殊关键字标记。一些例子
- powerwait
允许 init 在电源发生故障时关闭系统。这假设使用了 UPS,以及监视 UPS 并通知 init 电源已关闭的软件。
- ctrlaltdel
允许 init 在用户在控制台键盘上按下 ctrl-alt-del 时重新启动系统。请注意,系统管理员可以将 ctrl-alt-del 的反应配置为其他内容,例如,如果系统位于公共位置,则将其忽略。(或者启动 nethack。)
- sysinit
系统启动时要运行的命令。此命令通常会清理/tmp,例如。
9.5. 在单用户模式下启动
一个重要的运行级别是单用户模式(运行级别 1),在这种模式下,只有系统管理员正在使用机器,并且运行的系统服务尽可能少,包括登录。单用户模式对于一些管理任务是必要的,例如在/usr分区上运行 fsck,因为这需要卸载分区,除非几乎所有系统服务都被终止,否则这是不可能发生的。
可以通过使用 telinit 请求运行级别 1 将运行的系统置于单用户模式。在启动时,可以通过在内核命令行中给出单词single或或来进入:内核也将命令行提供给 init,并且 init 从该单词中了解到它不应使用默认运行级别。(内核命令行的输入方式取决于您启动系统的方式。)
有时需要启动到单用户模式,以便可以在任何东西挂载或以其他方式接触损坏的/usr分区之前,手动运行 fsck(在损坏的文件系统上的任何活动都可能使其更加损坏,因此应尽快运行 fsck)。
如果启动时自动 fsck 失败,init 运行的启动脚本将自动进入单用户模式。这是为了防止系统使用 fsck 无法自动修复的损坏的文件系统。这种损坏相对罕见,通常涉及损坏的硬盘驱动器或实验性内核版本,但最好做好准备。
作为安全措施,正确配置的系统在单用户模式下启动 shell 之前会要求输入 root 密码。否则,只需在 LILO 中输入合适的行即可作为 root 用户进入。(如果/etc/passwd已被文件系统问题破坏,这将不起作用,在这种情况下,您最好手头有一个启动软盘。)
第 10 章。登录和注销
"我不喜欢加入一个接受像我这样的人作为会员的俱乐部。"(格劳乔·马克斯)
本节描述了用户登录或注销时发生的事情。背景进程、日志文件、配置文件等的各种交互将在一些细节中描述。
10.1. 通过终端登录
第 2.3.2 节 展示了如何通过终端进行登录。首先,init 确保终端连接(或控制台)有一个 getty 程序。getty 监听终端并等待用户通知其已准备好登录(这通常意味着用户必须输入一些内容)。当它注意到用户时,getty 会输出一条欢迎消息(存储在/etc/issue),并提示输入用户名,最后运行 login 程序。login 将用户名作为参数获取,并提示用户输入密码。如果匹配,login 启动为用户配置的 shell;否则,它只是退出并终止该进程(可能在给用户另一次输入用户名和密码的机会之后)。init 注意到进程已终止,并为终端启动一个新的 getty。
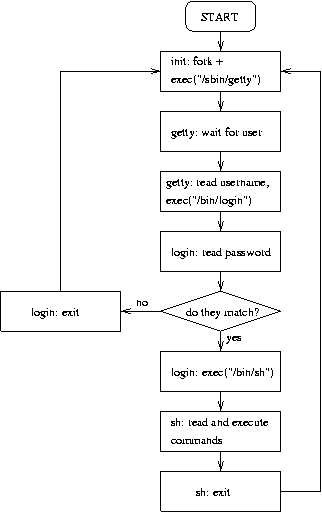
请注意,唯一的新进程是由 init 创建的(使用fork系统调用);getty 和 login 仅替换进程中运行的程序(使用exec系统调用)。
对于串行线路,需要一个单独的程序来通知用户,因为它可能(并且传统上是)很难注意到终端何时变为活动状态。getty 还适应连接的速度和其他设置,这对于拨号连接尤其重要,因为这些参数可能因呼叫而异。
目前有几个版本的 getty 和 init 在使用,它们都有各自的优点和缺点。 最好了解系统上的版本,以及其他版本(您可以使用 Linux 软件地图搜索它们)。 如果您没有拨号连接,您可能不必担心 getty,但 init 仍然很重要。
10.2. 通过网络登录
同一网络中的两台计算机通常通过单根物理电缆连接。 当它们通过网络进行通信时,每台计算机中参与通信的程序通过一个 虚拟连接 连接,这是一种假想的电缆。 就虚拟连接两端的程序而言,它们对自己的电缆具有垄断权。 但是,由于电缆不是真实的,只是想象的,因此两台计算机的操作系统都可以让多个虚拟连接共享同一根物理电缆。 这样,仅使用单根电缆,多个程序就可以进行通信,而不必了解或关心其他通信。 甚至可以让多台计算机使用同一根电缆; 虚拟连接存在于两台计算机之间,其他计算机忽略那些它们不参与的连接。
这是一个复杂且过度抽象的现实描述。 但是,这可能足以理解为什么网络登录与正常登录有些不同的重要原因。 当不同计算机上有两个程序希望通信时,就会建立虚拟连接。 由于原则上可以从网络中的任何计算机登录到任何其他计算机,因此存在大量潜在的虚拟通信。 因此,为每个潜在的登录启动一个 getty 是不切实际的。
有一个单一的进程 inetd (对应于 getty) 处理所有网络登录。 当它注意到传入的网络登录(即,它注意到它获得了到其他计算机的新虚拟连接)时,它会启动一个新进程来处理该单一登录。 原始进程保留并继续监听新的登录。
为了使事情更复杂一些,网络登录有多种通信协议。 其中两个最重要的协议是 telnet 和 rlogin。 除了登录之外,还可以建立许多其他虚拟连接(用于 FTP、Gopher、HTTP 和其他网络服务)。 为特定类型的连接单独监听进程是无效的,因此只有一个监听器可以识别连接的类型,并且可以启动正确类型的程序来提供服务。 这个单一的监听器称为 inetd; 有关更多信息,请参阅 Linux 网络管理员指南。
10.3. login 做什么
login 程序负责验证用户身份(确保用户名和密码匹配),并通过设置串行线路的权限和启动 shell 来为用户设置初始环境。
初始设置的一部分是输出文件的内容/etc/motd(message of the day 的缩写)并检查电子邮件。可以通过创建名为.hushlogin在用户的主目录中来禁用这些。
如果文件/etc/nologin存在,则禁用登录。 该文件通常由 shutdown 及其相关程序创建。 login 检查此文件,如果存在,将拒绝接受登录。 如果它确实存在,login 会在其退出之前将其内容输出到终端。
login 将所有失败的登录尝试记录到系统日志文件中(通过 syslog)。 它还记录所有 root 登录。 这两者在追踪入侵者时都很有用。
当前登录的人员在/var/run/utmp中列出。 此文件仅在系统下次重新启动或关闭之前有效; 系统启动时会清除它。 它列出了每个用户及其使用的终端(或网络连接),以及其他一些有用的信息。 who、w 和其他类似命令在utmp中查找谁已登录。
所有成功的登录都记录到/var/log/wtmp中。 此文件将无限增长,因此必须定期清理,例如每周使用 cron 作业来清除它。last 命令浏览wtmp.
两者utmp和wtmp都采用二进制格式(请参阅utmp手册页); 在没有特殊程序的情况下检查它们很不方便。
10.5. 访问控制
用户数据库传统上包含在/etc/passwd文件中。 一些系统使用 影子密码,并将密码移动到 /etc/shadow。 共享帐户的多个计算机的站点使用 NIS 或其他方法来存储用户数据库; 他们还可以自动将数据库从一个中心位置复制到所有其他计算机。
用户数据库不仅包含密码,还包含有关用户的其他一些信息,例如他们的真实姓名、主目录和登录 shell。 这些其他信息需要公开,以便任何人都可以读取它。 因此,密码被加密存储。 这确实有一个缺点,即任何有权访问加密密码的人都可以使用各种加密方法来猜测它,而无需尝试实际登录到计算机。 影子密码试图通过将密码移动到另一个只有 root 才能读取的文件来避免这种情况(密码仍然加密存储)。 但是,稍后将影子密码安装到不支持它们的系统上可能会很困难。
无论有没有密码,重要的是确保系统中所有密码都是好的,即不易猜到。 crack 程序可用于破解密码; 它能找到的任何密码,根据定义都不是一个好密码。 虽然 crack 可以由入侵者运行,但它也可以由系统管理员运行以避免使用坏密码。passwd 程序也可以强制使用好密码; 事实上,这在 CPU 周期中更有效,因为破解密码需要大量的计算。
用户组数据库保存在/etc/group中; 对于具有影子密码的系统,可以有一个/etc/shadow.group.
root 通常无法通过大多数终端或网络登录,只能通过在/etc/securetty文件中列出的终端登录。 这使得必须获得对这些终端之一的物理访问。 但是,可以以任何其他用户的身份通过任何终端登录,并使用 su 命令成为 root。
第 11 章。 管理用户帐户
“系统管理员和毒品经销商的相似之处:两者都以 K 为单位衡量东西,并且两者都有用户。” (古老而乏味的计算机笑话。)
本章解释了如何创建新用户帐户、如何修改这些帐户的属性以及如何删除帐户。 不同的 Linux 系统有不同的工具来执行此操作。
11.1. 什么是帐户?
当一台计算机被许多人使用时,通常需要区分用户,例如,以便他们的私人文件可以保密。 即使计算机一次只能由一个人使用(就像大多数微型计算机一样),这一点也很重要。 因此,每个用户都会被赋予一个唯一的用户名,并且该名称用于登录。
但是,用户不仅仅是一个名称。帐户是一个用户的所有文件、资源和信息。 该术语暗示了银行,并且在商业系统中,每个帐户通常都附带一些资金,并且这些资金会以不同的速度消失,具体取决于用户对系统的压力有多大。 例如,磁盘空间可能具有每兆字节和每天的价格,并且处理时间可能具有每秒的价格。
11.2. 创建用户
Linux 内核本身将用户视为单纯的数字。 每个用户都由一个唯一的整数标识,即 用户 ID 或 uid,因为数字对于计算机来说比文本名称更快更容易处理。 内核外部的单独数据库将一个文本名称,即 用户名,分配给每个用户 ID。 该数据库还包含其他信息。
要创建用户,您需要将有关用户的信息添加到用户数据库,并为他创建一个主目录。 可能还需要教育用户,并为他设置合适的初始环境。
大多数 Linux 发行版都带有一个用于创建帐户的程序。 有几个这样的程序可用。 两个命令行替代方案是 adduser 和 useradd; 也可能有一个 GUI 工具。 无论程序如何,结果是几乎不需要任何手动工作。 即使细节很多很复杂,这些程序也会使一切看起来微不足道。 但是,第 11.2.4 节 描述了如何手动执行此操作。
11.2.1. /etc/passwd和其他信息文件
Unix 系统中的基本用户数据库是文本文件,/etc/passwd(称为 密码文件),其中列出了所有有效的用户名及其关联的信息。 该文件每个用户名占一行,并分为七个冒号分隔的字段
用户名。
以前,这是存储用户密码的地方。
数字用户ID。
数字组ID。
帐户的全名或其他描述。
主目录。
登录 shell(登录时运行的程序)。
大多数 Linux 系统使用 shadow passwords(影子密码)。如前所述,以前密码存储在/etc/passwd文件中。这种更新的密码存储方法:加密的密码存储在单独的文件/etc/shadow中,只有 root 用户才能读取。而/etc/passwd文件仅在第二个字段中包含一个特殊的标记。 任何需要验证用户的程序都是 setuid 的,因此可以访问影子密码文件。 仅使用密码文件中其他字段的普通程序无法访问密码。
11.2.2. 选择数字用户和组 ID
在大多数系统上,数字用户和组 ID 是什么并不重要,但是如果您使用网络文件系统 (NFS),则需要在所有系统上具有相同的 uid 和 gid。 这是因为 NFS 也使用数字 uid 标识用户。 如果您未使用 NFS,则可以让您的帐户创建工具自动选择它们。
如果您使用的是 NFS,则必须发明一种用于同步帐户信息的机制。 一种替代方法是使用 NIS 系统(请参阅 XXX network-admin-guide)。
但是,您应该尽量避免重复使用数字 uid(和文本用户名),因为 uid(或用户名)的新所有者可能会访问旧所有者的文件(或邮件等)。
11.2.3. 初始环境/etc/skel
创建新用户的主目录时,将使用来自/etc/skel目录的文件进行初始化。系统管理员可以在/etc/skel中创建文件,这些文件将为用户提供良好的默认环境。 例如,他可能会创建一个/etc/skel/.profile,该文件将 EDITOR 环境变量设置为对新用户友好的编辑器。
但是,通常最好尽量保持/etc/skel尽可能小,因为更新现有用户的文件几乎是不可能的。 例如,如果友好编辑器的名称更改,则所有现有用户都必须编辑其.profile。 系统管理员可以尝试使用脚本自动执行此操作,但这几乎肯定会破坏某些人的文件。
尽可能将全局配置放入全局文件中,例如/etc/profile。 这样,就可以在不破坏用户自身设置的情况下进行更新。
11.2.4. 手动创建用户
要手动创建新帐户,请按照以下步骤操作
使用 vipw 编辑/etc/passwd,并为新帐户添加新行。 注意语法。不要直接使用编辑器编辑! vipw 锁定文件,因此其他命令不会尝试同时更新它。 您应将密码字段设置为 `*',以使其无法登录。
同样,如果还需要创建新组,请使用 vigr 编辑/etc/group。
使用 mkdir 创建用户的主目录。
将文件从/etc/skel复制到新的主目录。
使用 chown 和 chmod 修复所有权和权限。-R选项最有用。 正确的权限因站点而异,但通常以下命令可以正确执行操作
cd /home/newusername chown -R username.group . chmod -R go=u,go-w . chmod go= .
使用 passwd 设置密码。
在最后一步中设置密码后,该帐户将可以使用。 在完成所有其他操作之前,您不应设置密码,否则用户可能会在您仍在复制文件时无意中登录。
有时需要创建不供人使用的虚拟帐户。 例如,要设置匿名 FTP 服务器(以便任何人都可以从中下载文件,而无需先获得帐户),您需要创建一个名为 ftp 的帐户。 在这种情况下,通常不需要设置密码(上面的最后一步)。 实际上,最好不要这样做,这样除非他们首先成为 root 用户,否则没人可以使用该帐户,因为 root 用户可以成为任何用户。
11.3. 更改用户属性
有一些命令可以更改帐户的各种属性(即/etc/passwd):
- 中的相关字段)。
chfn
- 更改全名字段。
chsh
- passwd
更改登录 shell。
超级用户可以使用这些命令来更改任何帐户的属性。 普通用户只能更改其自身帐户的属性。 有时可能需要为普通用户禁用这些命令(使用 chmod),例如在有许多新手用户的环境中。/etc/passwd其他任务需要手动完成。 例如,要更改用户名,您需要直接编辑/etc/group(记住使用 vipw)。 同样,要将用户添加到更多组或从中删除用户,您需要编辑
(使用 vigr)。 但是,此类任务往往很少见,应谨慎执行:例如,如果您更改用户名,则电子邮件将不再发送到该用户,除非您还创建邮件别名。
11.4. 删除用户/etc/passwd和/etc/group要删除用户,首先要删除他的所有文件、邮箱、邮件别名、打印作业、cron 和 at 作业,以及所有其他对该用户的引用。 然后,从
中删除相关的行(记住从已添加的所有组中删除用户名)。 在开始删除内容之前,最好先禁用帐户(请参见下文),以防止用户在删除帐户时使用该帐户。
find / -user username |
但是,请注意,如果您的磁盘很大,则上述命令将花费很长时间。 如果您挂载了网络磁盘,则需要小心,以免破坏网络或服务器。
某些 Linux 发行版带有专门的命令来执行此操作;查找 deluser 或 userdel。 但是,手动执行也很容易,并且这些命令可能无法完成所有操作。
有时有必要临时禁用帐户,而不将其删除。 例如,用户可能尚未支付其费用,或者系统管理员可能怀疑破解者已获得该帐户的密码。
禁用帐户的最佳方法是将其 shell 更改为仅打印消息的特殊程序。 这样,任何尝试登录该帐户的人都将失败,并且会知道原因。 该消息可以告诉用户与系统管理员联系,以便解决任何问题。
也可以将用户名或密码更改为其他名称,但是这样一来,用户将不知道发生了什么。 困惑的用户意味着更多的工作。
#!/usr/bin/tail +2 This account has been closed due to a security breach. Please call 555-1234 and wait for the men in black to arrive. |
') 告诉内核,该行的其余部分是一个需要运行以解释该文件的命令。 在这种情况下,tail 命令会将除第一行以外的所有内容输出到标准输出。
# chsh -s /usr/local/lib/no-login/security billg # su - tester This account has been closed due to a security breach. Please call 555-1234 and wait for the men in black to arrive. # |
当然,su 的目的是测试更改是否有效。
Tail 脚本应保存在单独的目录中,以使其名称不干扰普通用户命令。
自然 是 确定性地 可靠的。
本章介绍了为什么要进行备份、如何进行备份以及何时进行备份,以及如何从备份中还原内容。
您的数据是有价值的。 重新创建它将花费您时间和精力,这将花费金钱,或者至少会带来个人的悲伤和泪水; 有时甚至无法重新创建它,例如,如果它是某些实验的结果。 由于这是一项投资,因此您应保护它并采取措施以避免丢失它。
您可能会丢失数据的原因主要有四个:硬件故障、软件错误、人为操作或自然灾害。 尽管现代硬件往往非常可靠,但它仍然可能看似自发地发生故障。 用于存储数据的最关键硬件是硬盘,它依赖于微小的磁场在充满电磁噪声的世界中保持完好无损。 现代软件甚至往往不可靠; 坚如磐石的程序是一个例外,而不是规则。 人非常不可靠,他们要么犯错,要么恶意地故意破坏数据。 自然可能不是邪恶的,但即使在善良时也会造成严重破坏。 总而言之,一切正常运作本身就是一个小小的奇迹。
备份是保护数据投资的一种方式。 通过拥有数据的多个副本,如果其中一个副本被销毁,则无关紧要(成本只是从备份中还原丢失的数据的成本)。
正确进行备份非常重要。 像与物理世界相关的所有其他事物一样,备份迟早会失败。 做好备份的一部分是确保它们有效; 您不希望注意到您的备份无效。 雪上加霜的是,您可能在进行备份时发生严重的崩溃; 如果您只有一个备份介质,则它也可能被销毁,使您留下辛勤工作的灰烬。 或者,您可能会在尝试还原时注意到您忘记备份一些重要的内容,例如拥有 15000 个用户的站点的用户数据库。 最好的情况是,您的所有备份可能都运行良好,但是读取您使用的磁带的最后一台已知的磁带驱动器现在有一个装满水的桶。
说到备份,偏执是工作描述的一部分。
成本非常重要,因为你最好拥有几倍于数据所需容量的备份存储。 廉价的介质通常是必须的。
可靠性极其重要,因为备份损坏会让成年人哭泣。备份介质必须能够多年保存数据而不发生损坏。你使用介质的方式会影响它作为备份介质的可靠性。 硬盘通常非常可靠,但如果它与你要备份的磁盘位于同一台计算机中,则作为备份介质它的可靠性不高。
如果可以在没有人工干预的情况下完成备份,那么速度通常不是很重要。 只要不需要监管,备份花费两个小时也没关系。 另一方面,如果备份无法在计算机原本空闲时进行,那么速度就是一个问题。
可用性显然是必要的,因为如果备份介质不存在,你就无法使用它。 同样重要的是,介质即使在未来,以及在非你自己的计算机上也能可用。 否则,在发生灾难后你可能无法恢复备份。
可用性是影响备份频率的重要因素。 备份越容易,效果越好。 备份介质一定不能难用或枯燥。
典型的替代方案是软盘和磁带。 软盘非常便宜、相当可靠、速度不太快、非常可用,但不适合存储大量数据。 磁带价格从便宜到有点贵,相当可靠,速度相当快,非常可用,并且根据磁带的大小,使用起来相当方便。
还有其他替代方案。 它们通常在可用性方面表现不佳,但如果这不是问题,它们可以在其他方面做得更好。 例如,磁光盘兼具软盘(它们是随机访问的,可以快速恢复单个文件)和磁带(包含大量数据)的优点。
12.3. 选择备份工具
有很多工具可以用来进行备份。 用于备份的传统 UNIX 工具是 tar、cpio 和 dump。 此外,还有大量的第三方软件包(包括免费软件和商业软件)可以使用。 备份介质的选择会影响工具的选择。
tar 和 cpio 类似,并且从备份的角度来看基本上是等效的。 两者都能够将文件存储在磁带上,并从磁带上检索文件。 两者都能够使用几乎任何介质,因为内核设备驱动程序负责底层设备处理,并且这些设备对于用户级程序来说看起来都差不多。 某些 UNIX 版本的 tar 和 cpio 在处理不寻常的文件(符号链接、设备文件、路径名非常长的文件等)时可能会出现问题,但 Linux 版本应该能够正确处理所有文件。
dump 的不同之处在于它直接读取文件系统,而不是通过文件系统读取。 它也是专门为备份而编写的; tar 和 cpio 实际上是用于归档文件,尽管它们也可以用于备份。
直接读取文件系统有一些优点。 它可以备份文件而不影响其时间戳; 对于 tar 和 cpio,你必须首先以只读方式挂载文件系统。 如果需要备份所有内容,直接读取文件系统也更有效,因为它可以减少磁盘磁头的移动。 主要缺点是它使备份程序特定于一种文件系统类型; Linux dump 程序只理解 ext2 文件系统。
dump 还直接支持备份级别(我们将在下面讨论); 对于 tar 和 cpio,这必须使用其他工具来实现。
对第三方备份工具的比较超出了本书的范围。 Linux 软件地图列出了许多免费软件。
12.4. 简单备份
一个简单的备份方案是先备份所有内容一次,然后备份自上次备份以来修改过的所有内容。 第一次备份称为完整备份,随后的备份称为增量备份。 完整备份通常比增量备份更费力,因为需要写入磁带的数据更多,并且完整备份可能无法放入一张磁带(或软盘)中。 从增量备份恢复可能比从完整备份恢复要花费更多的时间。 可以优化恢复过程,以便始终备份自上次完整备份以来的所有内容; 这样,备份会稍微多做一些工作,但永远不需要恢复超过一个完整备份和一个增量备份的内容。
如果你想每天进行备份并且有六张磁带,你可以使用磁带 1 进行第一次完整备份(例如,在星期五),并使用磁带 2 到 5 进行增量备份(星期一到星期四)。 然后,在磁带 6 上进行新的完整备份(第二个星期五),然后再次使用磁带 2 到 5 进行增量备份。 在进行新的完整备份之前,你不想覆盖磁带 1,以免在进行完整备份时发生意外。 在你将完整备份制作到磁带 6 之后,你希望将磁带 1 放在其他地方,这样当你的其他备份磁带在火灾中被毁时,你至少还剩下一些东西。 当你需要进行下一次完整备份时,取出磁带 1,并将磁带 6 放在它的位置。
如果你有超过六张磁带,你可以使用额外的磁带进行完整备份。 每次进行完整备份时,你都使用最旧的磁带。 这样,你可以拥有来自前几个星期的完整备份,如果你想查找一个旧的、现在已删除的文件或一个文件的旧版本,这会很有用。
12.4.1. 使用 tar 进行备份
可以使用 tar 轻松进行完整备份
# tar --create --file /dev/ftape /usr/src tar: Removing leading / from absolute path names in the archive # |
如果你的备份无法放入一张磁带中,你需要使用--multi-volume (-M) 选项
# tar -cMf /dev/fd0H1440 /usr/src tar: Removing leading / from absolute path names in the archive Prepare volume #2 for /dev/fd0H1440 and hit return: # |
在你进行备份之后,你应该使用--compare (-d) 选项
# tar --compare --verbose -f /dev/ftape usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ .... # |
可以使用 tar 以及--newer (-N) 选项
# tar --create --newer '8 Sep 1995' --file /dev/ftape /usr/src --verbose tar: Removing leading / from absolute path names in the archive usr/src/ usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/modules/ usr/src/linux-1.2.10-includes/include/asm-generic/ usr/src/linux-1.2.10-includes/include/asm-i386/ usr/src/linux-1.2.10-includes/include/asm-mips/ usr/src/linux-1.2.10-includes/include/asm-alpha/ usr/src/linux-1.2.10-includes/include/asm-m68k/ usr/src/linux-1.2.10-includes/include/asm-sparc/ usr/src/patch-1.2.11.gz # |
12.4.2. 使用 tar 恢复文件
的--extract (-x) 选项来提取文件
# tar --extract --same-permissions --verbose --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
# tar xpvf /dev/fd0H1440 usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/hdreg.h # |
# tar --list --file /dev/fd0H1440 usr/src/ usr/src/linux usr/src/linux-1.2.10-includes/ usr/src/linux-1.2.10-includes/include/ usr/src/linux-1.2.10-includes/include/linux/ usr/src/linux-1.2.10-includes/include/linux/hdreg.h usr/src/linux-1.2.10-includes/include/linux/kernel.h ... # |
tar 无法正确处理已删除的文件。 如果你需要从完整备份和增量备份恢复文件系统,并且你在两次备份之间删除了一个文件,那么在执行恢复后它将再次存在。 如果该文件包含不应再提供的敏感数据,这可能是一个大问题。
12.5. 多级备份
上一节中概述的简单备份方法通常足以满足个人使用或小型站点的需求。 对于更繁重的使用,多级备份更合适。
简单方法有两个备份级别:完整备份和增量备份。 这可以推广到任意数量的级别。 完整备份为 0 级,不同的增量备份级别为 1、2、3 等级。 在每个增量备份级别,你备份自同一级别或更高级别的上次备份以来更改的所有内容。
这样做的目的是允许更长的备份历史记录,而且成本较低。 在上一节的示例中,备份历史记录可以追溯到上一次完整备份。 可以通过使用更多磁带来扩展这一点,但每张新磁带只能保存一周的数据,这可能太贵了。 更长的备份历史记录很有用,因为通常很长时间后才会注意到删除或损坏的文件。 即使文件的版本不是最新的,也比没有文件好。
通过多层备份,可以更经济地延长备份历史。例如,如果我们购买了十盘磁带,我们可以使用磁带 1 和 2 进行每月备份(每个月的第一个星期五),使用磁带 3 到 6 进行每周备份(其他星期五;请注意,一个月可能有五个星期五,所以我们需要另外四盘磁带),使用磁带 7 到 10 进行每日备份(星期一到星期四)。仅使用四盘磁带,我们就可以将备份历史从两周(在所有每日磁带都被使用完之后)延长到两个月。当然,我们无法恢复这两个月期间每个文件的所有版本,但我们能够恢复的内容通常已经足够好了。
图 12-1 显示了每天使用的备份级别,以及在该月末可以从哪些备份中进行恢复。
备份级别也可以用于尽量缩短文件系统恢复时间。如果您有许多增量备份,其级别编号单调递增,那么如果您需要重建整个文件系统,则需要恢复所有这些备份。相反,您可以使用非单调的级别编号,并减少需要恢复的备份数量。
为了尽量减少恢复所需的磁带数量,您可以为每个增量磁带使用较小的级别。但是,这样会增加进行备份的时间(每次备份都会复制自上次完整备份以来的所有内容)。dump 手册页中建议了一种更好的方案,并在表 XX(efficient-backup-levels)中进行了描述。使用以下备份级别顺序:3, 2, 5, 4, 7, 6, 9, 8, 9, 等等。这可以保持备份和恢复时间都很短。您最多需要备份两天的工作量。恢复所需的磁带数量取决于您完整备份之间的间隔时间,但它比简单方案中的要少。
表 12-1. 使用多个备份级别的有效备份方案
| 磁带 | 级别 | 备份(天) | 恢复磁带 |
|---|---|---|---|
| 1 | 0 | n/a | 1 |
| 2 | 3 | 1 | 1, 2 |
| 3 | 2 | 2 | 1, 3 |
| 4 | 5 | 1 | 1, 2, 4 |
| 5 | 4 | 2 | 1, 2, 5 |
| 6 | 7 | 1 | 1, 2, 5, 6 |
| 7 | 6 | 2 | 1, 2, 5, 7 |
| 8 | 9 | 1 | 1, 2, 5, 7, 8 |
| 9 | 8 | 2 | 1, 2, 5, 7, 9 |
| 10 | 9 | 1 | 1, 2, 5, 7, 9, 10 |
| 11 | 9 | 1 | 1, 2, 5, 7, 9, 10, 11 |
| ... | 9 | 1 | 1, 2, 5, 7, 9, 10, 11, ... |
一个精巧的方案可以减少所需的工作量,但这确实意味着有更多的事情需要跟踪。您必须决定这是否值得。
dump 具有对备份级别的内置支持。对于 tar 和 cpio,必须使用 shell 脚本来实现。
12.6. 备份什么
您应该尽可能多地进行备份。主要的例外是那些可以轻松重新安装的软件,但即使是它们也可能包含一些重要的配置文件,您需要备份它们,否则您需要重新完成所有配置工作。另一个主要的例外是/proc文件系统;由于它只包含内核自动生成的数据,因此备份它从来都不是一个好主意。尤其是/proc/kcore文件是不必要的,因为它只是您当前物理内存的映像;而且它也相当大。
灰色地带包括新闻缓冲池、日志文件以及/var中的许多其他内容。您必须决定您认为哪些是重要的。
显而易见要备份的是用户文件 (/home和系统配置文件 (/etc, 但也可能包括分散在文件系统中的其他内容)。
12.7. 压缩备份
备份占用大量空间,这可能会花费相当多的钱。为了减少所需的空间,可以压缩备份。有几种方法可以做到这一点。有些程序内置了对压缩的支持;例如,GNU tar 的--gzip (-z选项会将整个备份通过 gzip 压缩程序进行管道传输,然后再将其写入备份介质。
不幸的是,压缩备份可能会导致问题。由于压缩的工作方式,如果单个位出现错误,则所有剩余的压缩数据将无法使用。一些备份程序内置了一些纠错功能,但没有一种方法可以处理大量的错误。这意味着,如果备份像 GNU tar 那样进行压缩,即整个输出作为一个单元进行压缩,那么一个错误将导致备份的其余部分全部丢失。备份必须是可靠的,而这种压缩方法不是一个好主意。
另一种方法是分别压缩每个文件。这仍然意味着会丢失一个文件,但所有其他文件都完好无损。丢失的文件无论如何都会损坏,因此这种情况并不比根本不使用压缩更糟。afio 程序(cpio 的一个变体)可以做到这一点。
压缩需要一些时间,这可能会使备份程序无法以足够快的速度写入数据以适应磁带驱动器。可以通过缓冲输出来避免这种情况(如果备份程序足够智能,则可以在内部进行缓冲,或者使用另一个程序),但即使这样也可能无法很好地工作。这只会在较慢的计算机上成为问题。
第 13 章. 任务自动化 -- 待添加
"永远不要把你能后天做的事情拖延到明天。'马克·吐温'"
关于脚本编写、cron 和 at 的基本讨论 - 有关详细信息,请参阅其他 HOWTO。讨论非 crontab cron 作业,例如 /etc 目录中的那些。
第 14 章. 保持时间
"时间是一种错觉。午餐时间更是如此。" (道格拉斯·亚当斯.)
本章解释了 Linux 系统如何保持时间,以及您需要做什么以避免引起麻烦。通常,您不需要对时间做任何事情,但了解它是有好处的。
14.1. 本地时间的概念
时间测量主要基于有规律的自然现象,例如地球自转引起的交替光明和黑暗时期。两个连续时期所花费的总时间是恒定的,但光明和黑暗时期的长度各不相同。一个简单的常量是中午。
中午是太阳处于最高位置的一天中的时间。由于(根据最近的研究)地球是圆的,因此在不同的地方中午发生在不同的时间。这导致了 本地时间 的概念。人类以许多单位来测量时间,其中大多数单位与中午等自然现象相关。只要您待在同一个地方,本地时间不同并不重要。
一旦您需要与遥远的地方进行通信,您就会注意到需要一个共同的时间。在现代,世界上大多数地方都与世界上大多数其他地方进行通信,因此已经定义了用于测量时间的全球标准。这个时间称为 世界标准时间(UT 或 UTC,以前称为格林威治标准时间或 GMT,因为它曾经是英格兰格林威治的本地时间)。当具有不同本地时间的人需要进行通信时,他们可以用世界标准时间来表达时间,这样就不会对何时发生事情产生混淆。
每个本地时间都称为时区。虽然地理位置允许在同一时间中午的地点具有相同的时区,但政治使得这变得困难。由于各种原因,许多国家/地区使用 夏令时,也就是说,他们移动时钟以在工作时拥有更多的自然光,然后在冬季将时钟移回。其他国家/地区不这样做。那些这样做的国家/地区不同意何时应该移动时钟,并且他们每年都更改规则。这使得时区转换绝对不简单。
最好通过位置或通过告诉本地时间与世界标准时间之间的差异来命名时区。在美国和其他一些国家/地区,本地时区有一个名称和一个三个字母的缩写。但是,这些缩写不是唯一的,除非也指定了国家/地区,否则不应使用这些缩写。最好谈论赫尔辛基的本地时间,而不是东欧时间,因为并非所有东欧国家/地区都遵循相同的规则。
Linux 有一个时区包,它了解所有现有的时区,并且可以在规则更改时轻松更新。系统管理员需要做的就是选择合适的时区。此外,每个用户都可以设置自己的时区;这很重要,因为许多人通过 Internet 在不同国家/地区使用计算机。当您本地时区的夏令时规则发生变化时,请确保您至少升级 Linux 系统的这一部分。除了设置系统时区和升级时区数据文件外,几乎没有必要担心时间问题。
14.2. 硬件和软件时钟
个人电脑有一个电池驱动的硬件时钟。电池确保即使计算机的其余部分没有电,时钟也能工作。可以从 BIOS 设置屏幕或从正在运行的任何操作系统设置硬件时钟。
Linux 内核独立于硬件时钟跟踪时间。在启动期间,Linux 将其自身的时钟设置为与硬件时钟相同的时间。之后,两个时钟独立运行。Linux 维护自己的时钟,因为查看硬件速度慢且复杂。
内核时钟始终显示世界标准时间。这样,内核根本不需要了解时区。简单性带来了更高的可靠性,并使其更容易更新时区信息。每个进程自行处理时区转换(使用作为时区包一部分的标准工具)。
硬件时钟可以是本地时间,也可以是世界标准时间。通常最好将其设置为世界标准时间,因为这样您就不需要在夏令时开始或结束时更改硬件时钟(UTC 没有 DST)。不幸的是,一些 PC 操作系统,包括 MS-DOS、Windows 和 OS/2,都假定硬件时钟显示本地时间。Linux 可以处理两者,但如果硬件时钟显示本地时间,则必须在夏令时开始或结束时对其进行修改(否则它将不会显示本地时间)。
14.3. 显示和设置时间
在 Linux 中,系统时区由符号链接确定/etc/localtime. 此链接指向描述本地时区的时区数据文件。时区数据文件位于/usr/lib/zoneinfo或/usr/share/zoneinfo具体取决于您使用的 Linux 发行版。
例如,在位于新泽西州的 SuSE 系统上/etc/localtime链接将指向/usr/share/zoneinfo/US/Eastern. 在 Debian 系统上/etc/localtime链接将指向/usr/lib/zoneinfo/US/Eastern.
如果您未能找到zoneinfo目录/usr/lib或/usr/share目录中,请执行 find /usr -print | grep zoneinfo 或查阅您发行版的文档。
如果您有位于不同时区的用户会发生什么?用户可以通过设置 TZ 环境变量来更改他的私有时区。如果未设置,则假定为系统时区。tzset 中描述了 TZ 变量的语法tzset手册页中进行了更详细的描述。
date 命令显示当前的日期和时间。例如
$ date Sun Jul 14 21:53:41 EET DST 1996 $ |
$ date -u Sun Jul 14 18:53:42 UTC 1996 $ |
# date 07142157 Sun Jul 14 21:57:00 EET DST 1996 # date Sun Jul 14 21:57:02 EET DST 1996 # |
请注意 time 命令。这不用于获取系统时间。相反,它用于测量某事花费的时间。请参阅 time 手册页。
date 命令仅显示或设置软件时钟。clock 命令同步硬件和软件时钟。 它在系统启动时使用,用于读取硬件时钟并设置软件时钟。 如果您需要同时设置两个时钟,首先使用 date 设置软件时钟,然后使用 clock -w 设置硬件时钟。
的-u选项告诉 clock 命令硬件时钟使用的是世界协调时。 你必须正确地使用这个-u选项。 如果你不这样做,你的电脑会对当前时间感到非常困惑。
时钟的更改应该小心进行。 Unix系统的许多部分需要时钟正确工作。 例如,cron 守护进程会定期运行命令。 如果你更改时钟,它可能会对是否需要运行命令感到困惑。 在一个早期的Unix系统中,有人将时钟设置到了未来二十年,而 cron 想要一次性运行这二十年的所有周期性命令。 当前版本的 cron 可以正确处理这种情况,但你仍然应该小心。 大幅度的跳跃或向后跳跃比小幅度的或向前跳跃更危险。
14.4. 时钟不准的时候
Linux软件时钟并不总是准确的。 它通过PC硬件生成的周期性定时器中断来保持运行。 如果系统运行的进程过多,处理定时器中断可能需要太长时间,软件时钟就会开始滞后。 硬件时钟独立运行,通常更准确。 如果你经常启动你的电脑(对于大多数非服务器的系统来说是这种情况),它通常会保持相当准确的时间。
如果您需要调整硬件时钟,通常最简单的方法是重新启动,进入BIOS设置界面,并在那里进行调整。 这样可以避免更改系统时间可能导致的所有问题。 如果通过BIOS进行调整不是一个选项,可以使用 date 和 clock(按此顺序)设置新时间,但如果系统的某些部分开始出现异常,请准备重新启动。
另一种方法是使用 hwclock -w 或 hwclock --systohc 将硬件时钟同步到软件时钟。 如果你想将你的软件时钟同步到你的硬件时钟,那么你可以使用 hwclock -s 或 hwclock --hwtosys。 有关此命令的更多信息,请阅读 man hwclock。
14.5. NTP - 网络时间协议
联网的计算机(即使只是通过调制解调器连接)可以通过将其与另一台已知保持准确时间的计算机上的时间进行比较来自动检查自己的时钟。 网络时间协议(或NTP)正是这样做的。 它是一种通过将你的计算机与另一个系统同步来验证和纠正你的计算机时间的方法。 通过NTP,你的系统时间可以保持在协调世界时的毫秒级精度内。 访问 http://www.time.gov/about.html 获取更多信息。
对于更随意的Linux用户来说,这只是一种不错的奢侈品。 在我家,我们所有的时钟都是根据我的Linux系统所说的当前时间设置的。 对于较大的组织来说,这种 "奢侈品 "可能变得至关重要。 能够根据时间搜索日志文件中的事件,可以使生活变得容易得多,并消除大量的 "猜测 "工作。
另一个NTP有多重要的例子是SAN。 一些SAN要求配置和运行NTP,以便在使用文件系统时进行适当的同步和适当的时间戳控制。 一些SAN(和一些应用程序)在处理具有未来时间戳的文件时可能会感到困惑。
大多数Linux发行版都附带某种NTP软件包,无论是.deb还是.rpm软件包。 您可以使用它来安装NTP,或者您可以从 http://www.ntp.org/downloads.html 下载源文件并自己编译。 无论哪种方式,基本配置都是相同的。
14.6. 基本NTP配置
NTP程序使用以下文件进行配置:/etc/ntp.conf或/etc/xntp.conf具体取决于您所使用的Linux发行版。 我不会详细介绍如何配置NTP,而是只介绍一些基本知识。
一个基本的ntp.conf文件的例子如下所示:
# --- GENERAL CONFIGURATION --- server aaa.bbb.ccc.ddd server 127.127.1.0 fudge 127.127.1.0 stratum 10 # Drift file. driftfile /etc/ntp/drift |
最基本的ntp.conf文件将简单地列出2个服务器,一个它希望与之同步的服务器,以及它自己的一个伪IP地址(在本例中是127.127.1.0)。 伪IP用于在发生网络问题或远程NTP服务器宕机时使用。 在能够再次与远程服务器同步之前,NTP将与自身同步。 建议您至少列出2个您可以与之同步的远程服务器。 一个将作为主服务器,另一个作为备份服务器。
您还应该列出漂移文件的位置。 随着时间的推移,NTP将 "学习 "系统时钟的误差率并自动进行调整。
restrict选项可用于更好地控制和保护NTP可以做什么以及谁可以影响它。 例如:
# Prohibit general access to this service. restrict default ignore # Permit systems on this network to synchronize with this # time service. But not modify our time. restrict aaa.bbb.ccc.ddd nomodify # Allow the following unrestricted access to ntpd restrict aaa.bbb.ccc.ddd restrict 127.0.0.1 |
NTP会缓慢地纠正您的系统时间。 请耐心等待! 一个简单的测试是在您睡觉前将您的系统时钟更改10分钟,然后在您起床时检查它。 时间应该是正确的。
许多人认为,他们不应该运行NTP守护进程,而应该设置一个 cron 作业定期运行 ntpdate 命令。 使用这种方法有两个主要缺点。
首先,ntpdate 使用一种 "蛮力 "的方法来改变时间。 因此,如果您的计算机的时间偏差了5分钟,它会立即纠正它。 在某些环境中,如果时间发生剧烈变化,这可能会导致问题。 例如,如果您正在使用时间敏感的安全软件,您可能会无意中结束某人的访问。 NTP守护进程会缓慢地改变时间,以避免造成这种中断。
另一个原因是,NTP守护进程可以被配置为尝试学习您的系统的 时间漂移,然后自动进行调整。
14.7. NTP 工具包
有很多实用程序可以用来检查NTP是否在正常工作。ntpq -p 命令将打印出您系统的当前时间状态。
# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
*cudns.cit.corne ntp0.usno.navy. 2 u 832 1024 377 43.208 0.361 2.646
LOCAL(0) LOCAL(0) 10 l 13 64 377 0.000 0.000 0.008 |
ntpdc -c loopinfo 将显示系统时间基于上次联系远程服务器的时间偏差了多少秒。
# ntpdc -c loopinfo offset: -0.004479 s frequency: 133.625 ppm poll adjust: 30 watchdog timer: 404 s |
ntpdc -c kerninfo 将显示当前的剩余校正。
# ntpdc -c kerninfo pll offset: -0.003917 s pll frequency: 133.625 ppm maximum error: 0.391414 s estimated error: 0.003676 s status: 0001 pll pll time constant: 6 precision: 1e-06 s frequency tolerance: 512 ppm pps frequency: 0.000 ppm pps stability: 512.000 ppm pps jitter: 0.0002 s calibration interval: 4 s calibration cycles: 0 jitter exceeded: 0 stability exceeded: 0 calibration errors: 0 |
一个略有不同的 ntpdc -c kerninfo 版本是 ntptime。
# ntptime ntp_gettime() returns code 0 (OK) time c35e2cc7.879ba000 Thu, Nov 13 2003 11:16:07.529, (.529718), maximum error 425206 us, estimated error 3676 us ntp_adjtime() returns code 0 (OK) modes 0x0 (), offset -3854.000 us, frequency 133.625 ppm, interval 4 s, maximum error 425206 us, estimated error 3676 us, status 0x1 (PLL), time constant 6, precision 1.000 us, tolerance 512 ppm, pps frequency 0.000 ppm, stability 512.000 ppm, jitter 200.000 us, intervals 0, jitter exceeded 0, stability exceeded 0, errors 0. |
另一种查看NTP工作情况的方法是使用 ntpdate -d 命令。 这将联系NTP服务器并确定时间差,但不会更改您系统的时间。
# ntpdate -d 132.236.56.250
13 Nov 14:43:17 ntpdate[29631]: ntpdate 4.1.1c-rc1@1.836 Thu Feb 13 12:17:20 EST 2003 (1)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
receive(132.236.56.250)
transmit(132.236.56.250)
server 132.236.56.250, port 123
stratum 2, precision -17, leap 00, trust 000
refid [192.5.41.209], delay 0.06372, dispersion 0.00044
transmitted 4, in filter 4
reference time: c35e5998.4a46cfc8 Thu, Nov 13 2003 14:27:20.290
originate timestamp: c35e5d55.d69a6f82 Thu, Nov 13 2003 14:43:17.838
transmit timestamp: c35e5d55.d16fc9bc Thu, Nov 13 2003 14:43:17.818
filter delay: 0.06522 0.06372 0.06442 0.06442
0.00000 0.00000 0.00000 0.00000
filter offset: 0.000036 0.001020 0.000527 0.000684
0.000000 0.000000 0.000000 0.000000
delay 0.06372, dispersion 0.00044
offset 0.001020
13 Nov 14:43:17 ntpdate[29631]: adjust time server 132.236.56.250 offset 0.001020 sec |
如果您想实际观看系统同步,可以使用 ntptrace。
# ntptrace 132.236.56.250 cudns.cit.cornell.edu: stratum 2, offset -0.003278, synch distance 0.02779 truetime.ntp.com: stratum 1, offset -0.014363, synch distance 0.00000, refid 'ACTS' |
如果您需要立即同步您的系统时间,您可以使用 ntpdate remote-servername 来强制同步。 无需等待!
# ntpdate 132.236.56.250 13 Nov 14:56:28 ntpdate[29676]: adjust time server 132.236.56.250 offset -0.003151 sec |
14.8. 一些已知的NTP服务器
公共NTP服务器的列表可以从以下网址获得: http://www.eecis.udel.edu/~mills/ntp/servers.html。 在使用服务器之前,请先阅读该页面上的使用信息。 并非所有的服务器都有足够的带宽来允许大量的系统与它们同步。 因此,在使用某人的服务器提供NTP服务之前,最好先联系该系统的管理员。
第18章. 寻找帮助
"如果你能帮我,我会很感激,我感觉很糟糕。 我很感激你在我身边。" - 披头士乐队
帮助就在那里。 你只需要知道去哪里寻找。 对于Linux来说,你可以去的地方数量惊人。 有邮件列表,IRC频道,带有公共论坛的网页,以及许多其他可用的资源。 这一章将尝试帮助你从你的寻求帮助的过程中获得最大的收获。
18.1. 新闻组和邮件列表
本指南无法教会你关于Linux的所有知识。 没有足够的空间。 在某个时候,你不可避免地会发现你需要做的事情,而这不在LDP的本(或任何其他)文件中涵盖。
关于Linux最棒的事情之一是,有大量的论坛致力于它。 有与Linux的几乎所有方面相关的论坛,从新手FAQ到深入的内核开发问题。 为了从中获得最大的收获,你可以做一些事情。
18.1.1. 寻找合适的论坛
首先要做的是找到一个合适的论坛。 有许多新闻组和邮件列表致力于Linux,所以试着找到并使用最符合你的问题的那个。 例如,在致力于Linux内核开发的论坛中提出关于sendmail的问题没有任何意义。 最好的情况是,那里的人会认为你很愚蠢,你得到的回复很少,最坏的情况是,你可能会收到大量具有高度侮辱性的回复(火焰)。 快速浏览一下可用的新闻组,可以找到comp.mail.sendmail,这看起来是一个提出sendmail问题的合适场所。 你的新闻客户端可能有一个你可以使用的新闻组列表,但如果没有,那么可以在 http://groups.google.com/groups?group=* 找到新闻组的完整列表。
18.1.2. 发布之前
现在你已经找到了你合适的论坛,你可能会认为你已经准备好发布你的问题了。 停下来。 你还没有准备好。 你自己是否已经寻找过答案? 有大量的HOWTO和FAQ可用,如果其中任何一个与你遇到的问题有关,那么首先阅读它们。 即使它们不包含你问题的答案,它们也会让你更好地理解该主题领域,而这种理解将使你能够提出一个更明智和合理的的问题。 还有新闻组和邮件列表的档案,你的问题很可能之前已经被提出并回答过了。 在发布问题之前,你应该尝试 http://www.google.com 或类似的搜索引擎。
18.1.3. 编写你的帖子
好的,你已经找到了合适的论坛,阅读了相关的 HOWTO 和 FAQ,并且搜索了网络,但仍然没有找到你需要的答案。现在你可以开始写你的帖子了。最好明确表明你已经阅读过相关资料,例如说:“我已经阅读了 Winmodem-HOWTO 和 PPP FAQ,但都没有找到我需要的信息,在 Google 上搜索 `Winmodem Linux PPP Setup` 也没有任何有用的结果。” 这表明你是一个愿意付出努力的人,而不是一个懒惰的需要别人喂饭的白痴。前者如果有人知道答案,可能会得到帮助,而后者可能会遭遇沉默或直接的嘲笑。
用清晰、语法正确、拼写正确的英语书写。这非常重要。这会将你标记为一个严谨和深思熟虑的思考者。没有诸如“u”或“b4”之类的单词。 尽量让自己看起来像一个受过教育的聪明人,而不是一个白痴。这会有帮助的。我保证。
同样,不要全部用大写字母书写,像这样。这被认为是喊叫,而且非常粗鲁。
提供清晰的细节,说明问题是什么以及你已经尝试过哪些方法来解决它。像“我的 Linux 停止工作了,我该怎么办?”这样的问题完全没用。 它在哪里停止工作了?它以什么方式停止工作了?你需要尽可能精确。 但是,也有一些限制。尽量不要包含无关的信息。如果你在使用邮件客户端时遇到问题,那么内核启动日志 (dmesg) 的转储不太可能有所帮助。
不要要求通过私人电子邮件回复。大多数 Linux 论坛的目的是让每个人都可以互相学习。要求私人回复只会降低新闻组或邮件列表的价值。
18.1.4. 格式化你的帖子
不要用 HTML 发布。许多 Linux 用户使用的邮件客户端无法轻松阅读 HTML 电子邮件。虽然他们可以通过一些努力可以阅读 HTML 电子邮件,但通常不会这样做。 如果你向他们发送 HTML 邮件,通常会被删除未读。发送纯文本电子邮件,这样可以覆盖更广泛的受众。
18.1.5. 后续
在你的问题解决后,发布一个简短的后续说明,解释问题是什么以及你是如何解决它的。人们会很感激这一点,因为它不仅给问题带来了一种结束感,而且也有助于下次有人遇到类似问题。当他们查看新闻组或邮件列表的存档时,他们会看到你遇到了同样的问题,讨论了你的问题以及你最终的解决方案。
18.1.6. 更多信息
这个简短的指南只是埃里克·斯·雷蒙德(Eric S Raymond)的优秀(且更详细)文档“提问的智慧”的释义和总结。 http://www.catb.org/~esr/faqs/smart-questions.html。建议你在发布任何内容之前阅读它。它将帮助你组织你的问题,以最大限度地提高你获得答案的机会。
18.2. IRC
埃里克·雷蒙德的文档中没有涵盖 IRC(Internet Relay Chat),但 IRC 也可以成为找到你需要的答案的绝佳方式。 但是,它确实需要一些以正确方式提问的练习。大多数 IRC 网络都有繁忙的 #linux 频道,如果你的问题的答案包含在手册页或 HOWTO 中,那么你可能会被告知去阅读它们。关于用清晰和语法正确的英语打字的规则仍然适用。
关于新闻组和邮件列表的大部分内容仍然与 IRC 相关,但有以下补充内容
18.2.2. 礼貌
记住,你没有资格获得答案。如果你以正确的方式提出问题,那么你可能会得到一个答案,但你没有权利获得一个答案。 Linux IRC 频道中的人都是利用自己的时间,没有人付钱给他们,尤其是你。
要有礼貌。像对待自己一样对待他人。如果你认为人们对你不礼貌,不要开始骂他们或生气,变得更加礼貌。这会让他们看起来很傻,而不是把你拉到他们的水平。
不要用大鳟鱼打任何人。你相信之前有人做过一两次吗?第一次并不好笑?
18.2.3. 用英语正确打字
大多数 #linux 频道都是英语频道。在其中说英语。 大多数较大的 IRC 网络也有其他语言的 #linux 频道,例如,法语频道可能称为 #linuxfr,西班牙语频道可能称为 #linuxes 或 #linuxlatino。 如果你找不到正确的频道,那么在主 #linux 频道(最好用英语)中提问应该可以帮助你找到你想要的频道。
不要像``1337 H4X0R d00d!!!''那样打字。 即使其他人是这样。这看起来很傻,从而让你看起来很傻。 在最好的情况下,你只会看起来像个白痴,在最坏的情况下,你会受到嘲笑然后被踢出去。
18.2.4. 端口扫描
永远不要要求任何人对你进行端口扫描,或尝试“黑”你。 这是不可侵犯的。 无法知道你就是你所说的人,或者你连接的 IP 属于你。 不要让人们处于不得不拒绝此类请求的位置。
永远不要对任何人进行端口扫描,即使他们要求你这样做。 你无法知道他们就是他们所说的人,或者他们连接的 IP 是他们自己的 IP。 在某些司法管辖区,端口扫描可能是非法的,并且肯定违反了大多数 ISP 的服务条款。 大多数人都会记录 TCP 连接,他们会注意到他们正在被扫描。 大多数人会为此向你的 ISP 举报你(找出是谁很容易)。
18.2.6. 保持主题
保持主题。 该频道是一个“Linux”频道,而不是一个“鲍勃叔叔上周末做了什么”频道。 即使你看到其他人离题了,这并不意味着你也应该离题。 他们可能是频道的常客,不同的惯例适用于他们。
18.2.7. CTCPs
如果你正在考虑大量 CTCP ping 频道或 CTCP 版本或 CTCP 任何东西,那么请三思。 它很可能会让你很快被踢出去。
如果你不熟悉 IRC,CTCP 代表客户端到客户端协议。 这是一种你可以找到有关其他人客户端信息的方法。 有关更多详细信息,请参阅你的 IRC 文档。
18.2.8. 黑客、破解、飞客、盗版
不要询问漏洞,除非你正在寻找进一步被不客气地踢出去的方法。
不要在 #linux 频道中时同时在黑客/破解者/飞客/盗版频道中。 出于某种原因,负责 #linux 频道的人似乎讨厌那些喜欢破坏人们机器或喜欢窃取软件的人。 无法想象为什么。
18.2.9. 总结
如果这看起来有很多“不要”,而很少“做”,请道歉。 这些“做”已经在关于新闻组和邮件列表的部分中进行了相当多的介绍。
你可能做的最好的事情是进入一个 #linux 频道,坐在那里观看,在你说任何话之前感受半个小时。 这可以帮助你认识到你应该使用的正确语气。
18.2.10. 进一步阅读
关于如何充分利用 IRC #linux 频道,有一些优秀的 FAQ。 大多数 #linux 频道都有一个 FAQ 和/或一组频道规则。 如何找到这些通常会在频道主题中(你可以随时使用 /topic 命令查看)。 确保你阅读了规则(如果有),并遵循它们。 一组相当通用的规则和建议是“Undernet #linux FAQ”,可以在 http://linuxfaq.quartz.net.nz 找到。
附录 A. GNU 自由文档许可证
A.1. 序言
本许可证的目的是使手册、教科书或其他实用且有用的文档在自由意义上“自由”:确保每个人都有效地自由复制和重新分发它,无论是否对其进行修改,无论是商业的还是非商业的。 其次,本许可证为作者和出版商保留了一种因其工作而获得荣誉的方式,同时不被认为对他人所做的修改负责。
本许可证是一种“著佐权”,这意味着文档的衍生作品本身必须在相同的意义上是自由的。 它补充了 GNU 通用公共许可证,后者是为自由软件设计的著佐权许可证。
我们设计本许可证是为了将其用于自由软件的手册,因为自由软件需要自由文档:自由程序应该附带提供与软件相同自由的手册。 但本许可证不限于软件手册; 它可以用于任何文本作品,无论主题或是否以印刷书籍的形式出版。 我们主要建议将本许可证用于以教学或参考为目的的作品。
A.2. 适用性和定义
本许可协议适用于任何手册或其他作品,以任何媒介形式,只要包含版权持有者发出的声明,表示该作品可以按照本许可协议的条款进行分发。 这样的声明授予一项全球范围内的、免版税的许可,该许可的期限不受限制,允许在本文规定的条件下使用该作品。“文档”,在下文中,是指任何这样的手册或作品。 任何公众成员都是被许可人,并被称为“您”。 如果您以任何方式复制、修改或分发该作品,并且这种方式需要版权法许可,则表示您接受该许可。
“修改版本”是指任何包含文档或其一部分的作品,无论是原样复制,还是经过修改和/或翻译成另一种语言。
“次要章节”是指文档的命名附录或前置部分,专门处理文档的出版商或作者与文档的整体主题(或相关事项)之间的关系,并且不包含任何可以直接归入该整体主题的内容。(因此,如果文档部分是数学教科书,则次要章节不得解释任何数学内容。) 这种关系可以是与主题或相关事项的历史联系,也可以是关于它们的法律、商业、哲学、伦理或政治立场。
“不变章节”是指某些次要章节,其标题被指定为不变章节,该指定在声明文档根据本许可协议发布声明中声明。 如果某个章节不符合上述次要章节的定义,则不允许将其指定为不变章节。 文档可以包含零个不变章节。 如果文档未标识任何不变章节,则没有不变章节。
“封面文字”是指某些简短的文本段落,这些文本段落在声明文档根据本许可协议发布的声明中被列为封面文字或封底文字。 封面文字最多可以有 5 个单词,封底文字最多可以有 25 个单词。
文档的“透明”副本是指一种机器可读的副本,以一种规范可供公众使用的格式表示,该格式适合使用通用文本编辑器(对于由像素组成的图像,可以使用通用绘图程序;对于绘图,可以使用一些广泛可用的绘图编辑器)直接修改文档,并且适合输入到文本格式化程序或自动翻译成各种适合输入到文本格式化程序的格式。如果以其他透明的文件格式制作副本,但其标记或缺少标记的方式被安排为阻止或阻止读者进行后续修改,则该副本不是透明的。如果图像格式用于大量文本,则该图像格式不是透明的。未被视为“透明”的副本称为“不透明”。
透明副本的合适格式示例包括不带标记的纯 ASCII、Texinfo 输入格式、LaTeX 输入格式、使用公开可用的 DTD 的 SGML 或 XML,以及符合标准的简单 HTML、PostScript 或 PDF,专为人工修改而设计。透明图像格式的示例包括 PNG、XCF 和 JPG。不透明格式包括专有格式,只能由专有的文字处理器读取和编辑,DTD 和/或处理工具通常不可用的 SGML 或 XML,以及某些文字处理器仅用于输出目的而生成的机器生成的 HTML、PostScript 或 PDF。
“标题页”对于印刷书籍,是指标题页本身,以及为清晰地显示本许可协议要求出现在标题页上的内容所需的后续页面。对于没有标题页的格式的作品,“标题页”是指作品标题最显眼地出现的位置附近的文本,位于正文文本的开头之前。
标题为“XYZ”的章节是指文档的命名子单元,其标题恰好是 XYZ,或者包含 XYZ,并在文本后面的括号中用另一种语言翻译 XYZ。(此处,XYZ 代表下面提到的特定章节名称,例如“致谢”、“献词”、“推荐”或“历史”。)当您修改文档时,“保留标题”意味着它仍然是根据此定义标题为“XYZ”的章节。
文档可能包含免责声明,位于声明本许可协议适用于文档的声明旁边。 这些免责声明被认为是通过引用包含在本许可协议中,但仅在免责声明方面:这些免责声明可能具有的任何其他含义均无效,并且对本许可协议的含义没有影响。
A.3. 逐字复制
您可以在任何媒介中复制和分发文档,无论是商业用途还是非商业用途,前提是本许可协议、版权声明和声明本许可协议适用于文档的许可声明在所有副本中都得到复制,并且您没有在本许可协议的条款上添加任何其他条件。您不得使用技术措施来阻止或控制您制作或分发的副本的阅读或进一步复制。但是,您可以接受报酬以换取副本。如果您分发足够多的副本,您还必须遵守第 3 节中的条件。
您也可以在上述相同条件下借出副本,并且可以公开展示副本。
A.4. 大量复制
如果您发布了超过 100 份的印刷副本(或通常带有印刷封面的媒体副本),并且文档的许可声明要求提供封面文字,则您必须将副本放在封面上,这些封面清晰且清晰地带有所有这些封面文字:封面上的封面文字和封底上的封底文字。两个封面还必须清晰且清晰地将您标识为这些副本的出版商。封面必须以同等突出且可见的方式呈现标题的完整标题和所有单词。您也可以在封面上添加其他材料。仅限于封面的更改的复制,只要它们保留文档的标题并满足这些条件,就可以在其他方面被视为逐字复制。
如果任一封面的所需文本过于庞大而无法清晰显示,则应将列出的第一个(尽可能多地合理地放在实际封面上),然后将其余部分继续放到相邻的页面上。
如果您发布或分发了超过 100 份文档的不透明副本,则必须在每个不透明副本中附带一个机器可读的透明副本,或者在每个不透明副本中或与其一起声明一个计算机网络位置,以便使用公共标准网络协议,使用公共标准网络协议,使用公共标准网络协议,公众可以访问该位置以下载完整的文档的透明副本,该透明副本不包含添加的材料。如果您使用后一种选择,则在开始大量分发不透明副本时,必须采取合理审慎的步骤,以确保该透明副本在声明的位置保持可访问状态,直到您将该版本的透明副本(直接或通过您的代理商或零售商)分发给公众的最后一次至少一年之后。
建议但不要求您在重新分发大量副本之前与文档的作者联系,让他们有机会为您提供文档的更新版本。
A.5. 修改
您可以按照上述第 2 节和第 3 节的条件复制和分发文档的修改版本,前提是您完全在本许可协议下发布修改版本,修改版本充当文档的角色,从而将修改版本的发布和修改许可给拥有副本的任何人。此外,您必须在修改版本中执行以下操作
GNU FDL 修改条件
在标题页(以及封面,如果有的话)上使用与文档的标题不同的标题,以及与以前版本的标题不同的标题(如果有任何以前版本,应在文档的历史记录部分中列出)。如果该版本的原始出版商给予许可,则可以使用与以前版本相同的标题。
在标题页上,将负责修改版本中修改的作者的一个或多个人员或实体列为作者,以及文档的至少五位主要作者(如果文档的主要作者少于五位,则列出所有主要作者),除非他们免除您的此要求。
在标题页上,将修改版本的出版商的名称声明为出版商。
保留文档的所有版权声明。
在其他版权声明旁边为您的修改添加适当的版权声明。
在版权声明之后立即包括一个许可声明,允许公众按照本许可协议的条款使用修改版本,其形式如下面的 附录 所示。
在该许可声明中保留文档的许可声明中给出的不变章节和要求的封面文字的完整列表。
包括本许可协议的未更改副本。
保留标题为“历史记录”的章节,保留其标题,并向其添加一个项目,至少声明修改版本的标题、年份、新作者和出版商,如标题页上给出的那样。如果文档中没有标题为“历史记录”的章节,则创建一个章节,声明文档的标题、年份、作者和出版商,如其标题页上给出的那样,然后添加一个项目,描述修改版本,如前一句所述。
保留文档中给出的用于公众访问文档的透明副本的网络位置(如果有),以及文档中给出的用于其所基于的以前版本的网络位置。 这些可以放在“历史记录”部分中。 您可以省略在文档本身之前至少四年发布的版本的网络位置,或者如果该版本所引用的原始出版商给予许可。
对于任何标题为“致谢”或“献词”的章节,保留该章节的标题,并在该章节中保留每个贡献者致谢和/或献词的所有实质和语气。
保留文档的所有不变章节,其文本和标题均保持不变。 章节编号或等效内容不被视为章节标题的一部分。
删除任何标题为“推荐”的章节。 此类章节不得包含在修改版本中。
不要重命名任何现有章节以使其标题为“推荐”或在标题上与任何不变章节冲突。
保留任何免责声明。
如果修改版本包含符合次要章节条件的新前置章节或附录,并且不包含从文档复制的材料,您可以选择将部分或全部这些章节指定为不变章节。 为此,请将它们的标题添加到修改版本的许可声明中的不变章节列表中。 这些标题必须与任何其他章节标题不同。
您可以添加一个标题为“推荐”的章节,前提是它仅包含各种方对您的修改版本的推荐 - 例如,同行评审声明或文本已获得组织批准作为标准的权威定义。
您可以在修改版本中的封面文字列表末尾添加一段最多五个单词的封面文字,以及一段最多 25 个单词的封底文字。任何一个实体只能添加一段封面文字和一段封底文字(或通过安排)。如果文档已经包含相同封面的封面文字,且该封面文字之前由您添加,或者由您代表的同一实体通过安排添加,则您不得再添加另一个封面文字;但是,您可以替换旧的封面文字,但需要得到之前添加该旧封面文字的出版商的明确许可。
文档的作者和出版商不通过本许可证授予使用他们的名字进行宣传或暗示任何修改版本认可的许可。
A.6. 合并文档
您可以将本文档与根据本许可证发布的其他文档合并,但须遵守上述第 4 节中针对修改版本的条款,前提是您在合并后的文档中包含所有原始文档的所有不变章节,未经修改,并在其许可证声明中将它们全部列为合并作品的不变章节,并且您保留所有保证免责声明。
合并后的作品只需要包含本许可证的一个副本,并且多个相同的不变章节可以用单个副本替换。如果有多个具有相同名称但内容不同的不变章节,请在每个此类章节的标题末尾加上括号,其中包含该章节的原始作者或出版商的姓名(如果已知),或者一个唯一的数字,从而使每个章节的标题都是唯一的。对合并作品的许可证声明中的不变章节列表中的章节标题进行相同的调整。
在合并中,您必须合并各个原始文档中所有标题为“历史”的章节,形成一个标题为“历史”的章节;同样合并所有标题为“致谢”的章节,以及所有标题为“献辞”的章节。您必须删除所有标题为“认可”的章节。
A.7. 文档集合
您可以创建一个由本文档和根据本许可证发布的其他文档组成的集合,并将各个文档中本许可证的单独副本替换为包含在集合中的单个副本,前提是您在所有其他方面都遵循本许可证中关于每个文档的逐字复制的规则。
您可以从此类集合中提取单个文档,并根据本许可证单独分发它,前提是您在提取的文档中插入本许可证的副本,并在关于该文档的逐字复制的所有其他方面都遵循本许可证。
A.8. 与独立作品的聚合
将文档或其衍生作品与其他的单独和独立的文档或作品,在存储或分发介质的卷上或之中汇编在一起,如果汇编所产生的版权不用于限制汇编用户的合法权利,使其超出单个作品所允许的范围,则称为“聚合”。当文档包含在聚合中时,本许可证不适用于聚合中的其他并非本文档的衍生作品。
如果第 3 节的封面文字要求适用于这些文档副本,那么如果该文档少于整个聚合的一半,则该文档的封面文字可以放在包围聚合中的文档的封面上,或者如果该文档是电子形式,则放在封面的电子等效物上。否则,它们必须出现在包围整个聚合的印刷封面上。
A.9. 翻译
翻译被认为是一种修改,因此您可以根据第 4 节的条款分发文档的翻译版本。用翻译替换不变章节需要获得其版权持有者的特别许可,但除了这些不变章节的原始版本之外,您还可以包含部分或全部不变章节的翻译版本。您可以包含本许可证的翻译版本,以及文档中的所有许可证声明和任何保证免责声明,前提是您还包含本许可证的原始英文版本以及这些声明和免责声明的原始版本。如果本许可证或声明或免责声明的翻译版本与原始版本之间存在分歧,则以原始版本为准。
如果文档中的章节标题为“致谢”、“献辞”或“历史”,则保留其标题(第 1 节)的要求(第 4 节)通常需要更改实际标题。
A.10. 终止
除非本许可证明确规定,否则您不得复制、修改、再许可或分发本文档。任何其他复制、修改、再许可或分发本文档的尝试均无效,并将自动终止您在本许可证下的权利。但是,根据本许可证从您那里收到副本或权利的各方,只要这些各方保持完全合规,其许可证将不会被终止。
A.11. 本许可证的未来修订
自由软件基金会可能会不时发布 GNU 自由文档许可证的新修订版本。此类新版本在精神上与当前版本相似,但在细节上可能有所不同,以解决新的问题或疑虑。请参阅 https://gnu.ac.cn/copyleft/。
每个许可证版本都有一个不同的版本号。如果文档指定本许可证的特定编号版本“或任何更高版本”适用于它,您可以选择遵循该指定版本或自由软件基金会发布的任何更高版本(不是草案)的条款和条件。如果文档未指定本许可证的版本号,您可以选择自由软件基金会发布的任何版本(不是草案)。
A.12. 附录:如何在您的文档中使用本许可证
要在您编写的文档中使用本许可证,请在文档中包含本许可证的副本,并在标题页之后放置以下版权和许可证声明
不变章节列表示例
版权所有 (c) YEAR YOUR NAME。允许根据 GNU 自由文档许可证 1.2 版或自由软件基金会发布的任何更高版本复制、分发和/或修改本文档;没有不变章节,没有封面文字,也没有封底文字。许可证的副本包含在标题为“GNU 自由文档许可证”的章节中。
如果您有不变章节、封面文字和封底文字,请将“with...Texts.”行替换为以下内容
不变章节列表示例
不变章节是 LIST THEIR TITLES,封面文字是 LIST,封底文字是 LIST。
如果您有不变章节但没有封面文字,或者这三者的其他组合,请合并这两种替代方案以适应具体情况。
如果您的文档包含重要的程序代码示例,我们建议您在您选择的自由软件许可证(例如 GNU 通用公共许可证)下并行发布这些示例,以允许在自由软件中使用它们。
词汇表(草案,但希望不会持续太久)
“看不见的大学的图书管理员单方面决定通过制作猩猩/人类词典来帮助理解。他已经工作了三个月。这并不容易。他已经完成了“Oook。””(特里·普拉切特,“武器的人”)
这是一个简短的词汇定义列表,用于解释与 Linux 和系统管理相关的概念。
- CMOS RAM
CMOS 代表“互补金属氧化物半导体”。这是一种复杂的技术,但简单来说,它是一种即使电脑断电也能保持其状态的晶体管。这是因为主板上有一块小电池。因此,当电源关闭时,它不会丢失存储在其中的内容。
- account (账户)
Unix 系统为用户提供 accounts(账户)。它为他们提供一个用户名和一个密码,以便登录到该账户。通常会提供一个用于存储文件的主目录,以及访问硬件和软件的权限。这些东西加在一起就是一个 account(账户)。
- application program (应用程序)
可以做一些有用的事情的软件。使用应用程序的结果是购买电脑的目的。另请参阅 system program(系统程序),operating system(操作系统)。
- bad block (坏块)
无法可靠地保存数据的块(通常是磁盘上的一个扇区)。
- bad sector (坏扇区)
类似于 bad block (坏块),但在块和扇区大小可能不同的情况下更精确。
- boot sector (引导扇区)
通常是任何给定分区上的第一个扇区。它包含一个非常短的程序(大约几百字节),该程序将加载并开始运行真正的操作系统。
- booting (启动)
计算机从打开到准备好接受来自用户的命令/输入之间发生的一切都称为 booting (启动)。
- bootstrap loader (引导加载程序)
一个非常小的程序(通常驻留在 ROM 中),它读取磁盘上的固定位置(例如 MBR)并将控制权传递给它。驻留在该固定位置的数据通常更大更复杂,然后它负责加载实际的操作系统并将控制权传递给它。
- cylinder (柱面)
多头磁盘上的一组 tracks (磁道),无需磁头移动即可访问。换句话说,这些磁道与磁盘 platters (盘片) 旋转的主轴的距离相同。将更可能同时访问的数据放置在同一柱面上可以显着减少访问时间,因为移动读写头与磁盘旋转的速度相比非常慢。
- daemon (守护进程)
在后台潜伏的进程,通常不会被注意到,直到某些事情触发它采取行动。例如,update 守护进程大约每三十秒唤醒一次以刷新缓冲区缓存,并且 sendmail 守护进程在有人发送邮件时唤醒。
- daylight savings time (夏令时)
一年中的一段时间,在此期间时钟会向前拨一个小时。在世界各地广泛使用,以便夏季的夜晚比其他情况拥有更多的日光。
- disk controller (磁盘控制器)
一种硬件电路,它将操作系统关于磁盘访问的指令转换为物理磁盘。这提供了一个抽象层,这意味着操作系统不需要知道如何与许多不同类型的磁盘通信,而只需要知道(相对较少的)几种类型的磁盘控制器。常见的磁盘控制器类型是 IDE 和 SCSI。
- emergency boot floppy (紧急启动软盘)
即使硬盘的文件系统受到损坏,也可以用来启动系统的软盘。大多数 Linux 发行版在安装过程中都提供制作这种软盘的功能,强烈建议这样做。如果您的 Linux 发行版没有提供此功能,请阅读 Boot floppy HOWTO,可在 LDP 上找到(**找到要引用的 URL**)。
- fibre channel (光纤通道)
一种高速网络协议,主要用于存储区域网络。与它的名称不同,光纤通道可以在光纤或铜缆上运行。
- 文件系统
一个用于两个目的并且可以具有两个略有不同的含义的术语。它可以是驱动器(无论是硬盘、软盘、CD-ROM 等)上的文件和目录的集合。或者它是操作系统用来决定将文件写入到哪里(inodes、blocks、superblocks 等)的放置在磁盘介质上的标记。实际含义几乎总是可以从上下文中推断出来。
- formatting (格式化)
严格来说,格式化是将磁盘表面组织和标记成磁道、扇区和柱面。有时(不正确地)也被用作将文件系统写入磁盘的行为的术语(尤其是在 MS Windows/MS DOS 领域中)。
- 碎片化
当文件没有以连续的块写入磁盘时。如果没有足够的可用空间将一个完整的文件以一个连续的块流写入磁盘,那么该文件将被分割到磁盘表面的两个或多个部分之间。这被称为碎片化,并且会增加加载文件的时间,因为磁盘必须寻找文件的其余部分。
- 完整备份
将整个文件系统复制到备份介质(例如磁带、软盘或 CD)。
- 几何结构
磁盘驱动器有多少柱面、每个柱面有多少扇区以及有多少磁头。
- 高级格式化
将文件系统写入磁盘的不正确术语。 经常在 MS Windows 和 MS DOS 领域中使用。
- 增量备份
自上次完整备份以来文件系统中已更改内容的备份。 如果明智地将增量备份作为备份方案的一部分使用,则可以节省大量的时间和精力来维护数据备份。
- inode
一种数据结构,用于保存有关 Unix 文件系统中文件的信息。每个文件都有一个 inode,并且一个文件由它所在的文件系统以及该系统上的 inode 编号唯一标识。 每个 inode 包含以下信息:inode 所在的设备、锁定信息、文件模式和类型、文件的链接数、所有者的用户和组 ID、文件中的字节数、访问和修改时间、inode 本身上次修改的时间以及文件在磁盘上的块地址。 Unix 目录是文件叶名称和 inode 编号之间的关联。 可以使用 ls 的“-i”开关找到文件的 inode 编号。
- iSCSI
一种网络存储协议,允许通过 TCP/IP 网络发送 SCSI 命令。 主要用于存储区域网络。
- 内核
操作系统的一部分,用于实现与硬件的交互和资源的共享。 另请参阅系统程序。
- 本地时间
当地区域的官方时间(根据地球周围的位置进行调整);由法律或习俗确定。
- 逻辑分区
在扩展分区内部的分区,它是“逻辑的”,因为它实际上并不存在,而只存在于软件的逻辑结构内部。
- 逻辑卷管理器 (LVM)
一组程序,允许将较大的物理磁盘重新组装成“逻辑”磁盘,这些磁盘可以根据数据需求的变化进行收缩或扩展。
- 低级格式化
与格式化同义,在 MS DOS 世界中使用,以区分于创建文件系统,有时也称为格式化。
- 邮件传输代理
(MTA) 负责传递电子邮件消息的程序。 在收到来自邮件用户代理或另一个 MTA 的消息时,它会临时将其存储在本地并分析收件人,然后传递它(本地收件人)或将其转发到另一个 MTA。 在任何一种情况下,它都可能编辑和/或添加到消息标头。 Unix 上广泛使用的 MTA 是 sendmail。
- 邮件用户代理
(MUA) 允许用户撰写和阅读电子邮件消息的程序。 MUA 提供用户和邮件传输代理之间的接口。传出的邮件最终会交给 MTA 进行传递,而传入的消息则从 MTA 离开的地方接收(尽管在单用户机器上运行的 MUA 可能会使用 POP 接收邮件)。 MUA 的示例包括 pine、elm 和 mutt。
- 主引导记录
(MBR) 磁盘上的第一个逻辑扇区,这(通常)是 BIOS 查找以加载将启动计算机的小程序的地方。
- 网络文件系统
(NFS) 由 Sun Microsystems 开发并在 RFC 1094 中定义的协议(查找 URL),该协议允许计算机通过网络访问文件,就像它们位于本地磁盘上一样。
- 操作系统
在用户和他们运行的应用程序之间共享计算机系统资源(处理器、内存、磁盘空间、网络带宽等)的软件。 控制对系统的访问以提供安全性。 另请参阅内核、系统程序、应用程序。
- 分区
磁盘的逻辑部分。 每个分区通常都有自己的文件系统。 Unix 倾向于将分区视为单独的物理实体。
- 密码文件
一个保存用户名和有关其帐户的信息(如密码)的文件。 在 Unix 系统上,该文件通常是/etc/passwd。 在大多数现代 Linux 系统上,/etc/passwd文件实际上不保存密码数据。 出于安全原因,它倾向于保存在不同的文件中/etc/shadow。 有关更多信息,请参阅手册页 passwd(5) 和 shadow(5)。
- 物理范围
一个术语,用于描述使用逻辑卷管理器时物理卷被分解成的块。
- 物理卷
一个术语,用于描述实际的磁盘分区,通常是指逻辑卷管理器。
- 盘片
硬盘驱动器内的物理磁盘。 通常,硬盘驱动器由堆叠在一起的多个物理磁盘组成。 一个单独的磁盘称为盘片。
- 开机自检
(POST) 计算机开机时运行的一系列诊断测试。 通常,这可能包括测试内存、测试硬件配置与上次保存的配置是否相同、检查 BIOS 已知的任何软盘驱动器或硬盘驱动器是否已安装并正常工作。
- 打印队列
打印守护进程使用的文件(或一组文件),以便希望使用打印机的应用程序不必等到它们发送的打印作业完成后才能继续。 它还允许多个用户共享一台打印机。
- 读写磁头
一种微小的电磁线圈和金属杆,用于在磁盘上写入和读取磁性图案。 这些线圈相对于盘片上的旋转运动横向移动。
- 根文件系统
在 Unix 文件系统树中挂载的所有其他文件系统的父级。 作为 / 挂载,它可能挂载有其他文件系统(例如 /usr)。 如果无法挂载根文件系统,则内核将崩溃,并且系统将无法继续启动
- 运行级别
Linux 最多有 10 个可用的运行级别 (0-9)(其中通常只定义了前 7 个)。 每个运行级别可能会启动一组不同的服务,从而在同一系统中提供多个不同的配置。 运行级别 0 定义为“系统停止”,运行级别 1 定义为“单用户模式”,运行级别 6 定义为“重启系统”。 其余的运行级别理论上可以由系统管理员以任何方式定义。 但是,大多数发行版都提供了一些其他预定义的运行级别。 例如,运行级别 2 可能定义为“多用户控制台”,运行级别 5 定义为“多用户 X-Window 系统”。 这些定义在不同的发行版之间差异很大,因此请检查您自己的发行版的文档。
- 扇区
可以分配用于存储数据的最小磁道长度。 这通常(但并非总是)是 512 字节。
- 影子密码
因为 Unix 系统上的密码文件通常需要世界可读,所以它通常实际上不包含用户帐户的加密密码。 而是使用影子文件(不是世界可读),它保存用户帐户的加密密码。
- 单用户模式
通常是运行级别 1。 一个运行级别,除了 root 帐户外,不允许登录。 用于系统修复(如果文件系统部分损坏,可能仍然可以启动到运行级别 1 并对其进行修复),或者用于在分区之间移动文件系统。 这只是两个例子。 任何需要一次只能一个人写入磁盘的系统的任务都可能需要运行级别 1。
- 假脱机
将文件(或其他数据)发送到队列。 通常与打印机结合使用,但也可能用于其他事物(例如邮件)。 据报道,该术语是“Simultaneous Peripheral Operation On-Line”的缩写,但根据 Jargon File 的说法,它可能是一个后缩写(稍后为效果而创建的东西)。
- 系统调用
内核向应用程序提供的服务,以及调用它们的方式。 请参阅手册页的第 2 节。
- 交换空间
系统可以在其中写入部分内存的磁盘上的空间。 通常这是一个专用分区,但它也可能是一个交换文件。
- 系统程序
实现操作系统高级功能的程序,即,不直接依赖于硬件的东西。 有时可能需要特殊权限才能运行(例如,用于传递电子邮件),但通常只被认为是系统的一部分(例如,编译器)。 另请参阅应用程序、内核、操作系统。
- 时间漂移
这是计算机在跟踪时间方面的准确性的术语。 所有计算机在保持时间方面都存在一定的误差率。 对于较新的计算机,此误差率非常小。
- 磁道
当磁头静止但磁盘旋转时,在读写磁头下通过的磁盘盘片的部分。 每个磁道被划分为扇区,并且垂直的磁道集合是一个柱面。
- 卷组
一组物理卷,分解为物理范围,可用于逻辑分区。
索引-草稿
A
- at , 定期命令执行:cron 和 at
C
- CMOS, 硬盘
- 命令
- badblocks, 格式化
- cfdisk, 硬盘分区
- chsh, /etc 目录
- depmod, depmod
- df, /etc 目录
- fdformat, 格式化
- fdisk, MBR、引导扇区和分区表, 分区类型, 硬盘分区
- file, /etc 目录
- fips, 硬盘分区
- free, /proc 文件系统
- fsck, 格式化
- ftpd, /etc 目录
- getty, init, /etc 目录
- gzexe, 节省磁盘空间的提示
- gzip, 节省磁盘空间的提示
- hdparm, hdparm 命令
- init, init
- insmod, insmod
- login, /etc 目录, /var 文件系统
- losetup, /dev 目录
- lpr, 两种设备
- ls, 两种设备
- lsdev, lsdev 命令
- lsmod, lsmod
- lspci, lspci 命令
- lsraid, lsraid 命令
- lsusb, lsusb 命令
- MAKEDEV, /dev 目录, MAKEDEV 脚本, mknod 命令
- man, /var 文件系统
- mkfs, 格式化
- mknod, mknod 命令
- modprobe, modprobe
- mount, /etc 目录, /dev 目录
- parted, 硬盘分区
- rmmod, rmmod
- setfdparm, 软盘
- setfdprm, /etc 目录, 格式化
- su, /etc 目录
- sudo, /etc 目录
- swapon, /etc 目录
- syslog, /var 文件系统, 格式化
- zip, 节省磁盘空间的技巧
- Common Internet File System (CIFS), 网络文件系统, 网络附加存储 - 草案, CIFS
- cron, 定期命令执行:cron 和 at
- crontab , 定期命令执行:cron 和 at
F
- 光纤通道, 存储区域网络 - 草案
- 文件系统, 文件系统布局, /usr 文件系统
- / (根目录), 背景, 根文件系统
- /bin, 文件系统布局, 根文件系统
- /boot, 根文件系统
- /dev, 文件系统布局, 根文件系统, /dev 目录, 两种类型的设备
- /dev/dsp, /dev 目录
- /dev/fb0, /dev 目录
- /dev/fd0, /dev 目录, 软盘, 格式化
- /dev/fd1, 软盘
- /dev/hda, /dev 目录, 硬盘
- /dev/hdb, /dev 目录, 硬盘
- /dev/hdc, /dev 目录, 硬盘
- /dev/hdc9, /dev 目录
- /dev/hdd, /dev 目录, 硬盘
- /dev/ht0, /dev 目录
- /dev/js0, /dev 目录
- /dev/loop0, /dev 目录
- /dev/lp0, /dev 目录
- /dev/md0, /dev 目录
- /dev/mixer, /dev 目录
- /dev/null, /dev 目录
- /dev/parport0, /dev 目录
- /dev/pcd0, /dev 目录
- /dev/pda, /dev 目录
- /dev/pdb, /dev 目录
- /dev/pdc, /dev 目录
- /dev/pdd, /dev 目录
- /dev/psaux, /dev 目录
- /dev/pt0, /dev 目录
- /dev/pt1, /dev 目录
- /dev/random, /dev 目录
- /dev/sda, /dev 目录, 两种类型的设备, 硬盘
- /dev/sdb, /dev 目录, 硬盘
- /dev/sdd, /dev 目录
- /dev/ttyS0, /dev 目录, MAKEDEV 脚本, mknod 命令
- /dev/urandom, /dev 目录
- /dev/zero, /dev 目录
- /etc, 文件系统布局, 根文件系统, /etc 目录
- /etc/bash.rc, /etc 目录
- /etc/csh.cshrc, /etc 目录
- /etc/fdprm, /etc 目录, 软盘
- /etc/fstab, /etc 目录
- /etc/group, /etc 目录
- /etc/inittab, /etc 目录
- /etc/issue, /etc 目录
- /etc/login.defs, /etc 目录
- /etc/magic, /etc 目录
- /etc/motd, /etc 目录
- /etc/mtab, /etc 目录
- /etc/passwd, /etc 目录
- /etc/printcap, /etc 目录
- /etc/profile, /etc 目录
- /etc/rc.d, /etc 目录
- /etc/securetty, /etc 目录
- /etc/shadow, /etc 目录
- /etc/shells, /etc 目录
- /etc/termcap, /etc 目录
- /home, 文件系统布局, 背景, 根文件系统
- /lib, 文件系统布局, 根文件系统
- /lib/modules, 根文件系统
- /mnt, 根文件系统
- /proc, 根文件系统, /proc 文件系统, 多种多样的文件系统
- /proc/1, /proc 文件系统
- /proc/cpuinfo, /proc 文件系统
- /proc/devices, /proc 文件系统
- /proc/dma, /proc 文件系统
- /proc/filesystems, /proc 文件系统
- /proc/interrupts, /proc 文件系统
- /proc/ioports, /proc 文件系统
- /proc/kcore, /proc 文件系统, 多种多样的文件系统
- /proc/kmsg, /proc 文件系统
- /proc/ksyms, /proc 文件系统
- /proc/loadavg, /proc 文件系统
- /proc/meminfo, /proc 文件系统
- /proc/modules, /proc 文件系统
- /proc/net, /proc 文件系统
- /proc/self, /proc 文件系统
- /proc/stat, /proc 文件系统
- /proc/uptime, /proc 文件系统
- /proc/version, /proc 文件系统
- /root, 根文件系统
- /sbin, 根文件系统
- /tmp, 根文件系统, /var 文件系统
- /usr, 文件系统布局, 背景, 根文件系统
- /var, 文件系统布局, 背景, 根文件系统, /var 文件系统
- /var/cache/man, /var 文件系统
- /var/games, /var 文件系统
- /var/lib, /var 文件系统
- /var/local, /var 文件系统
- /var/lock, /var 文件系统
- /var/log, /var 文件系统
- /var/log/messages, /var 文件系统
- /var/log/wtmp, /var 文件系统
- /var/mail, /var 文件系统
- /var/run, /var 文件系统
- /var/spool, /var 文件系统
- /var/spool/mail, /var 文件系统
- /var/spool/news, /var 文件系统
- /var/tmp, /var 文件系统
- /var/utmp, /var 文件系统
- Filesystem Hierarchy Standard (FHS) , 文件系统布局, 目录树概览, 背景
- 文件系统类型
- ext, 多种多样的文件系统
- ext2, 多种多样的文件系统, 文件系统比较
- ext3, 多种多样的文件系统, 文件系统比较
- fat16, 文件系统比较
- fat32, 文件系统比较
- hfs+, 文件系统比较
- hpfs, 多种多样的文件系统, 文件系统比较
- iso9660, 多种多样的文件系统
- jfs, 多种多样的文件系统, 文件系统比较
- minix, 多种多样的文件系统
- msdos, 多种多样的文件系统
- nfs, 多种多样的文件系统
- ntfs, 多种多样的文件系统, 文件系统比较
- reiserfs, 多种多样的文件系统, 文件系统比较
- smbfs, 多种多样的文件系统
- sysv, 文件系统大全
- ufs2, 文件系统比较
- umsdos, 文件系统大全
- vfat, 文件系统大全
- vxfs, 文件系统比较
- xfs, 文件系统大全
- xia, 文件系统大全
- zfs, 文件系统比较
- 文件系统
- /etc
- /etc/fstab, 为Linux增加磁盘空间
- 自由软件基金会, Linux 还是 GNU/Linux,问题就在这里。
S
- Samba , 网络文件系统, 网络附加存储 - 草案, CIFS
- Shell
- ssh, 网络登录
- 存储区域网络 (SAN), 存储区域网络 - 草案, 网络附加存储 - 草案
- LUN, 存储区域网络 - 草案
- syslog , Syslog