
图 1:alloc_skb 之后
经Linux Journal许可转载,摘自 1996 年 9 月第 29 期。为适应网络环境,进行了一些修改。本文最初是为 Kernel Korner 专栏撰写的。Kernel Korner 系列也收录了许多其他对 Linux 内核黑客感兴趣的文章。
Linux 操作系统实现了行业标准的 Berkeley 套接字 API,该 API 起源于 BSD unix 开发(4.2/4.3/4.4 BSD)。在本文中,我们将研究现有 Linux 内核下网络层和网络设备驱动程序中内存管理和缓冲的实现方式,并解释某些事情随时间推移发生变化的原因和方式。
网络层在其设计中力求相当面向对象,正如 Linux 内核的大部分内容一样。网络代码的核心结构可以追溯到 Ross Biro 和 Orest Zborowski 分别进行的初始网络和套接字实现。关键对象是
的主要目标sk_buff例程是为所有网络层提供一致且高效的缓冲区处理方法,并通过保持一致性,使为所有协议提供更高级别的sk_buff和套接字处理功能成为可能。
一个sk_buff是一个带有附加内存块的控制结构。在sk_buff库中提供了两组主要函数。首先是操作sk_buffs双向链表的例程,其次是控制附加内存的函数。缓冲区保存在链表上,这些链表针对常见的网络操作(追加到末尾和从开头删除)进行了优化。由于如此多的网络功能发生在中断期间,因此这些例程被编写为原子的。这造成的小额外开销完全值得它在错误查找方面节省的痛苦。
我们使用列表操作来管理从网络到达的数据包组,以及我们将它们发送到物理接口的数据包组。我们使用内存操作例程以标准化且高效的方式处理数据包的内容。
在其最基本的层面上,缓冲区列表是使用如下函数管理的
void append_frame(char *buf, int len)
{
struct sk_buff *skb=alloc_skb(len, GFP_ATOMIC);
if(skb==NULL)
my_dropped++;
else
{
skb_put(skb,len);
memcpy(skb->data,data,len);
skb_append(&my_list, skb);
}
}
void process_queue(void)
{
struct sk_buff *skb;
while((skb=skb_dequeue(&my_list))!=NULL)
{
process_data(skb);
kfree_skb(skb, FREE_READ);
}
}
这两段相当简单的代码实际上非常准确地演示了接收数据包机制。append_frame()函数类似于设备驱动程序在接收数据包时从中断调用的代码,而process_frame()函数类似于调用以将数据馈送到协议的代码。如果您查看 net/core/dev.c 中的netif_rx()和net_bh(),您会看到它们以类似的方式管理缓冲区。它们要复杂得多,因为它们必须将数据包馈送到正确的协议并管理流量控制,但基本操作是相同的。如果您查看从协议代码到用户应用程序的缓冲区,情况也是如此。该示例还展示了数据控制函数之一skb_put()的用法。在这里,它用于在缓冲区中为我们希望向下传递的数据保留空间。
让我们看一下append_frame()。的alloc_skb()函数获取len字节的缓冲区(图 1),它由以下部分组成:
在缓冲区分配后立即,所有可用空间都在末尾。另一个名为skb_reserve()的函数(图 2)可以在添加数据之前调用,允许您指定部分空间应位于开头。因此,许多发送例程都以类似如下代码开头:
skb=alloc_skb(len+headspace, GFP_KERNEL);
skb_reserve(skb, headspace);
skb_put(skb,len);
memcpy_fromfs(skb->data,data,len);
pass_to_m_protocol(skb);
在 BSD unix 等系统中,您无需提前知道您需要多少空间,因为它使用小缓冲区 (mbufs) 链作为其网络缓冲区。Linux 选择使用线性缓冲区并提前节省空间(通常浪费少量字节以允许最坏的情况),因为线性缓冲区使许多其他事情变得更快。
现在回到列表函数。Linux 提供了以下操作



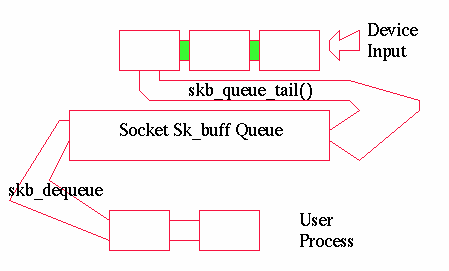
为套接字分配和排队缓冲区的语义还涉及流量控制规则,以及用于发送整个列表的信号交互和可选设置,例如非阻塞。设计了两个例程,使大多数协议都能轻松实现这一点。
的sock_queue_rcv_skb()函数用于处理传入数据流控制,通常以
sk=my_find_socket(whatever);
if(sock_queue_rcv_skb(sk,skb)==-1)
{
myproto_stats.dropped++;
kfree_skb(skb,FREE_READ);
return;
}
此函数使用套接字读取队列计数器来防止大量数据排队到套接字。达到限制后,数据将被丢弃。应用程序需要足够快地读取,或者像 TCP 中那样,协议需要在网络上进行流量控制。TCP 实际上会在无法再对数据进行排队时告诉发送机器闭嘴。在发送端,sock_alloc_send_skb()处理信号处理、非阻塞标志以及阻塞的语义,直到发送队列中有空间,这样您就不会用为慢速接口排队的数据占用所有内存。许多协议发送例程都使用此函数完成几乎所有工作
skb=sock_alloc_send_skb(sk,....)
if(skb==NULL)
return -err;
skb->sk=sk;
skb_reserve(skb, headroom);
skb_put(skb,len);
memcpy(skb->data, data, len);
protocol_do_something(skb);
我们之前已经遇到过其中的大部分内容。非常重要的一行是skb->sk=sk。的sock_alloc_send_skb()已将缓冲区的内存计入套接字。通过设置skb->sk,我们告诉内核,任何人在缓冲区上执行kfree_skb()都应使套接字获得缓冲区的内存信用。因此,当设备发送缓冲区并释放它时,用户将能够发送更多数据。
所有 Linux 网络设备都遵循相同的接口,尽管并非所有设备都需要该接口中提供的许多功能。使用了面向对象的思想,每个设备都是一个对象,其中一系列方法被填充到结构中。每个方法都以设备本身作为第一个参数调用。这样做是为了绕过 C 语言中缺少 C++ 的this概念的问题。
文件 drivers/net/skeleton.c 包含网络设备驱动程序的骨架。从最近的内核查看或打印副本,并在本文的其余部分中跟随学习。
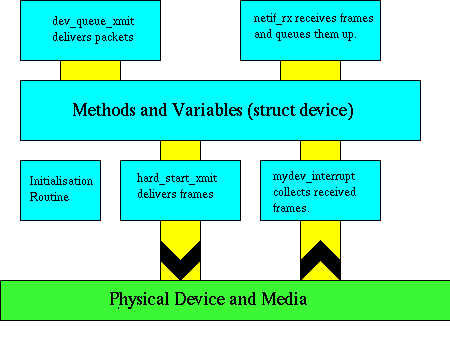
每个网络设备都完全处理从协议到物理介质的网络缓冲区传输,以及接收和解码硬件生成的响应。传入帧被转换为网络缓冲区,由协议标识并传递给netif_rx()。然后,此函数将帧传递到协议层以进行进一步处理。
每个设备都提供一组附加方法,用于处理数据包的停止、启动、控制和物理封装。这些方法和所有其他控制信息都收集在用于管理每个设备的设备结构中。
所有 Linux 网络设备都有唯一的名称。这与设备可能具有的文件系统名称没有任何关系,实际上网络设备通常没有文件系统表示,尽管您可以创建绑定到设备驱动程序的设备。传统上,名称仅指示设备的类型,而不是其制造商。同一类型的多个设备从 0 开始向上编号。因此,以太网设备被称为“eth0”、“eth1”、“eth2”等。命名方案很重要,因为它允许用户以“以太网卡”的形式编写程序或系统配置,而无需担心电路板的制造商,并在更换电路板时强制重新配置。
以下名称当前用于通用设备
如果可能,新设备应选择反映现有实践的名称。当您添加全新的物理层类型时,您应该寻找其他从事此类项目的人员,并使用通用的命名方案。
某些物理层在一个介质上呈现多个逻辑接口。ATM 和帧中继都具有此属性,业余无线电环境中的多点 KISS 也是如此。在这种情况下,每个活动通道都需要一个驱动程序。Linux 网络代码的结构使其可以在没有过多额外代码的情况下管理此问题,并且名称注册方案允许您在通道进入和退出存在状态时几乎随意创建和删除接口。此类名称的拟议约定仍在讨论中,因为“sl0a”、“sl0b”、“sl0c”等简单方案适用于多点 KISS 等基本设备,但不适用于虚拟通道可能跨物理板移动的多个帧中继连接。
每个设备都是通过填写struct device对象并将其传递给register_netdev(struct device *)调用来创建的。这会将您的设备结构链接到内核网络设备表中。由于您传入的结构由内核使用,因此在您使用void unregister_netdev(struct device *)调用卸载设备之前,您不得释放此结构。这些调用通常在启动时或模块加载和卸载时完成。
如果您创建多个具有相同名称的设备,内核不会反对,但会崩溃。因此,如果您的驱动程序是可加载模块,则应使用struct device *dev_get(const char *name)调用以确保该名称尚未使用。如果正在使用,则应失败或选择另一个名称。如果您发现冲突,则不得使用unregister_netdev()来注销具有该名称的其他设备!
典型的注册代码序列如下所示
int register_my_device(void)
{
int i=0;
for(i=0;i<100;i++)
{
sprintf(mydevice.name,"mydev%d",i);
if(dev_get(mydevice.name)==NULL)
{
if(register_netdev(&mydevice)!=0)
return -EIO;
return 0;
}
}
printk("100 mydevs loaded. Unable to load more.\n");
return -ENFILE;
}
每个网络设备的所有通用信息和方法都保存在设备结构中。要创建设备,您需要填写其中的大部分内容。本节介绍应如何设置它们。
下一组参数用于维护设备在体系结构的设备地址空间中的位置。irq字段保存设备正在使用的中断 (IRQ)。这通常在启动时或由初始化函数设置。如果未使用中断、当前未知或未分配,则应使用值零。可以通过多种方式设置中断。内核的 auto-irq 功能可用于探测设备中断,或者可以在加载网络模块时设置中断。网络驱动程序通常使用名为irq的全局 int,以便用户可以使用insmod mydevice irq=5样式命令加载模块。最后,IRQ 可以从 ifconfig 命令动态设置。这将导致调用您的设备,稍后将对此进行讨论。
的base_addr字段是设备所在的基 I/O 空间地址。如果设备不使用 I/O 位置,或者在没有 I/O 空间概念的系统上运行,则此字段应为零。当此字段可由用户设置时,通常由名为io的全局变量设置。接口 I/O 地址也可以使用 ifconfig 设置。
为 ISA 总线共享内存以太网卡等设备定义了两个硬件共享内存范围。对于当前目的,rmem_start和rmem_end字段已过时,应加载为 0。mem_start和mem_end地址应加载为此设备使用的共享内存块的起始和结束地址。如果未使用共享内存块,则应存储值 0。允许用户指定此参数的设备使用名为mem的全局变量来设置内存基地址,并自行设置mem_end。
的dma变量保存设备正在使用的 DMA 通道。Linux 允许自动探测 DMA(如中断)。如果未使用 DMA 通道,或者 DMA 通道尚未设置,则使用值 0。这可能必须更改,因为最新的 PC 板允许硬件板使用 ISA 总线 DMA 通道 0,而不仅仅将其绑定到内存刷新。如果用户可以设置 DMA 通道,则使用全局变量dma。
重要的是要认识到,物理信息是为控制和用户查看(以及驱动程序的内部函数)提供的,并且不会注册这些区域以防止它们被重用。因此,设备驱动程序还必须分配和注册它希望使用的 I/O、DMA 和中断线,使用与任何其他设备驱动程序相同的内核函数。[请参阅近期 Kernel Korner 系列文章,关于在 Linux Journal 第 23、24、25、26 和 28 期中编写字符设备驱动程序。]
的if_port字段保存多媒体设备的物理介质类型,例如组合以太网板。
为了使网络协议层以合理的方式执行,设备必须提供一组功能标志和变量。这些也保存在设备结构中。
的mtu是可以通过此接口发送的最大有效负载(即,不包括设备本身将提供的任何底层标头的最大数据包大小)。协议层(如 IP)使用它来选择合适的要发送的数据包大小。每种协议都有最低要求。没有 576 字节或更大的帧大小,设备无法用于 IPX。IP 至少需要 72 字节,并且在低于约 200 字节的情况下无法合理地执行。是否与您的设备合作由协议层决定。
的family始终设置为AF_INET,并指示设备正在使用的协议族。Linux 允许设备同时使用多个协议族,并维护此信息仅是为了看起来更像标准的 BSD 网络 API。
接口硬件类型 (type) 字段取自物理介质类型表。ARP 协议使用的值(请参阅 RFC1700)用于那些支持 ARP 的介质,并且为其他物理层分配了其他值。当需要时,新值会添加到内核和 net-tools 中,net-tools 是包含 ifconfig 等程序的软件包,这些程序需要能够解码此字段。截至 Linux pre2.0.5 定义的字段是
来自 RFC1700
那些标记为未使用的接口是已定义的类型,但在现有的 net-tools 上没有任何当前支持。Linux 内核为使用以太网和令牌环的设备提供了额外的通用支持例程。
的pa_addr字段用于在接口启动时保存 IP 地址。接口应在关闭状态下启动,此变量应清除。pa_brdaddr用于保存配置的广播地址,pa_dstaddr点对点链路的目标和pa_mask接口的 IP 网络掩码。所有这些都可以初始化为零。pa_alen字段保存地址的长度(在我们的例子中是 IP 地址),应将其初始化为 4。
的hard_header_len是设备在其传递的网络缓冲区的开头所需的字节数。它不必是将被添加的物理标头的字节数,尽管这很正常。设备可以使用它在每个缓冲区的开头为自己提供一个暂存区。
在 1.2.x 系列内核中,skb->data指针将指向缓冲区的开头,您必须避免自己发送暂存区。这也意味着对于具有可变长度标头的设备,您将需要分配max_size+1字节,并在开头保留一个长度字节,以便您知道标头真正开始的位置(标头应与数据连续)。Linux 1.3.x 使生活变得更加简单,并确保您在缓冲区开头至少有您要求的那么多可用空间。由您来适当使用skb_push(),正如在网络缓冲区部分讨论的那样。
物理介质地址(如果有)分别保存在dev_addr和broadcast中。这些是字节数组,小于数组大小的地址从左侧开始存储。addr_len字段用于保存硬件地址的长度。对于许多介质,没有硬件地址,应将其设置为零。对于其他一些接口,地址必须由用户程序设置。ifconfig 工具允许设置接口硬件地址。在这种情况下,最初不需要设置它,但打开代码应注意不要允许设备在未设置地址的情况下开始传输。
一组标志用于维护接口属性。其中一些是“兼容性”项,因此没有直接用处。标志是
数据包由内核协议代码为接口排队。在每个设备中,buffs[]是每个内核优先级级别的数据包队列数组。这些完全由内核代码维护,但必须由设备本身在启动时初始化。使用的初始化代码是
int ct=0;
while(ct<DEV_NUMBUFFS)
{
skb_queue_head_init(&dev->buffs[ct]);
ct++;
}
所有其他字段都应初始化为 0。设备可以通过设置字段dev->tx_queue_len来选择它想要的队列长度,即内核应为设备排队的最大帧数。对于以太网,这通常约为 100,对于串行线路,这通常约为 10。设备可以动态修改此值,尽管其效果会略微滞后于更改。
每个网络设备都必须提供一组实际函数(方法)用于基本低级操作。它还应提供一组支持函数,将协议层与它提供的链路层协议要求连接起来。
init 方法在设备初始化并向系统注册时调用。它应执行任何需要的低级验证和检查,如果设备不存在、区域无法注册或无法继续,则返回错误代码。如果 init 方法返回错误,则register_netdev()调用返回错误代码,并且不创建设备。
所有设备都必须提供传输功能。可能存在无法传输的设备。在这种情况下,设备需要一个传输函数,该函数仅释放传递给它的缓冲区。虚拟设备在传输时正好具有此功能。
的dev->hard_start_xmit()函数被调用,并为驱动程序提供其自己的设备指针和网络缓冲区(一个sk_buff)以进行传输。如果您的设备无法接受缓冲区,则应返回 1 并将dev->tbusy设置为非零值。这将对缓冲区进行排队,并且稍后可能会再次重试,尽管不能保证会重试缓冲区。如果协议层决定释放驱动程序拒绝的缓冲区,则不会将其提供回设备。如果设备知道缓冲区在不久的将来无法传输,例如由于不良拥塞,它可以调用dev_kfree_skb()来转储缓冲区并返回 0,指示缓冲区已处理。
如果有空间,则应处理缓冲区。向下传递的缓冲区已经包含所有标头,包括必要的链路层标头,并且只需要实际加载到硬件中进行传输即可。此外,缓冲区已锁定。这意味着设备驱动程序拥有缓冲区的绝对所有权,直到它选择放弃它为止。sk_buff的内容保持只读,除非您保证 next/previous 指针是空闲的,因此您可以使用sk_buff列表原语来构建缓冲区的内部链。
当缓冲区已加载到硬件中时,或者在某些 DMA 驱动的设备的情况下,当硬件指示传输完成时,驱动程序必须释放缓冲区。这是通过调用dev_kfree_skb(skb, FREE_WRITE)来完成的。一旦发出此调用,有问题的sk_buff可能会自发消失,因此设备驱动程序不应再次引用它。
高级协议有必要在将每个帧排队以进行传输之前,将低级标头附加到每个帧。协议显然也不希望提前知道如何为所有可能的帧类型附加低级标头。因此,协议层向下调用设备,并提供一个缓冲区,该缓冲区在缓冲区开头至少有dev->hard_header_len字节的可用空间。然后,由网络设备正确调用skb_push()并将标头放在其dev->hard_header()方法中。没有链路层标头的设备(例如 SLIP)可以将此方法指定为 NULL。
调用该方法时,会给出相关的缓冲区、设备自身的指针、其协议标识、指向源硬件地址和目标硬件地址的指针以及要发送的数据包的长度。由于该例程可能在协议层完全组装之前被调用,因此该方法必须使用长度参数,而不是缓冲区长度,这一点至关重要。
源地址可能为 NULL,表示“使用此设备的默认地址”,目标地址可能为 NULL,表示“未知”。如果由于未知目标而无法完成标头,则应分配空间,并应填充任何可以填充的字节。此功能目前仅由 IP 在必须进行 ARP 处理时使用。然后,该函数必须返回添加的标头字节数的负数。如果标头已完全构建,则必须返回添加的标头字节数。
当标头无法完成时,协议层将尝试解析必要的地址。发生这种情况时,dev->rebuild_header()调用 method 时需要提供头文件所在的地址、相关设备、目标 IP 地址和网络缓冲区指针。如果设备能够通过任何可用方式(通常是 ARP)解析地址,则会填充物理地址并返回 1。如果无法解析头文件,则返回 0,并且缓冲区将在协议层有理由相信可以解析时重试。
网络设备中没有接收方法,因为是由设备调用此类事件的处理。对于典型的设备,中断会通知处理程序已完成的数据包已准备好接收。设备使用以下命令分配适当大小的缓冲区:dev_alloc_skb()并将硬件中的字节放入缓冲区。接下来,设备驱动程序分析帧以确定数据包类型。驱动程序设置skb->dev为接收帧的设备。它设置skb->protocol为帧代表的协议,以便可以将帧传递到正确的协议层。链路层头指针存储在skb->mac.raw中,并使用以下命令删除链路层头:skb_pull()以便协议无需了解它。最后,为了保持链路和协议的隔离,设备驱动程序必须设置skb->pkt_type为以下其中之一
最后,设备驱动程序调用netif_rx()以将缓冲区传递给协议层。缓冲区排队等待网络协议在中断处理程序返回后进行处理。以这种方式延迟处理可以显着减少禁用中断的时间,并提高整体响应能力。一旦netif_rx()被调用,缓冲区将不再是设备驱动程序的属性,并且不得再次更改或引用。
协议在两个级别上应用接收数据包的流控制。首先,可能存在要处理的最大数据量netif_rx()。其次,系统上的每个套接字都有一个队列,用于限制待处理数据的数量。因此,所有流控制都由协议层应用。在传输端,每个设备变量dev->tx_queue_len用作队列长度限制器。队列的大小通常为 100 帧,这足以在通过快速链路发送大量数据时保持队列充满。在慢速链路(如 SLIP 链路)上,队列通常设置为大约 10 帧,因为即使发送 10 帧也是几秒钟的排队数据。
对于大多数现有设备的接收而言,以及如果可能的话您应该实现的一项神奇之处是在缓冲区头部保留必要的字节,以便将 IP 头部放置在长字边界上。因此,现有的以太网驱动程序会执行
skb=dev_alloc_skb(length+2);
if(skb==NULL)
return;
skb_reserve(skb,2);
/* then 14 bytes of ethernet hardware header */
以将 IP 头部对齐到 16 字节边界,这也是缓存行的开始,有助于提高性能。在 Sparc 或 DEC Alpha 上,这些改进非常明显。每个设备都可以选择向协议层提供额外的功能和设施。不实现这些功能会导致通过接口提供的服务降级,但不会阻止操作。这些操作分为两类——配置和激活/关闭。
当设备被激活时(即标志IFF_UP被设置),如果设备提供了dev->open()方法,则会调用该方法。这允许设备执行任何操作,例如启用接口,这些操作是在要使用接口时需要的。从此函数返回错误会导致设备保持关闭状态,并导致用户激活设备的请求失败,并返回dev->open()
返回的错误。此函数的第二个用途是用于作为模块加载的任何设备。这里有必要防止设备在打开时被卸载。因此,必须在 open 方法中使用MOD_INC_USE_COUNT宏。
的dev->close()方法在设备配置为关闭时调用,应以最小化机器负载的方式关闭硬件(例如,通过禁用接口或其生成中断的能力)。它也可以用于允许模块设备在关闭后被卸载。内核的其余部分以这样一种方式构建,即当设备关闭时,所有通过指针对其的引用都会被删除。这确保了设备可以从运行的系统中安全卸载。不允许 close 方法失败。
一组函数提供了查询和设置操作参数的能力。其中第一个也是最基本的是get_stats例程,当调用时,它会返回接口的 structenet_statistics块。这允许用户程序(如 ifconfig)查看接口上的负载以及记录的任何问题帧。不提供此功能将导致没有可用的统计信息。
的dev->set_mac_address()函数在超级用户进程发出类型为SIOCSIFHWADDR的 ioctl 以更改设备的物理地址时调用。对于许多设备,这没有意义,对于其他设备则不支持。如果是这样,请将此函数指针保留为NULL。某些设备只有在接口关闭时才能执行物理地址更改。对于这些设备,请检查IFF_UP,如果设置,则返回-EBUSY.
的dev->set_config()函数由SIOCSIFMAP函数在用户输入类似ifconfig eth0 irq 11的命令时调用。它传递一个ifmap结构,其中包含所需的 I/O 和其他接口参数。对于大多数接口,这没有用,您可以返回 NULL。
最后,每当在dev->do_ioctl()范围内调用 ioctl 时,就会调用SIOCDEVPRIVATE到SIOCDEVPRIVATE+15在您的接口上使用。所有这些 ioctl 调用都接受一个 structifreq。这会在您的处理程序被调用之前复制到内核空间,并在结束时复制回来。为了最大的灵活性,任何用户都可以进行这些调用,并且由您的代码在适当时检查超级用户状态。例如,PLIP 驱动程序使用这些来设置并行端口超时速度,以允许用户为他们的机器调整 plip 设备。
某些物理介质类型(如以太网)在物理层支持多播帧。多播帧由网络上的一个组(但不是所有主机)听到,而不是从一个主机到另一个主机。
以太网卡的功能相当多样。大多数分为以下三类之一
内核支持代码维护您的接口应允许用于多播的物理地址列表。如果设备无法进行完美过滤,则设备驱动程序可能会返回与请求的多播列表匹配更多的帧。
每当多播地址列表更改时,设备驱动程序dev->set_multicast_list()函数被调用。然后,驱动程序可以重新加载其物理表。通常看起来像这样
if(dev->flags&IFF_PROMISC)
SetToHearAllPackets();
else if(dev->flags&IFF_ALLMULTI)
SetToHearAllMulticasts();
else
{
if(dev->mc_count<16)
{
LoadAddressList(dev->mc_list);
SetToHearList();
}
else
SetToHearAllMulticasts();
}
少数网卡只能进行单播或混杂模式。在这种情况下,当收到多播请求时,驱动程序必须进入混杂模式。如果这样做,驱动程序本身还必须设置IFF_PROMISC标志在dev->flags.
为了帮助驱动程序编写者,多播列表始终保持有效。这简化了许多驱动程序,因为驱动程序中错误条件导致的重置通常必须重新加载多播地址列表。
以太网可能是最常见的物理接口类型。内核提供了一组通用以太网支持例程,此类驱动程序可以使用。
eth_header()是dev->hard_header例程的标准以太网处理程序,可用于任何以太网驱动程序。与eth_rebuild_header()用于重建例程,它提供了将以太网头放在 IP 数据包上所需的所有 ARP 查找。
的eth_type_trans()例程期望被馈送原始以太网数据包。它分析头文件并设置skb->pkt_type和skb->mac本身,并返回skb->protocol的建议值。此例程通常从以太网驱动程序接收中断处理程序调用,以对数据包进行分类。
eth_copy_and_sum(),最终的以太网支持例程,在内部非常复杂,但为内存映射卡提供了显着的性能改进。它提供了将卡中的数据复制和校验和到sk_buff中的单次传递支持。当使用时,这种单次通过内存几乎消除了校验和计算的成本,并且可以真正帮助提高 IP 吞吐量。
自从 0.95 版本以来,Alan Cox 一直在从事 Linux 工作,当时他安装 Linux 是为了进一步开发 AberMUD 游戏。他现在管理 Linux 网络、SMP 和 Linux/8086 项目,自 1993 年 11 月以来就再也没有在 AberMUD 上工作过。