Linux 是一种类似 Unix 的操作系统,运行在 PC-386 计算机上。它最初是作为 Minix 操作系统的扩展 [Tanenbaum 1987] 实现的,并且其最初的版本仅包含对 Minix 文件系统的支持。 Minix 文件系统包含两个严重的限制:块地址存储在 16 位整数中,因此最大文件系统大小被限制为 64 兆字节,并且目录包含固定大小的条目,最大文件名长度为 14 个字符。
我们设计并实现了两个新的文件系统,它们包含在标准的 Linux 内核中。这些文件系统被称为“扩展文件系统”(Ext fs)和“第二扩展文件系统”(Ext2 fs),提高了限制并添加了新功能。
在本文中,我们将描述 Linux 文件系统的历史。 我们简要介绍了 Unix 文件系统中实现的基本概念。 我们介绍了 Linux 中虚拟文件系统层的实现,并详细介绍了第二扩展文件系统的内核代码和用户模式工具。 最后,我们介绍了在 Linux 和 BSD 文件系统上进行的性能测量,并以 Ext2fs 的当前状态和未来的方向作为结论。
在其早期,Linux 是在 Minix 操作系统下交叉开发的。 在两个系统之间共享磁盘比设计新的文件系统更容易,因此 Linus Torvalds 决定在 Linux 中实现对 Minix 文件系统的支持。 Minix 文件系统是一个高效且相对无错误的软件。
但是,Minix 文件系统设计中的限制太多,因此人们开始思考和研究在 Linux 中实现新的文件系统。
为了简化将新文件系统添加到 Linux 内核的过程,开发了一个虚拟文件系统(VFS)层。 VFS 层最初由 Chris Provenzano 编写,后来由 Linus Torvalds 重写,然后集成到 Linux 内核中。 详见 虚拟文件系统。
在将 VFS 集成到内核后,一个新的文件系统,称为“扩展文件系统”,于 1992 年 4 月实现并添加到 Linux 0.96c 中。 这个新的文件系统消除了 Minix 的两个重大限制:其最大大小为 2 GB,最大文件名大小为 255 个字符。 它是对 Minix 文件系统的改进,但仍然存在一些问题。 没有对单独的访问、inode 修改和数据修改时间戳的支持。 该文件系统使用链表来跟踪空闲块和 inode,这导致了不良的性能:随着文件系统的使用,列表变得无序,文件系统变得碎片化。
为了响应这些问题,两个新的文件系统于 1993 年 1 月发布了 Alpha 版本:Xia 文件系统和第二扩展文件系统。 Xia 文件系统主要基于 Minix 文件系统的内核代码,并且仅在此文件系统上添加了一些改进。 基本上,它提供了长文件名、对更大分区和对三个时间戳的支持。 另一方面,Ext2fs 基于 Extfs 代码,进行了许多重组和许多改进。 它的设计考虑了演变,并包含未来改进的空间。 将在 第二扩展文件系统 中对其进行更详细的描述
当两个新的文件系统首次发布时,它们提供的功能基本相同。 由于其最小的设计,Xia fs 比 Ext2fs 更稳定。 随着文件系统的更广泛使用,Ext2fs 中的错误得到了修复,并且集成了许多改进和新功能。 Ext2fs 现在非常稳定,并且已成为事实上的标准 Linux 文件系统。
下表包含不同文件系统提供的功能的摘要
| Minix FS | Ext FS | Ext2 FS | Xia FS | |
|---|---|---|---|---|
| 最大 FS 大小 | 64 MB | 2 GB | 4 TB | 2 GB |
| 最大文件大小 | 64 MB | 2 GB | 2 GB | 64 MB |
| 最大文件名 | 16/30 c | 255 c | 255 c | 248 c |
| 3 次时间戳支持 | 否 | 否 | 是 | 是 |
| 可扩展 | 否 | 否 | 是 | 否 |
| 可变块大小 | 否 | 否 | 是 | 否 |
| 维护 | 是 | 否 | 是 | ? |
每个 Linux 文件系统都实现了一组源自 Unix 操作系统的基本通用概念 [Bach 1986] 文件由 inode 表示,目录只是包含条目列表的文件,并且可以通过请求特殊文件上的 I/O 来访问设备。
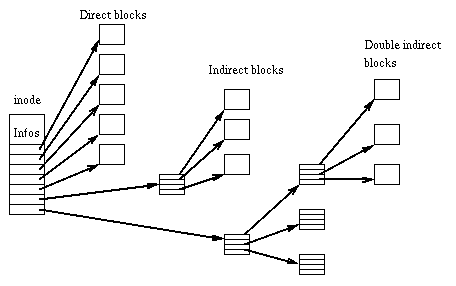
每个文件都由一个结构表示,称为 inode。 每个 inode 包含文件的描述:文件类型、访问权限、所有者、时间戳、大小、指向数据块的指针。 分配给文件的数据块的地址存储在其 inode 中。 当用户请求对文件进行 I/O 操作时,内核代码将当前偏移量转换为块号,使用该数字作为块地址表中的索引,并读取或写入物理块。 此图表示 inode 的结构:
目录以分层树状结构组织。 每个目录可以包含文件和子目录。
目录实现为一种特殊类型的文件。 实际上,目录是一个包含条目列表的文件。 每个条目包含一个 inode 号和一个文件名。 当进程使用路径名时,内核代码会在目录中搜索以找到相应的 inode 号。 将名称转换为 inode 号后,inode 将加载到内存中,并供后续请求使用。
此图表示目录: 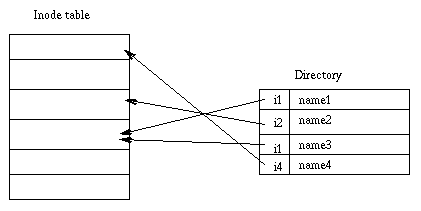
Unix 文件系统实现了链接的概念。 多个名称可以与一个 inode 关联。 inode 包含一个包含与该文件关联的编号的字段。 添加链接只是创建目录条目,其中 inode 号指向 inode,并增加 inode 中的链接计数。 当链接被删除时,即当使用rm命令删除文件名时,内核会减少链接计数,如果此计数变为零,则释放 inode。
这种类型的链接称为硬链接,只能在单个文件系统中使用:不可能创建跨文件系统的硬链接。 此外,硬链接只能指向文件:无法创建目录硬链接以防止目录树中出现循环。
大多数 Unix 文件系统中都存在另一种链接。 符号链接只是包含文件名的文件。 当内核在路径名到 inode 转换期间遇到符号链接时,它会将链接的名称替换为其内容,即目标文件的名称,并重新启动路径名解释。 由于符号链接不指向 inode,因此可以创建跨文件系统的符号链接。 符号链接可以指向任何类型的文件,甚至指向不存在的文件。 符号链接非常有用,因为它们没有与硬链接相关的限制。 但是,它们占用一些磁盘空间,分配给它们的 inode 和数据块,并导致路径名到 inode 转换的开销,因为内核必须在遇到符号链接时重新启动名称解释。
在类 Unix 操作系统中,可以通过特殊文件访问设备。 设备特殊文件不占用文件系统上的任何空间。 它只是设备驱动程序的访问点。
存在两种类型的特殊文件:字符和块特殊文件。 前者允许以字符模式进行 I/O 操作,而后者要求通过缓冲区缓存功能以块模式写入数据。 当对特殊文件发出 I/O 请求时,它将转发到(伪)设备驱动程序。 特殊文件由主编号引用,该编号标识设备类型,以及次要编号,该编号标识单元。
Linux 内核包含一个虚拟文件系统层,该层在作用于文件的系统调用期间使用。 VFS 是一个间接层,它处理面向文件的系统调用,并调用物理文件系统代码中的必要函数来执行 I/O。
这种间接机制在类 Unix 操作系统中经常使用,以简化多种文件系统类型的集成和使用 [Kleiman 1986, Seltzer et al. 1993]。
当进程发出面向文件的系统调用时,内核会调用 VFS 中包含的函数。 此函数处理结构无关的操作,并将调用重定向到物理文件系统代码中包含的函数,该函数负责处理结构相关的操作。 文件系统代码使用缓冲区缓存功能来请求设备上的 I/O。 此方案如下图所示: 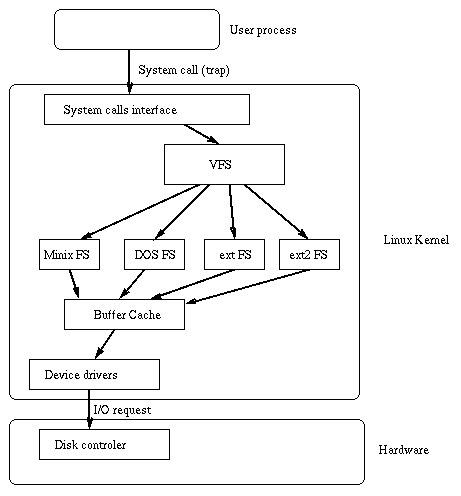
VFS 定义了一组每个文件系统必须实现的函数。 此接口由与三种对象关联的一组操作组成:文件系统、inode 和打开的文件。
VFS 知道内核中支持的文件系统类型。 它使用在内核配置期间定义的表。 此表中的每个条目都描述了一种文件系统类型:它包含文件系统类型的名称以及在挂载操作期间调用的函数的指针。 当要挂载文件系统时,将调用适当的挂载函数。 此函数负责从磁盘读取超级块,初始化其内部变量,并将挂载的文件系统描述符返回给 VFS。 挂载文件系统后,VFS 函数可以使用此描述符来访问物理文件系统例程。
挂载的文件系统描述符包含多种类型的数据:所有文件系统类型通用的信息、物理文件系统内核代码提供的函数的指针以及物理文件系统代码维护的私有数据。 文件系统描述符中包含的函数指针允许 VFS 访问文件系统内部例程。
VFS 使用另外两种类型的描述符:inode 描述符和打开的文件描述符。 每个描述符都包含与正在使用的文件相关的信息以及物理文件系统代码提供的一组操作。 虽然 inode 描述符包含可以用于对任何文件执行操作的函数的指针(例如create, unlink),但文件描述符包含只能对打开的文件执行操作的函数的指针(例如read, write).
第二代扩展文件系统(Ext2fs)的设计和实现是为了解决第一代扩展文件系统中存在的一些问题。我们的目标是提供一个强大的文件系统,它实现了 Unix 文件语义并提供高级功能。
当然,我们希望 Ext2fs 具有卓越的性能。我们还希望提供一个非常健壮的文件系统,以降低在高强度使用中数据丢失的风险。最后,但同样重要的是,Ext2fs 必须包含扩展功能,以允许用户受益于新功能,而无需重新格式化其文件系统。
Ext2fs 支持标准的 Unix 文件类型:常规文件、目录、设备特殊文件和符号链接。
Ext2fs 能够管理在非常大的分区上创建的文件系统。虽然原始内核代码将最大文件系统大小限制为 2 GB,但 VFS 层最近的工作已将此限制提高到 4 TB。因此,现在可以使用大磁盘而无需创建多个分区。
Ext2fs 提供长文件名。它使用可变长度目录条目。最大文件名大小为 255 个字符。如果需要,此限制可以扩展到 1012。
Ext2fs 为超级用户保留了一些块(root)。通常,保留 5% 的块。这允许管理员轻松地从用户进程填满文件系统的情况中恢复。
除了标准的 Unix 功能外,Ext2fs 还支持一些通常在 Unix 文件系统中不存在的扩展功能。
文件属性允许用户在处理一组文件时修改内核行为。可以在文件或目录上设置属性。在后一种情况下,在目录中创建的新文件将继承这些属性。
可以在挂载时选择 BSD 或 System V Release 4 语义。挂载选项允许管理员选择文件创建语义。在以 BSD 语义挂载的文件系统上,使用与其父目录相同的组 ID 创建文件。System V 语义稍微复杂一些:如果目录设置了 setgid 位,则新文件继承目录的组 ID,子目录继承组 ID 和 setgid 位;在另一种情况下,使用调用进程的主组 ID 创建文件和子目录。
类似于 BSD 的同步更新可以在 Ext2fs 中使用。挂载选项允许管理员请求在修改元数据(inode、位图块、间接块和目录块)时,将其同步写入磁盘。这对于保持严格的元数据一致性可能很有用,但会导致性能下降。实际上,此功能通常不使用,因为除了与使用元数据同步更新相关的性能损失之外,它还可能导致用户数据损坏,而文件系统检查器不会标记该损坏。
Ext2fs 允许管理员在创建文件系统时选择逻辑块大小。块大小通常可以为 1024、2048 和 4096 字节。使用大块大小可以加快 I/O 速度,因为访问文件所需的 I/O 请求更少,因此磁盘磁头寻道更少。另一方面,大块会浪费更多磁盘空间:平均而言,分配给文件的最后一个块仅半满,因此随着块变大,每个文件的最后一个块浪费的空间更多。此外,Ext2 文件系统的大部分较大块大小的优势都通过其预分配技术获得(请参阅性能优化部分。
Ext2fs 实现了快速符号链接。快速符号链接不使用文件系统上的任何数据块。目标名称不存储在数据块中,而是存储在 inode 本身中。此策略可以节省一些磁盘空间(无需分配数据块),并加快链接操作(访问此类链接时无需读取数据块)。当然,inode 中可用的空间有限,因此并非每个链接都可以实现为快速符号链接。快速符号链接中目标名称的最大大小为 60 个字符。我们计划在不久的将来将此方案扩展到小文件。
Ext2fs 跟踪文件系统状态。内核代码使用超级块中的一个特殊字段来指示文件系统的状态。当文件系统以读/写模式挂载时,其状态设置为“Not Clean”。当它卸载或以只读模式重新挂载时,其状态将重置为“Clean”。在启动时,文件系统检查器使用此信息来决定是否必须检查文件系统。内核代码还会在此字段中记录错误。当内核代码检测到不一致时,文件系统标记为“Erroneous”。文件系统检查器会测试这一点,以强制检查文件系统,而不管其表面上的清洁状态如何。
始终跳过文件系统检查有时可能很危险,因此 Ext2fs 提供了两种方法来定期强制检查。超级块中维护了一个挂载计数器。每次文件系统以读/写模式挂载时,此计数器都会递增。当它达到最大值(也记录在超级块中)时,即使文件系统“Clean”,文件系统检查器也会强制执行检查。上次检查时间和最大检查间隔也保存在超级块中。这两个字段允许管理员请求定期检查。当达到最大检查间隔时,检查器会忽略文件系统状态并强制执行文件系统检查。Ext2fs 提供了调整文件系统行为的工具。该tune2fs程序可用于修改
挂载选项也可用于更改内核错误行为。
一个属性允许用户请求对文件进行安全删除。删除此类文件时,随机数据会写入先前分配给该文件的磁盘块。这可以防止恶意人员通过使用磁盘编辑器来访问文件的先前内容。
最后,最近已将受 4.4 BSD 文件系统启发的新类型文件添加到 Ext2fs。不可变文件只能读取:没有人可以写入或删除它们。这可用于保护敏感的配置文件。只能以写入模式打开仅附加文件,但数据始终附加到文件的末尾。与不可变文件一样,它们无法删除或重命名。这对于只能增长的日志文件尤其有用。
Ext2 文件系统的物理结构受到了 BSD 文件系统 [McKusick et al. 1984]布局的强烈影响。文件系统由块组组成。块组类似于 BSD FFS 的柱面组。但是,块组与磁盘上块的物理布局无关,因为现代驱动器往往针对顺序访问进行了优化,并将它们的物理几何结构隐藏到操作系统。
文件系统的物理结构在此表中表示
| 引导扇区 扇区 |
块 组 1 |
块 组 2 |
... ... |
块 组 N |
每个块组包含关键文件系统控制信息(超级块和文件系统描述符)的冗余副本,并且还包含文件系统的一部分(块位图、inode 位图、inode 表的一部分和数据块)。块组的结构在此表中表示
| 超级块 块 |
文件系统 描述符 |
块 位图 |
Inode 位图 |
Inode 表 |
数据 块 |
使用块组在可靠性方面是一个很大的胜利:由于控制结构在每个块组中复制,因此很容易从超级块已损坏的文件系统中恢复。此结构还有助于获得良好的性能:通过减少 inode 表和数据块之间的距离,可以减少文件 I/O 期间的磁盘磁头寻道。
在 Ext2fs 中,目录被管理为可变长度条目的链接列表。每个条目都包含 inode 编号、条目长度、文件名及其长度。通过使用可变长度条目,可以实现长文件名,而不会在目录中浪费磁盘空间。目录条目的结构如下表所示
| inode 编号 | 条目长度 | 名称长度 | 文件名 |
例如,下表表示包含三个文件的目录的结构file1, long_file_name和f2:
| i1 | 16 | 05 | file1 |
| i2 | 40 | 14 | long_file_name |
| i3 | 12 | 02 | f2 |
Ext2fs 内核代码包含许多性能优化,这些优化往往可以提高读取和写入文件时的 I/O 速度。
Ext2fs 通过执行预读来利用缓冲区缓存管理:当必须读取一个块时,内核代码会请求对几个连续块执行 I/O。通过这种方式,它试图确保要读取的下一个块已经加载到缓冲区缓存中。预读通常在文件上的顺序读取期间执行,Ext2fs 将它们扩展到目录读取,无论是显式读取(readdir(2)调用)或隐式读取(namei内核目录查找)。
Ext2fs 还包含许多分配优化。块组用于将相关 inode 和数据聚集在一起:内核代码始终尝试将文件的数据块分配到与其 inode 相同的组中。这旨在减少内核读取 inode 及其数据块时进行的磁盘磁头寻道。
将数据写入文件时,Ext2fs 在分配新块时预先分配最多 8 个相邻块。即使在非常满的文件系统上,预分配命中率也约为 75%。这种预分配实现了在重负载下的良好写入性能。它还允许将连续的块分配给文件,从而加快了将来的顺序读取。
这两个分配优化产生非常好的局部性
为了允许用户模式程序操作 Ext2 文件系统的控制结构,开发了 libext2fs 库。该库提供了一些例程,可用于通过直接通过物理设备访问文件系统来检查和修改 Ext2 文件系统的数据。
Ext2fs 库的设计旨在通过使用软件抽象技术来实现最大的代码重用。例如,提供了几个不同的迭代器。程序可以简单地传入一个函数给ext2fs_block_interate(),对于 inode 中的每个块都会调用该函数。另一个迭代器函数允许为目录中的每个文件调用用户提供的函数。
许多 Ext2fs 实用程序(mke2fs, e2fsck, tune2fs, dumpe2fs和debugfs)使用 Ext2fs 库。这大大简化了这些实用程序的维护,因为反映 Ext2 文件系统格式中新功能的任何更改只需在一个地方进行——在 Ext2fs 库中。这种代码重用还导致更小的二进制文件,因为 Ext2fs 库可以构建为共享库映像。
由于 Ext2fs 库的接口非常抽象和通用,因此可以非常容易地编写需要直接访问 Ext2fs 文件系统的新程序。例如,在移植 4.4BSD dump 和 restore 备份实用程序期间使用了 Ext2fs 库。只需进行极少的更改即可使这些工具适应 Linux:只需将一些文件系统相关函数替换为对 Ext2fs 库的调用即可。
Ext2fs 库提供对几种操作类型的访问。第一类是面向文件系统的操作。程序可以打开和关闭文件系统,读取和写入位图,并在磁盘上创建新的文件系统。还可以使用函数来操作文件系统的坏块列表。
第二类操作影响目录。 Ext2fs 库的调用者可以创建和扩展目录,以及添加和删除目录条目。还提供了函数来将路径名解析为 inode 编号,以及根据 inode 编号确定 inode 的路径名。
最后一类操作是面向 inode 的。可以扫描 inode 表,读取和写入 inode,并扫描 inode 中的所有块。还提供了分配和释放例程,允许用户模式程序分配和释放块和 inode。
已经为 Ext2fs 开发了强大的管理工具。这些实用程序用于创建、修改和纠正 Ext2 文件系统中的任何不一致之处。`mke2fs`程序用于初始化分区以包含空的 Ext2 文件系统。
`tune2fs`程序可用于修改文件系统参数。正如 “高级”Ext2fs 功能 部分所解释的那样,它可以更改错误行为、最大挂载计数、最大检查间隔以及为超级用户保留的逻辑块数量。
最有趣的工具可能是文件系统检查器。E2fsck旨在修复系统在非正常关机后出现的文件系统不一致问题。`e2fsck`的原始版本基于 Linus Torvald 的 Minix 文件系统 fsck 程序。但是,当前版本的`e2fsck`是使用 Ext2fs 库从头开始重写的,速度更快,并且可以纠正比原始版本更多的文件系统不一致问题。
`e2fsck`程序旨在尽可能快地运行。由于文件系统检查器往往受磁盘限制,因此通过优化`e2fsck`使用的算法来实现这一点,这样就不会重复从磁盘访问文件系统结构。此外,inode 和目录的检查顺序按块号排序,以减少磁盘寻道的时间。其中许多想法最初由 [Bina and Emrath 1989] 提出,但此后已由作者进一步完善。
在第 1 阶段,`e2fsck`迭代文件系统中的所有 inode,并对每个 inode 作为文件系统中的未连接对象执行检查。也就是说,这些检查不需要与其他文件系统对象进行任何交叉检查。此类检查的示例包括确保文件模式合法,以及 inode 中的所有块都是有效的块号。在第 1 阶段,将编译指示哪些块和 inode 正在使用的位图。
如果`e2fsck`注意到多个 inode 声明的数据块,它会调用第 1B 到 1D 阶段来解决这些冲突,方法是克隆共享块,以便每个 inode 都有其自己的共享块副本,或者通过释放一个或多个 inode。
第 1 阶段执行时间最长,因为必须将所有 inode 读入内存并进行检查。为了减少将来阶段所需的 I/O 时间,关键文件系统信息会缓存在内存中。这种技术最重要的例子是文件系统上所有目录块在磁盘上的位置。这避免了在第 2 阶段重新读取目录 inode 结构以获取此信息的需求。
第 2 阶段将目录作为未连接的对象进行检查。由于目录条目不跨越磁盘块,因此可以单独检查每个目录块,而无需参考其他目录块。这允许`e2fsck`按块号对所有目录块进行排序,并按升序检查目录块,从而减少磁盘寻道时间。检查目录块以确保目录条目有效,并包含对正在使用的 inode 编号的引用(由第 1 阶段确定)。
对于每个目录 inode 中的第一个目录块,将检查 `.` 和 `..` 条目以确保它们存在,并且 `.` 条目的 inode 编号与当前目录匹配。(`..` 条目的 inode 编号要等到第 3 阶段才会检查。)
第 2 阶段还缓存有关链接每个目录的父目录的信息。(如果一个目录被多个目录引用,则该目录的第二个引用将被视为非法硬链接,并将其删除)。
值得注意的是,在第 2 阶段结束时,`e2fsck`需要执行的几乎所有磁盘 I/O 都已完成。第 3、4 和 5 阶段所需的信息都缓存在内存中;因此,`e2fsck`的其余阶段主要受 CPU 限制,并且占`e2fsck.
`总运行时间的不到 5-10%。E2fsck在第 3 阶段,检查目录的连通性。/lost+found目录。
在第 4 阶段,`e2fsck`通过迭代所有 inode 并将链接计数(在第 1 阶段缓存)与在第 2 和 3 阶段计算的内部计数器进行比较,来检查所有 inode 的引用计数。任何未删除的链接计数为零的文件也将链接到`/lost+found在此阶段期间的目录。
最后,在第 5 阶段,`e2fsck`检查文件系统摘要信息的有效性。它将之前阶段构建的块和 inode 位图与文件系统上的实际位图进行比较,并在必要时更正磁盘上的副本。
文件系统调试器是另一个有用的工具。Debugfs是一个强大的程序,可用于检查和更改文件系统的状态。基本上,它提供了一个 Ext2fs 库的交互式界面:用户键入的命令会转换为对库例程的调用。
Debugfs`可用于检查文件系统的内部结构,手动修复损坏的文件系统,或为`e2fsck`创建测试用例。不幸的是,如果人们不知道自己在做什么,这个程序可能会很危险;使用此工具很容易破坏文件系统。因此,`debugfs`默认情况下以只读访问方式打开文件系统。用户必须显式指定`-w标志才能使用`debugfs`以读/写访问方式打开文件系统。
我们已经运行了基准测试来测量文件系统的性能。基准测试是在一台基于 i486DX2 处理器的中端 PC 上进行的,使用 16 MB 内存和两个 420 MB IDE 磁盘。测试是在 Ext2 fs 和 Xia fs (Linux 1.1.62) 以及异步和同步模式下的 BSD Fast 文件系统 (FreeBSD 2.0 Alpha--基于 4.4BSD Lite 发行版) 上运行的。
我们已经运行了两个不同的基准测试。Bonnie 基准测试测试大文件上的 I/O 速度--在测试期间,文件大小设置为 60 MB。它使用基于字符的 I/O 将数据写入文件,重写整个文件的内容,使用基于块的 I/O 写入数据,使用字符 I/O 和块 I/O 读取文件,并查找文件。Andrew 基准测试是在 Carneggie Mellon 大学开发的,并在加州大学伯克利分校用于对 BSD FFS 和 LFS 进行基准测试。它分五个阶段运行:它创建一个目录层次结构,复制数据,递归检查每个文件的状态,检查每个文件的每个字节,并编译几个文件。
Bonnie 基准测试的结果显示在此表中
| 字符写入 (KB/s) |
块写入 (KB/s) |
重写 (KB/s) |
字符读取 (KB/s) |
块读取 (KB/s) | |
|---|---|---|---|---|---|
| BSD 异步 | 710 | 684 | 401 | 721 | 888 |
| BSD 同步 | 699 | 677 | 400 | 710 | 878 |
| Ext2 fs | 452 | 1237 | 536 | 397 | 1033 |
| Xia fs | 440 | 704 | 380 | 366 | 895 |
在面向块的 I/O 中,结果非常好:Ext2 fs 优于其他文件系统。这显然是分配例程中包含的优化的好处。写入速度很快,因为数据以集群模式写入。读取速度很快,因为已将连续块分配给文件。因此,两次读取之间没有磁头寻道,并且可以充分利用预读优化。
另一方面,在面向字符的 I/O 中,FreeBSD 操作系统中的性能更好。这可能是因为 FreeBSD 和 Linux 在各自的 C 库中没有使用相同的 stdio 例程。FreeBSD 似乎具有更优化的字符 I/O 库,并且其性能更好。
| P1 创建 (ms) |
P2 复制 (ms) |
P3 状态 (ms) |
P4 Grep (ms) |
P5 编译 (ms) |
|
|---|---|---|---|---|---|
| BSD 异步 | 2203 | 7391 | 6319 | 17466 | 75314 |
| BSD 同步 | 2330 | 7732 | 6317 | 17499 | 75681 |
| Ext2 fs | 790 | 4791 | 7235 | 11685 | 63210 |
| Xia fs | 934 | 5402 | 8400 | 12912 | 66997 |
前两个阶段的结果表明 Linux 受益于其异步元数据 I/O。在第 1 和第 2 阶段,创建了目录和文件,并且 BSD 同步写入 inode 和目录条目。但是,有一个异常:即使在异步模式下,BSD 下的性能也很差。我们怀疑 FreeBSD 下的异步支持尚未完全实现。
在第 3 阶段,Linux 和 BSD 的时间非常相似。与六个月前运行的相同基准测试相比,这是一个很大的进步。虽然 BSD 曾经在这项测试中以 3 倍的优势胜过 Linux,但在 VFS 中添加文件名缓存已解决了此性能问题。
在第 4 和第 5 阶段,Linux 比 FreeBSD 快,主要是因为它使用了统一的缓冲区缓存管理。缓冲区缓存空间可以在需要时增长,并且比 FreeBSD 中的缓冲区缓存使用更多的内存,FreeBSD 使用固定大小的缓冲区缓存。Ext2fs 和 Xiafs 结果的比较表明,Ext2fs 中包含的优化非常有用:Ext2fs 和 Xiafs 之间的性能增益约为 5-10%。
第二扩展文件系统可能是 Linux 社区中使用最广泛的文件系统。它提供了标准的 Unix 文件语义和高级功能。此外,由于内核代码中包含的优化,它既健壮又提供出色的性能。
由于 Ext2fs 在设计时考虑到了演进,因此它包含可用于添加新功能的挂钩。有些人正在研究当前文件系统的扩展:符合 Posix 语义的访问控制列表 [IEEE 1992],取消删除和实时文件压缩。
Ext2fs 最初开发并集成到 Linux 内核中,现在正积极地被移植到其他操作系统。一个运行在 GNU Hurd 之上的 Ext2fs 服务器已经被实现。人们也在致力于在 LITES 服务器上移植 Ext2fs,LITES 服务器运行在 Mach 微内核之上 [Accetta et al. 1986],以及 VSTa 操作系统中。最后但同样重要的是,Ext2fs 是 Masix 操作系统 [Card et al. 1993] 的重要组成部分,该操作系统目前正由本文作者之一开发中。
Ext2fs 内核代码和工具主要由本文作者编写。其他一些人也通过提出新功能或发送补丁为 Ext2fs 的开发做出了贡献。我们感谢这些贡献者的帮助。
[Accetta et al. 1986] M. Accetta, R. Baron, W. Bolosky, D. Golub, R. Rashid, A. Tevanian, and M. Young. Mach: A New Kernel Foundation For UNIX Development. In Proceedings of the USENIX 1986 Summer Conference, June 1986.
[Bach 1986] M. Bach. The Design of the UNIX Operating System. Prentice Hall, 1986.
[Bina and Emrath 1989] E. Bina and P. Emrath. A Faster fsck for BSD Unix. In Proceedings of the USENIX Winter Conference, January 1989.
[Card et al. 1993] R. Card, E. Commelin, S. Dayras, and F. Mével. The MASIX Multi-Server Operating System. In OSF Workshop on Microkernel Technology for Distributed Systems, June 1993.
[IEEE 1992] SECURITY INTERFACE for the Portable Operating System Interface for Computer Environments - Draft 13. Institute of Electrical and Electronics Engineers, Inc, 1992.
[Kleiman 1986] S. Kleiman. Vnodes: An Architecture for Multiple File System Types in Sun UNIX. In Proceedings of the Summer USENIX Conference, pages 260--269, June 1986.
[McKusick et al. 1984] M. McKusick, W. Joy, S. Leffler, and R. Fabry. A Fast File System for UNIX. ACM Transactions on Computer Systems, 2(3):181--197, August 1984.
[Seltzer et al. 1993] M. Seltzer, K. Bostic, M. McKusick, and C. Staelin. An Implementation of a Log-Structured File System for UNIX. In Proceedings of the USENIX Winter Conference, January 1993.
[Tanenbaum 1987] A. Tanenbaum. Operating Systems: Design and Implementation. Prentice Hall, 1987.